'%3e%3cpath%20d='M13.1407%204.34375L9.12548%205.80383L6.93536%209.45402L4.38023%205.80383L0.365019%204.34375L5.11027%2011.6441L0%2019.6745H2.92015L6.57034%2013.8342L10.5856%2019.6745H13.5057L8.39544%2011.6441L13.1407%204.34375ZM17.1559%2012.0091C17.5209%2010.5491%2018.981%209.089%2020.8061%209.089C22.6312%209.089%2024.0913%2010.5491%2024.4563%2012.0091H17.1559ZM20.8061%206.89888C17.1559%206.89888%2014.2357%209.81904%2014.2357%2013.4692C14.2357%2017.4844%2017.1559%2020.0396%2020.8061%2020.0396C23.3612%2020.0396%2025.9164%2018.5795%2027.0114%2016.0244H24.0913C23.7262%2017.1194%2022.2662%2017.8495%2020.8061%2017.8495C18.616%2017.8495%2017.1559%2016.3894%2016.7909%2014.1993H27.0114C27.3764%2010.1841%2024.8213%206.89888%2020.8061%206.89888ZM40.8821%207.2639H37.597L32.1217%2012.7392V7.2639H29.5665V19.6745H32.1217V13.8342L38.327%2019.6745H41.6122L35.0418%2013.1042L40.8821%207.2639ZM48.5475%209.45402C50.0076%209.45402%2051.4677%2010.1841%2051.8327%2011.6441H54.3878C54.0228%208.72398%2051.4677%206.89888%2048.5475%206.89888C44.5323%206.89888%2041.9772%209.81904%2041.9772%2013.4692C41.9772%2017.1194%2044.5323%2020.0396%2048.1825%2020.0396C51.1027%2020.0396%2054.0228%2018.2145%2054.3878%2015.2943H51.8327C51.4677%2016.7544%2050.0076%2017.4844%2048.1825%2017.4844C45.9924%2017.4844%2044.5323%2016.0244%2044.5323%2013.4692C44.5323%2011.2791%2045.9924%209.45402%2048.5475%209.45402ZM58.403%2014.5643C58.038%2017.1194%2057.673%2017.4844%2056.2129%2017.4844H55.4829V20.0396H56.943C58.7681%2020.0396%2060.2281%2018.5795%2060.9582%2014.9293L61.6882%209.81904H66.0684V19.6745H68.6236V7.2639H59.4981L58.403%2014.5643ZM73.7338%2012.0091C74.4639%2010.5491%2075.5589%209.089%2077.7491%209.089C79.5742%209.089%2080.6692%2010.5491%2081.0342%2012.0091H73.7338ZM77.7491%206.89888C73.7338%206.89888%2071.1787%209.81904%2071.1787%2013.4692C71.1787%2017.4844%2073.7338%2020.0396%2077.7491%2020.0396C80.3042%2020.0396%2082.8593%2018.5795%2083.5894%2016.0244H81.0342C80.3042%2017.1194%2079.2091%2017.8495%2077.7491%2017.8495C75.5589%2017.8495%2074.0989%2016.3894%2073.7338%2014.1993H83.9544C84.3194%2010.1841%2081.7643%206.89888%2077.7491%206.89888ZM91.9848%207.2639H85.4145V9.81904H89.4297V19.6745H91.9848V9.81904H96V7.2639H91.9848Z'%20fill='%231D1D1B'%20/%3e%3cpath%20d='M13.1429%202.51607L6.93753%20-0.0390625L0.367188%202.51607L6.93753%204.70618L13.1429%202.51607Z'%20fill='%23136EF6'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_139_18360'%3e%3crect%20width='96'%20height='24'%20fill='%23fff'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Статистическая значимость
Теория: Постановка задачи
Предположим, что нам нужно сравнить два дизайна интерфейса с точки зрения выручки.
Решим эту задачу на примере интерфейсов A и B. Для этого нужно:
- Собрать данные по выручке от каждого пользователя
- Посчитать сумму выручки от пользователей каждого интерфейса
- Сравнить выручку от каждого интерфейса
- Построить для каждого интерфейса гистограммы распределения выручки по децилям
- Сравнить полученные гистограммы
- Посчитать
Ma,Mb,Da,Db– математическое ожидание и дисперсию - Сравнить эти показатели
Попробуем разобраться, отличаются ли пользователи из групп A и B статистически. Гипотеза H₀ — нет различий, гипотеза H₁ — есть различия.
Вероятностное распределение
Вероятностное распределение — это идеализированное частотное распределение.
В свою очередь, частотное распределение описывает конкретную выборку или набор данных. Оно отражает, сколько раз каждое значение переменной может встретиться в наборе данных. Другими словами, по этому показателю мы определяем вероятность появления того или иного значения.
Вероятность обозначается числом от 0 до 1:
0означает, что событие невозможно1означает, что событие точно произойдет
Чем выше вероятность для какого-то значения, тем чаще оно встречается в выборке. Теоретически, так мы должны узнать частоту появления в бесконечно большой выборке. Но в реальности бесконечно большие выборки невозможны, поэтому распределения вероятностей являются теоретическими. Это идеализированные версии частотных распределений, описывающие совокупность, из которой мы взяли выборку.
Распределения вероятностей описывают совокупности реальных переменных, помогают проверять гипотезы и определять P-значения.
Нормальное распределение
Непрерывное распределение вероятностей — это распределение вероятностей непрерывной переменной. Непрерывная переменная может иметь любое значение между своим наименьшим и наибольшим. Поэтому непрерывное распределение вероятностей включает все числа в диапазоне переменной.
Функция плотности вероятности — это математическая функция, описывающая непрерывное распределение вероятностей. Это плотность вероятности каждого значения переменной, которая может быть больше единицы.
В графическом виде функция плотности вероятности — это кривая. Мы можем вычислить площадь под этой кривой и таким образом узнать вероятность того, что значение попадет в определенный интервал. Для расчета площади можно использовать справочные таблицы или программное обеспечение. Площадь под всей кривой всегда равна единице.
Нормальное распределение — это один из примеров непрерывного распределения. Оно описывает данные со значениями, которые становятся менее вероятными по мере удаления от среднего, то есть с колоколообразной функцией плотности вероятности.
Дискретные распределения и таблицы вероятности
Дискретное распределение вероятностей — это распределение вероятностей дискретной переменной. Оно включает в себя только вероятности возможных значений. Другими словами, в него не входят значения, вероятность которых равна нулю. Например, распределение вероятностей бросков игральных костей не включает значение 2,5 или 0, потому что такой результат броска костей невозможен.
Вероятности всех возможных значений в дискретном распределении вероятностей равны единице. Поэтому можно с уверенностью утверждать, что наблюдаемая величина будет иметь одно из возможных значений.
Таблица вероятностей представляет собой дискретное распределение вероятностей переменной. Она состоит из двух столбцов:
- Значения или классовые интервалы
- Вероятности
Рассмотрим таблицу с количеством покупателей за сутки:
Все вероятности в таблице больше нуля и при сумме дают единицу.
Математическое ожидание
Математическое ожидание — понятие в теории вероятностей, означающее средневзвешенное по вероятностям возможных значений значение случайной величины. Так же его называют «среднее значение распределения». Часто его записывают как M(x) или μ. Если взять случайную выборку из распределения, то среднее значение выборки будет примерно равно математическому ожиданию.
Математическое ожидание можно рассчитать несколькими способами:
- Если есть формула, описывающая распределение — например, функция плотности вероятности — оно задается параметром μ
- Если параметра μ нет, то его можно вычислить по другим параметрам с помощью уравнений
- Если есть выборка, то среднее значение выборки приблизительно равно математическому ожиданию — чем больше объем выборки, тем лучше будет оценка
- Если у вас есть таблица вероятностей, то математическое ожидание рассчитывается через умножение вероятности каждого возможного исхода на его вероятность, а затем сложение этих значений
Рассмотрим таблицу вероятностей:
Математическое ожидание составит около 23 покупателей:
Дисперсия
Дисперсия случайной величины — мера разброса значений случайной величины относительно ее математического ожидания. Квадратный корень из дисперсии называют среднеквадратическим отклонением или стандартным отклонением. Его записывают как σ.
Среднеквадратическое отклонение также можно рассчитать несколькими способами:
- Если есть формула, описывающая распределение, то среднеквадратическое отклонение иногда задается параметром σ
- Если параметра σ нет, то его можно рассчитать по другим параметрам с помощью формул, специфичных для каждого распределения
- Если у вас есть выборка, то среднеквадратическое отклонение выборки будет связана с оценкой среднеквадратического отклонения распределения вероятностей совокупности — чем больше объем выборки, тем лучше будет оценка
Если у вас есть таблица вероятностей, то можно рассчитать среднеквадратическое отклонение, выполнив такие шаги:
- Вычислить отклонение каждого значения от ожидаемого
- Возвести его в квадрат
- Умножить на вероятность
- Просуммировать значения
- Взять их квадратный корень
Рассмотрим таблицу вероятностей:
Среднеквадратическое отклонение подсчитывается так:
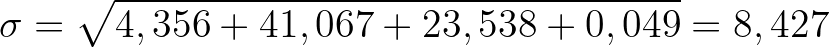
Практика
Дано: Есть два типа интерфейса, A и B.
Вопрос: Как определить, какой нравится людям больше? Предположим, что пользователи одинаковые, и мы показали A для 50% пользователей, и B — для оставшихся 50%.
Задача: выбрать и обосновать выбор интерфейса для работы.
Подход к решению задачи
- Собрать данные по выручке от каждого пользователя, работавших с интерфейсом А и B
- Посчитать сумму выручки от пользователей интерфейса А и B и сравнить
- Построить для каждого интерфейса (A и B) гистограммы распределения выручки (по децилям) и сравнить
- Посчитать Ma, Mb, Da, Db – математическое ожидание и дисперсию и сравнить
Можно ли сказать, что пользователи A и B одинаковые или они статистически значимо отличаются?
Гипотеза H0 - нет различий, гипотеза H1 - есть различия.
Собираем данные
У нас есть таблица, clickstream, в которой есть 4 поля. Это версия продукта А и версия В. У нас есть как раз счет количества совпадений. Соответственно, для версии 1 сумма вероятностей 1. Для версии 2 тоже сумма вероятностей равна 1.
Давайте немного уточним про то, как такие таблицы собирать. Смотрите, у нас скорее всего версия 1, это есть какой-то флажок в большой таблице с данными. На децили мы разделили с помощью знакомой нам оконной функции по суммам покупок среднего. Допустим, дециль 1 это те люди, которые у нас покупали меньше всего, то есть средний чек маленький, единичный чек в принципе маленький и так далее. А последний дециль это категория людей, которые больше всего самые крупные покупки делают. И соответственно, вероятность таких мала, тех кто у нас совсем мало равно как и тех клиентов, которые приходят и делают большие заказы. Потому что это разовые вещи, происходит они очень редко. Большая ч��сть наших клиентов будет при этом в 6 дециле, потому что там наиболее часто встречающиеся наиболее часто повторяющиеся значения.
Посчитаем сумму выручки от пользователей интерфейса А и B
Для этого пишем запрос на таблицу clickstream и группируем по версии.
Ссылка на пример с вычислениями
Итак, версия 1 принесла нам 3135 условных единиц, а версия 2 - 4135 условных единиц. То есть уже посчитав первую метрику, мы можем сделать такой предположительный, не доказанный пока ничем вывод о том, что интерфейс B пока лучше. И как минимум можем сделать уже предположительно тоже, отклонить гипотезу H0 "нет различия", потому что мы эти различия уже видим. Заключаются они в том, что сумма выручки соответственно различается.
Построить для каждого интерфейса гистограммы распределения выручки
Для этого нам нужно опять же по версии и по децилям суммировать категории. Добавляем дополнительную метрику. По сути мы получаем нашу исходную таблицу, потому что там уже и так было.
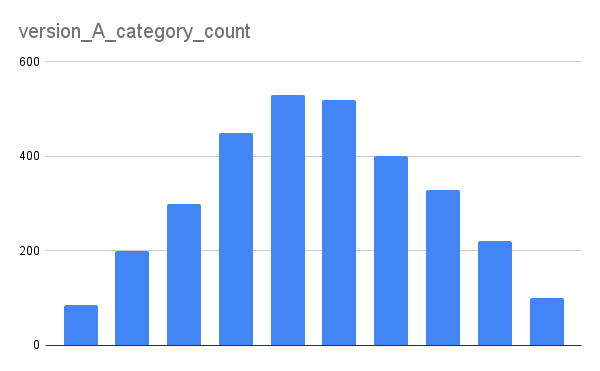
Гистограмма для интерфейса A
Гистограмма для интерфейса B
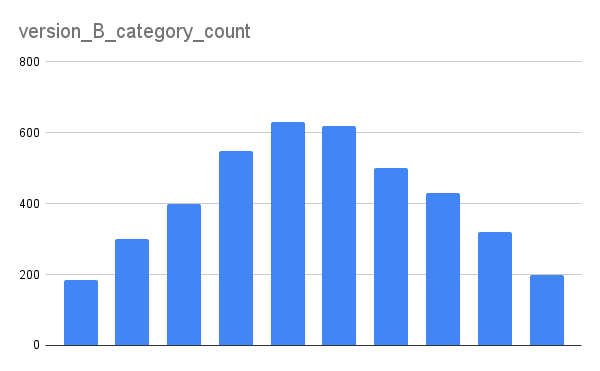
Визуально мы пока лишь можем сделать вывод, кроме того, что распределение нормальное, значит данные, с которыми мы работаем с разными версиями соответствуют требованиям и на них соответственно можно проводить обе тестирования.
Посчитаем математическое ожидание и дисперсию
Давайте еще третьим экспериментом убедимся максимально в том, что у нас действительно гипотеза h1 выигрывает по сравнению с гипотезой h0. Для этого проведем сравнение математического ожидания и среднеквадратичного отклонения.
Ссылка на пример с вычислениями
Последнее, что мы сделали, посчитали долю математического ожидания старого в математическом ожидании нового. То есть от текущее математическое ожидание для 1 версии, поделили на математическое ожидание 2 версии и вычли единицу. То же самое сделали для среднеквадратичного отклонения.
Выводы
На основе пунктов 2, 3 и 4 мы сделали вывод о том, что у нас гипотеза H0 не принимается. Различия действительно есть, а это значит, что мы принимаем гипотезу H1. Интерфейс B лучше, по нашим метрикам, поэтому мы его и используем в дальнейшем в работе.



