Ruby: Составные данные
Теория: Барьеры абстракции
Во время разработки нашей библиотеки для работы с графическими примитивами мы двигались от более простого и более низкого уровня (создания простых примитивов, например, точки) к более высокому, то есть повышали так называемый уровень абстракции. В этом нам помогали барьеры абстракции.
Идея абстракции данных состоит в том, чтобы определить для каждого типа объектов данных набор базовых операций, через которые будут выражаться все действия с объектами этого типа. Если представить эту идею графически, то мы можем увидеть следующую картину:
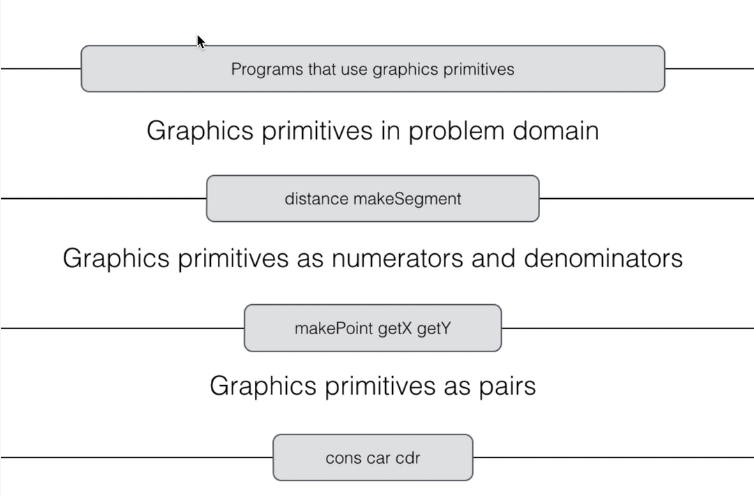
На самом верхнем уровне находятся программы, которые используют наши графические примитивы и делают это на максимально высоком уровне. Далее мы определяем графические примитивы уже в терминах функций для доступа к более низкому уровню. Например, у нас есть функции get_distance и make_segment, которые работают с отрезками и обращаются к точкам. А точки, в свою очередь, построены на парах. При этом любой части программы на любом уровне всё равно, как устроены пары, от этого ничего не должно поменяться. При этом, конечно, абстракция может "протекать". Это означает, что более высоким уровням приходится напрямую обращаться к более низким, минуя расположенные между ними уровни. Например, программа пытается пользоваться точками как парами. В таких случаях принято считать, что абстракция не очень хороша, и это приводит к проблемам в дальнейшем при модификации программы.
Барьеры абстракции в современной литературе часто именуют другим термином — принцип одного уровня абстракции. Это означает, что работая в одной предметной области на определенном срезе, оперируют объектами только этого среза, избегая объектов, к нему не относящихся.
Итак, какие же преимущества нам даёт такой подход, когда мы строим всё независимыми слоями или ярусами? Во-первых, нам проще рассуждать о программе, потому что на том уровне абстракции, на котором мы работаем, мы оперируем небольшим ограниченным набором сущностей, которые к тому же соответствуют одному уровню мышления о них. Во-вторых, нам проще комбинировать разные части программы, склеивая их через определенные нами интерфейсы для получения нового более сложного поведения. И, наконец, нам гораздо проще поддерживать и изменять наши программы, потому что код, отделенный барьером абстракции на определенном уровне, не зависит от реализации более низких уровней. Это позволяет в любой момент переписывать отдельные уровни, например, для большей производительности.
Когда мы говорили о данных, мы говорили о том, что они реализуются некоторым интерфейсом, набором конструкторов и селекторов. Но, строго говоря, этого определения недостаточно, потому что структура данных реализуется не любым набором конструкторов и селекторов, они должны быть связаны между собой определённым образом. Формально можно сказать так: для любых x и y, если p есть точка make_point(x, y), (get_x(p), get_y(p)) является точкой (x, y). Такое определение оказывается крайне простым, если просто подумать о нём логически: положенное в конструктор должно быть получено селекторами. Если это правило выполняется, то можно сказать, что мы имеем некоторые данные, с которыми мы можем работать, и они будут вести себя предсказуемым образом. По сути, у нас есть правило (может быть даже не одно), которое описывает связи между данными.

