Основы реляционных баз данных
Теория: Условия (WHERE)
Обычно данных в базе много, и мы хотим работать только с их частью, а не всеми данными сразу. Например, нам нужно посмотреть данные только тех пользователей, которые зарегистрировались вчера. Для выборки части данных из базы используются условия. В этом уроке мы научимся строить подобные условия при выполнении запросов в базу данных с помощью WHERE.
WHERE
Самое простое условие — указать прямое соответствие. Например, выборка по идентификатору:
Первый запрос выше звучит так: выбрать всех пользователей, у которых идентификатор равен трем. Такая формулировка звучит странно, так как если мы выбираем по идентификатору, то и запись должна быть одна. С точки зрения семантики идентификатора она будет одна, но в реляционной базе данных результатом любой операции над множеством является множество.
В том случае, если ничего не найдено, возвращается не пустота, а пустое множество. Если же в базе есть пользователь с указанным идентификатором, то вернется множество, которое содержит один элемент — найденного пользователя.
Если нужно получить все записи, кроме тех, у которых есть определенное значение, то нужно =, заменить на !=:
Сравнение с конкретным значением работает для всех типов данных, кроме NULL. Разберем эту ситуацию подробнее.
Проверка на равенство с NULL
У данных типа NULL свой синтаксис:
Равно NULL:
Не равно NULL:
NOT, как и отрицание в языках программирования, может добавляться практически к любому оператору.
Равенство строк
У строк тоже свои особенности. В соответствии со стандартом ANSI SQL, строки в PostgreSQL регистрозависимые — результат зависит от регистра, в котором записан текст. Например, следующие два запроса выбирают разные данные:
По этой причине данные в базе стараются хранить в нормализованном виде — перед добавлением в БД их приводят, например, к нижнему регистру, и то же самое делают при выборках. Классический пример — email. Его нужно хранить только в нижнем регистре.
Другие операции сравнения
Кроме точного соответствия SQL поддерживает и все остальные операции сравнения:
>— больше<— меньше!=— не равно>=— больше либо равно, не меньше<=— меньше либо равно, не больше
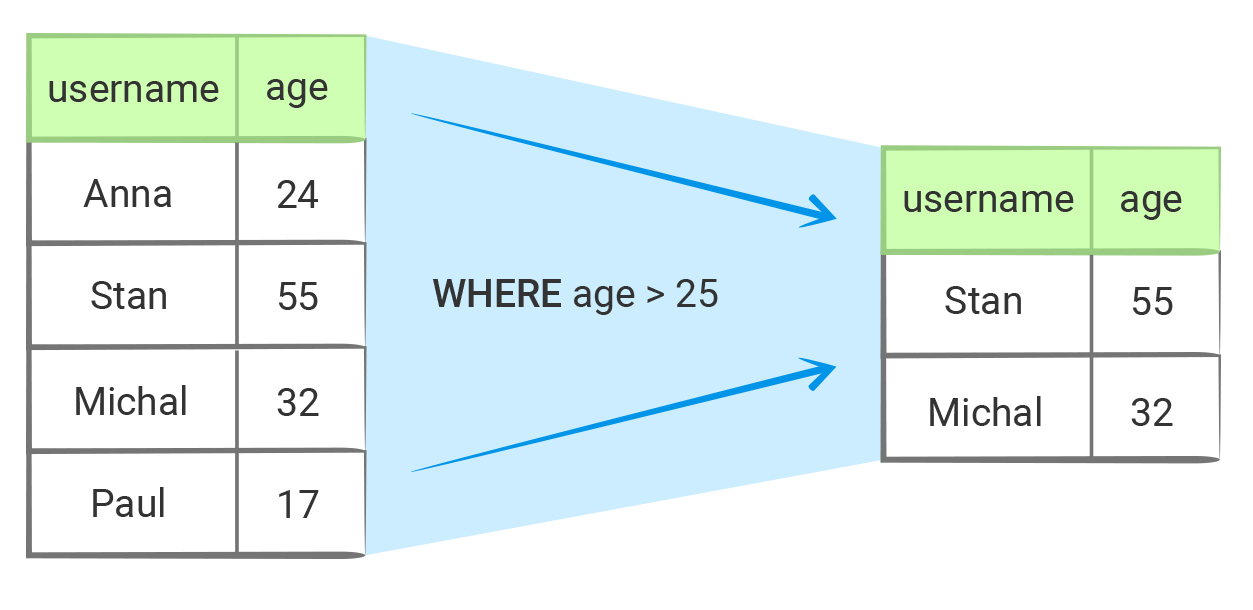
Например, так может выглядеть запрос на сравнение:
Здесь мы выбираем всех пользователей, созданных до 2018-10-05.
Логические операторы
Все операции можно объединять в цепочки, если использовать логические операторы OR и AND:
Здесь мы выбираем пользователей, которые зарегистрировались между 2018-01-01 и 2018-10-05.
Как и в случае с языками программирования, здесь действуют те же приоритеты. Чтобы не создавать неоднозначностей, в сложных ситуациях используются круглые скобки:
BETWEEN
Для условий с проверкой диапазона SQL поддерживает особый формат BETWEEN. По сути, это сокращенная версия для двух условий соединенных через AND:
Здесь мы выбираем пользователей, которые зарегистрировались между 2018-01-01 и 2018-10-05, включая эти даты. BETWEEN всегда учитывает границы диапазона.
IN
В некоторых ситуациях требуется найти не диапазон строк, а строки, в которых поле соответствует одному значению из набора. Предположим, что мы хотим выполнить один запрос и найти пользователей с идентификаторами 1, 2 или 5. Для этого используют OR:
Если понадобится найти десяток совпадений, можно использовать другое решение — IN:
Если нужно исключить определенные записи, достаточно добавить NOT:
LIKE
Иногда нужно искать по частичному совпадению: например, проверить, что строка начинается или заканчивается с определенной последовательности символов. Допустим, мы хотим посмотреть пользователей, имя которых начинается с буквы A:
% — специальный заполнитель, который означает «все что угодно». Если его поставить в конце, то поиск выполняется по совпадению в начале фразы, если в начале — то по совпадению с концом, а если по краям — то проверяется совпадение внутри текста. Совпадение в конце может понадобиться, чтобы анализировать пользователей, которые регистрировались с определенного почтового домена:
Здесь мы выбираем всех пользователей, электронная почта которых заканчивается на hotmail.com.
Обратите внимание на то, что этот поиск регистрозависимый. Если вы хотите искать без учета регистра, то используйте ILIKE.
Выводы
В этом уроке мы разобрали, как работать с выборками части данных по условию. Теперь вы умеете строить условия при выполнении запросов в базу данных с помощью WHERE и таким образом сможете работать только с частью данных, а не со всей базой сразу.