'%3e%3cpath%20d='M13.1407%204.34375L9.12548%205.80383L6.93536%209.45402L4.38023%205.80383L0.365019%204.34375L5.11027%2011.6441L0%2019.6745H2.92015L6.57034%2013.8342L10.5856%2019.6745H13.5057L8.39544%2011.6441L13.1407%204.34375ZM17.1559%2012.0091C17.5209%2010.5491%2018.981%209.089%2020.8061%209.089C22.6312%209.089%2024.0913%2010.5491%2024.4563%2012.0091H17.1559ZM20.8061%206.89888C17.1559%206.89888%2014.2357%209.81904%2014.2357%2013.4692C14.2357%2017.4844%2017.1559%2020.0396%2020.8061%2020.0396C23.3612%2020.0396%2025.9164%2018.5795%2027.0114%2016.0244H24.0913C23.7262%2017.1194%2022.2662%2017.8495%2020.8061%2017.8495C18.616%2017.8495%2017.1559%2016.3894%2016.7909%2014.1993H27.0114C27.3764%2010.1841%2024.8213%206.89888%2020.8061%206.89888ZM40.8821%207.2639H37.597L32.1217%2012.7392V7.2639H29.5665V19.6745H32.1217V13.8342L38.327%2019.6745H41.6122L35.0418%2013.1042L40.8821%207.2639ZM48.5475%209.45402C50.0076%209.45402%2051.4677%2010.1841%2051.8327%2011.6441H54.3878C54.0228%208.72398%2051.4677%206.89888%2048.5475%206.89888C44.5323%206.89888%2041.9772%209.81904%2041.9772%2013.4692C41.9772%2017.1194%2044.5323%2020.0396%2048.1825%2020.0396C51.1027%2020.0396%2054.0228%2018.2145%2054.3878%2015.2943H51.8327C51.4677%2016.7544%2050.0076%2017.4844%2048.1825%2017.4844C45.9924%2017.4844%2044.5323%2016.0244%2044.5323%2013.4692C44.5323%2011.2791%2045.9924%209.45402%2048.5475%209.45402ZM58.403%2014.5643C58.038%2017.1194%2057.673%2017.4844%2056.2129%2017.4844H55.4829V20.0396H56.943C58.7681%2020.0396%2060.2281%2018.5795%2060.9582%2014.9293L61.6882%209.81904H66.0684V19.6745H68.6236V7.2639H59.4981L58.403%2014.5643ZM73.7338%2012.0091C74.4639%2010.5491%2075.5589%209.089%2077.7491%209.089C79.5742%209.089%2080.6692%2010.5491%2081.0342%2012.0091H73.7338ZM77.7491%206.89888C73.7338%206.89888%2071.1787%209.81904%2071.1787%2013.4692C71.1787%2017.4844%2073.7338%2020.0396%2077.7491%2020.0396C80.3042%2020.0396%2082.8593%2018.5795%2083.5894%2016.0244H81.0342C80.3042%2017.1194%2079.2091%2017.8495%2077.7491%2017.8495C75.5589%2017.8495%2074.0989%2016.3894%2073.7338%2014.1993H83.9544C84.3194%2010.1841%2081.7643%206.89888%2077.7491%206.89888ZM91.9848%207.2639H85.4145V9.81904H89.4297V19.6745H91.9848V9.81904H96V7.2639H91.9848Z'%20fill='%231D1D1B'%20/%3e%3cpath%20d='M13.1429%202.51607L6.93753%20-0.0390625L0.367188%202.51607L6.93753%204.70618L13.1429%202.51607Z'%20fill='%23136EF6'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_139_18360'%3e%3crect%20width='96'%20height='24'%20fill='%23fff'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Статистическая значимость
Теория: Поиск и обоснование гипотез
Гипотеза — предположение о виде распределения и свойствах случайной величины. Гипотезу можно подтвердить или опровергнуть. Чтобы это сделать, мы применяем статистические методы к данным выборки. Эта формальная процедура называется проверкой гипотезы.
Чтобы проверить гипотезу, нужно пройти семь шагов:
- Сформулировать две гипотезы — нулевую и альтернативную (H₀ и H₁)
- Определить уровень значимости отклонения
- Отобрать данные из выборки
- Вычислить значения статистических критериев, отвечающих гипотезе H₀
- Вычислить критические области
- Проверить статистические критерии на предмет попадания в критическую область
- Интерпретировать достигнутый уровень значимости
Pи результаты
Конкретные детали могут различаться, но в любом случае при проверке гипотезы мы всегда следуем какой-то версии этих шагов.
Формулируем гипотезы
Обычно в начале исследования у нас есть первоначальная гипотеза — это предположение, которое мы хотим проверить. Дальше важно сформулировать ее в виде двух отдельных гипотез:
- Нулевая гипотеза — это предположение, что связи между переменными нет.
- Альтернативная гипотеза — это предположение, что связь между переменными есть.
Например, у нас есть два интерфейса — A и B. Представим, что мы хотим проверить, существует ли связь между интерфейсами и кликами. Мы формулируем гипотезу, что интерфейс B привлекательнее интерфейса A. Чтобы проверить эту гипотезу, сформулируем ее так:
- H₀: Интерфейсы A и B не отличаются — между переменными «интерфейс/клики» нет связи.
- H₁: Интерфейс B приносит больше кликов — между переменными есть взаимосвязь.
Определяем уровень значимости отклонения
Далее нужно определить уровень значимости отклонения или уровень риска. В формулах его часто обозначают как P-значение. Часто уровень значимости отклонения для нулевой гипотезы составляет 5%. Попробуем объяснить подробнее:
- Есть риск, что в
5%случаев мы отклоним нулевую гипотезу и ошибемся. На самом деле, связь между переменными будет, поэтому верна альтернативная гипотеза - Верно и обратное — в
95%случаев мы отклоним нулевую гипотезу и будем правы. В реальности связи между переменным не будет, поэтому верна нулевая гипотеза
С уровнем значимости отклонения связано два важных понятия — ошибка первого рода и ложноположительное решение. Оба термина обозначают ситуацию, где мы отклонили гипотезу, которая оказалась верной.
Некоторые исследователи выбирают 1% или 0,1%. Это более строгий уровень значимости отклонения. Выбрав его, мы снижаем шанс попасть в ситуацию, при которой мы зря отклонили верную гипотезу.
Отбираем данные из выборки
Чтобы тестирование было достоверным, важно провести выборку и собрать репрезентативные данные. Если данные не репрезентативны, мы не сможем делать корректные выводы.
Вернемся к примеру с интерфейсами A и B. Чтобы мы достоверно проверили гипотезу, выборка должна состоять из равной доли пользователей интерфейса A и B. Также необходимо определить размер минимальной выборки и длительность нашего тестирования.
Проведение статистического теста
Существуют разные статистические тесты, но все они основаны на сравнении дисперсии двух видов:
- Внутригрупповая — отражает, насколько данные разбросаны внутри категории
- Межгрупповая — отражает, насколько категории отличаются друг от друга
Высокая межгрупповая дисперсия показывает, что группы практически не пересекаются. В таком случае статистический тест покажет низкое P-значение. Это значит, что различия между этими группами возникли неслучайно — между переменными есть связь.
Верно и обратное. Высокая внутригрупповая дисперсия связана с высоким P-значением. Скорее всего, различия между группами обусловлены случайностью — между переменными связи нет.
Выбор статистического теста зависит от типа переменных и уровня изменения собранных данных. Рассмотрим эту мысль на практике. Для этого вернемся к нашему примеру. Далее мы проведем двухвостый t-тест (two-tailed t-test). С его помощью мы проверим, действительно ли интерфейс B лучше A. В итоге мы получим:
- Оценку разницы в среднем количестве кликов
- Значение
P— оно показывает, насколько вероятна разница, если нулевая гипотеза верна
Проверка статистических критериев
Теперь нужно взять результаты статистического теста и на их основании решить, отвергать или не отвергать нулевую гипотезу.
Если в ходе нашего теста мы обнаружили, что P-значение ниже уровня значимости 0,05, то мы отвергаем нулевую гипотезу об отсутствии различий. Другими словами, интерфейсы A и B действительно дают разные результаты — разница в количестве собранных кликов не случайна.
Интерпретация результатов
В конце нашего исследования мы можем кратко описать:
- Исходные данные
- Результаты статистического теста
- Предполагаемое различие между средними значениями групп
- Соответствующее P-значение
Из всей этой информации мы делаем вывод, подтвердилась ли первоначальная гипотеза полученными результатами или нет. Говоря формальным языком, мы можем прийти к двум исходам:
- Не отвергать нулевую гипотезу
- Отвергнуть нулевую гипотезу, то есть подтвердить альтернативную гипотезу
Практика
Соберем данные датасета
Ссылка на пример с вычислениями
Теперь давайте посчитаем агрегатную функцию, сумму продаж.
Ссылка на пример с вычислениями
Первый вывод, который мы делаем на основе того, что у нас здесь есть. Сумма продаж у нас в январе была 2.5 тысячи, в феврале 4.5. Давайте возьмем этот график в результаты этих вычислений.
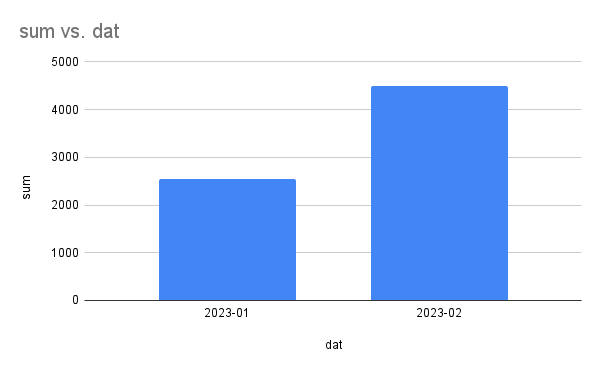
Если бы мы работали только с визуальными картинами, с визуализацией, как мы это делали раньше, мы бы сразу пошли делать вывод, что по сравнению с предыдущим месяцем выручка выросла в 1.7 раз. Но давайте добавим один параметр, который нам в этом поможет, разубедиться. Просто посчитаем количество заказов и средний чек.
Ссылка на пример с вычислениями
Смотрите, в январе у нас было 6 заказов, а в феврале 4. То есть в полтора раза упали продажи, но при этом выручка стала больше. Первый вывод, который мы можем сделать то, что у нас уменьшилось число покупок. Почему произошло так, что у нас увеличилась сумма продаж? Если сумма продаж увеличилась, а количество уменьшилось, следующее, что мы можем предположить, что стоимость одного заказа в феврале стала выше.
Средний чек в феврале составил 1125 единиц, в то время как в январе 423 единиц. То есть почти в три раза вырос средний чек, при том что в полтора раза упало количество и почти вдвое увеличилась выручка. Теперь давайте сами данные посмотрим и поймем что же тут не так. В январе у нас тут средние чеки: 450, 500, 400, 700, но в целом в одном и том же диапазоне все варьируется. Когда же мы смотрим февраль, у нас тут то 2000 покупка, то 1500, то 900 и минимум очень близко к тому, что было минимально в январе. Давайте исключим из вот этого расчета средней аномальные значения, которые есть в каждой из таблиц. Это пусть будет максимальная в феврале, так как она максимальная в принципе за весь исследуемый период и минимальная в январе, так как она тоже минимальная за весь период.
Для этого сделаем простую фильтрацию по name. И давайте пересчитаем наши статистики.
Ссылка на пример с вычислениями
Смотрите, что у нас произошло. Сумма продаж одинаковая, средний чек тоже устаканился, стал более стабильным и количество тоже выравнялось. Тем не менее вот это более нормальная картина, в этом с большей охотой хочется верить, что у нас там примерно одинаковый уровень продаж от месяца к месяцу.
Напомним, что у нас средняя ранее составляла разницу в три раза. Сейчас же разница в полтора раза. То есть аномальные значения, выбросы, влияют на статистику, на итоговые выборки. И статистика помогает выбирать аномалии данных.



