
Scrapy: сбор данных с сайтов на Python — от паука до экспорта
Знакомая сцена. Вам нужны данные с сайта: цены конкурентов, объявления, статьи, отзывы. Вы садитесь и пишете скрипт на requests и BeautifulSoup — скачать страницу, вытащить нужное. На одной странице работает прекрасно, и кажется, что задача решена.
А потом выясняется, что страниц не одна, а десять тысяч. Появляется пагинация, ссылки на карточки товаров, переходы вглубь. Скрипт обрастает вложенными циклами, вызовами sleep, чтобы не забанили, блоками try/except на случай обрыва, ручным сохранением в CSV. И всё это работает мучительно медленно: страницы качаются по одной, каждая ждёт предыдущую. Сбор данных за ночь превращается в сбор за неделю.
Scrapy убирает эту боль. Это фреймворк для сбора данных с сайтов на Python: он берёт на себя движок обхода, одновременную загрузку множества страниц, повторные попытки при сбоях и экспорт результата. Вам остаётся описать, что извлекать и куда переходить, — всё остальное делает фреймворк. Причём делает асинхронно, качая десятки страниц разом, поэтому работает в разы быстрее самописного цикла.
Разберём по шагам: как устроен Scrapy, что такое паук и селекторы, как обходить страницы, почему фреймворк такой быстрый и как выгрузить собранное в файл.
Scrapy — это Python и асинхронная работа с сетью. Сам язык и подобные инструменты разбирают в программе «Python-разработчик» на Хекслете.
Что такое Scrapy
Scrapy — фреймворк для сбора данных с веб-сайтов. Разница между библиотекой и фреймворком тут важна. Библиотека вроде requests даёт кирпичи: скачать страницу, разобрать HTML. Всё остальное — обход ссылок, очередь запросов, параллельность, повторы, сохранение — вы строите сами. Фреймворк даёт готовый каркас: движок уже написан, вы вставляете в него свою логику извлечения.
Что Scrapy берёт на себя из коробки: очередь запросов и планирование обхода, одновременную загрузку множества страниц, повторные попытки при ошибках сети, соблюдение вежливости к сайту, обработку и очистку собранного, экспорт в разные форматы. Всё то, что в самописном скрипте пришлось бы городить руками.
Отдельно стоит асинхронность. Scrapy построен на асинхронном движке: он не ждёт, пока скачается одна страница, чтобы взяться за следующую, а держит десятки запросов в работе одновременно. При этом вам не нужно писать async и await руками — фреймворк управляет параллельностью сам. Отсюда и скорость: пока один запрос ждёт ответа сервера, движок уже качает другие.
Как устроен Scrapy
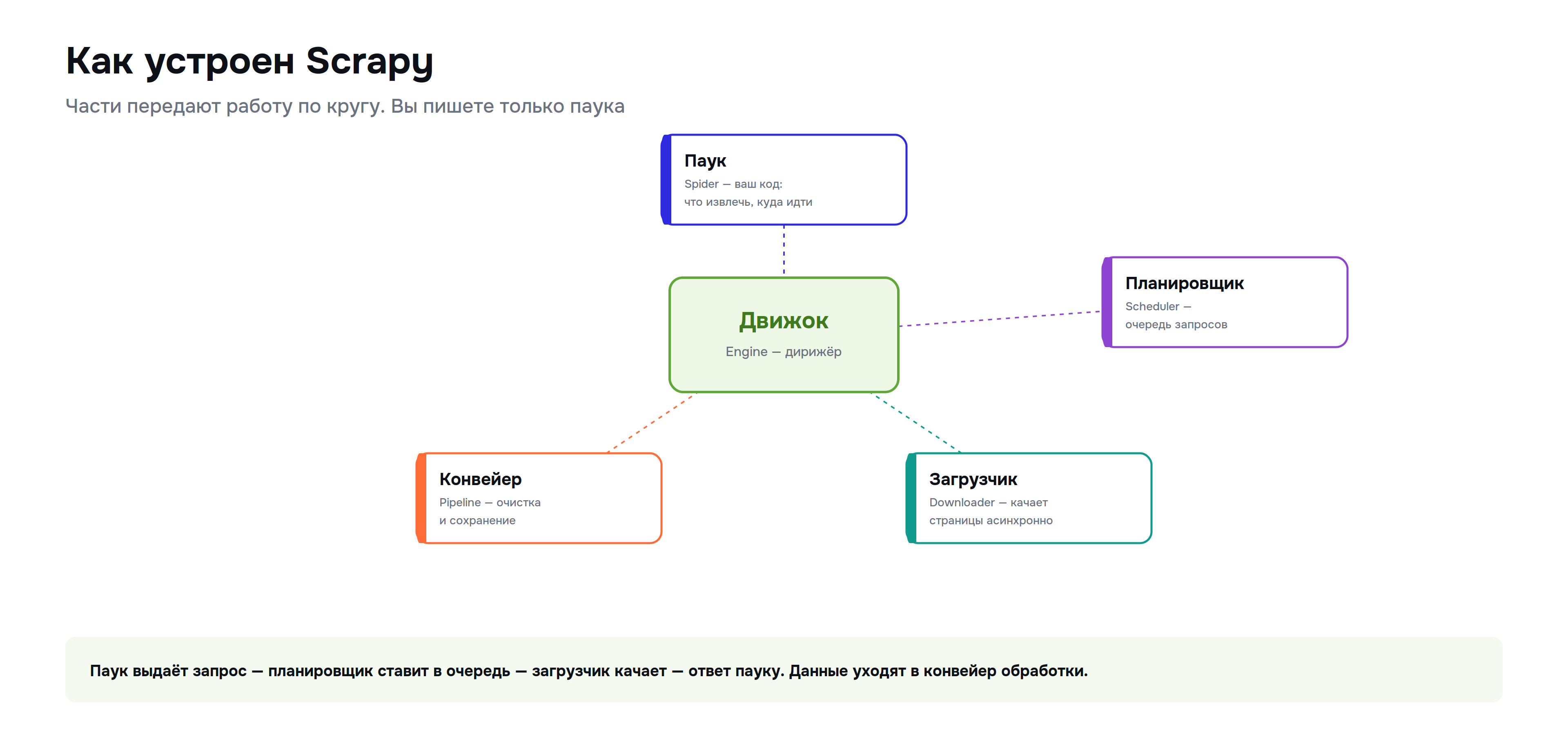
Внутри Scrapy — несколько частей, которые передают работу друг другу по кругу. Понимать эту схему полезно, чтобы знать, где что происходит.
Часть | Что делает |
|---|---|
Паук (Spider) | Ваш код: с каких страниц начать, что извлекать, куда переходить |
Движок (Engine) | Дирижёр: передаёт запросы и ответы между частями |
Планировщик (Scheduler) | Очередь запросов: решает, что качать следующим |
Загрузчик (Downloader) | Скачивает страницы, асинхронно и помногу разом |
Конвейер обработки (Pipeline) | Очищает, проверяет и сохраняет собранные данные |
Цикл выглядит так: паук выдаёт запрос на страницу, движок кладёт его в планировщик, загрузчик скачивает страницу и возвращает ответ пауку. Паук разбирает ответ — часть данных отправляет в конвейер обработки, а найденные ссылки выдаёт новыми запросами. И так по кругу, пока есть что обходить. Вы пишете только паука; движок, планировщик и загрузчик уже готовы.
Паук: минимальный пример
Паук — это класс, где вы описываете, откуда начать и что делать с каждой страницей. Вот паук, который собирает цитаты с учебного сайта:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes" # имя паука
start_urls = ["https://quotes.toscrape.com"] # откуда начать
def parse(self, response):
# response — скачанная страница
for quote in response.css("div.quote"):
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("small.author::text").get(),
}Разберём. У паука есть имя и стартовые адреса. Метод parse получает скачанную страницу и разбирает её: для каждой цитаты на странице он извлекает текст и автора и отдаёт их через yield. Ключевое слово yield здесь не случайно — паук не возвращает всё сразу, а выдаёт данные по мере нахождения, что вписывается в потоковую, асинхронную работу движка.
Извлечение данных: селекторы
Чтобы вытащить нужное из HTML, Scrapy использует селекторы — выражения, которые указывают на элементы страницы. Поддерживаются два языка: CSS-селекторы (те же, что в вёрстке) и XPath (более мощный язык навигации по документу).
# CSS-селекторы
response.css("h1::text").get() # текст первого h1
response.css("a::attr(href)").getall() # все ссылки
# XPath — то же самое
response.xpath("//h1/text()").get()
response.xpath("//a/@href").getall()Два метода делают всю работу. get() возвращает первое совпадение, getall() — список всех. Псевдоэлемент ::text берёт текст внутри тега, а ::attr(href) — значение атрибута. На практике CSS хватает для большинства задач, а к XPath переходят, когда нужна сложная навигация — например, «взять родителя элемента с таким текстом».

Задача | CSS-селектор |
|---|---|
Текст элемента |
|
Значение атрибута |
|
Вложенный элемент |
|
Все элементы списка |
|
Обход страниц: пагинация и переходы
Собрать одну страницу умеет и простой скрипт. Сила Scrapy — в обходе: переходах по ссылкам, пагинации, спуске в карточки. И описывается это на удивление просто.
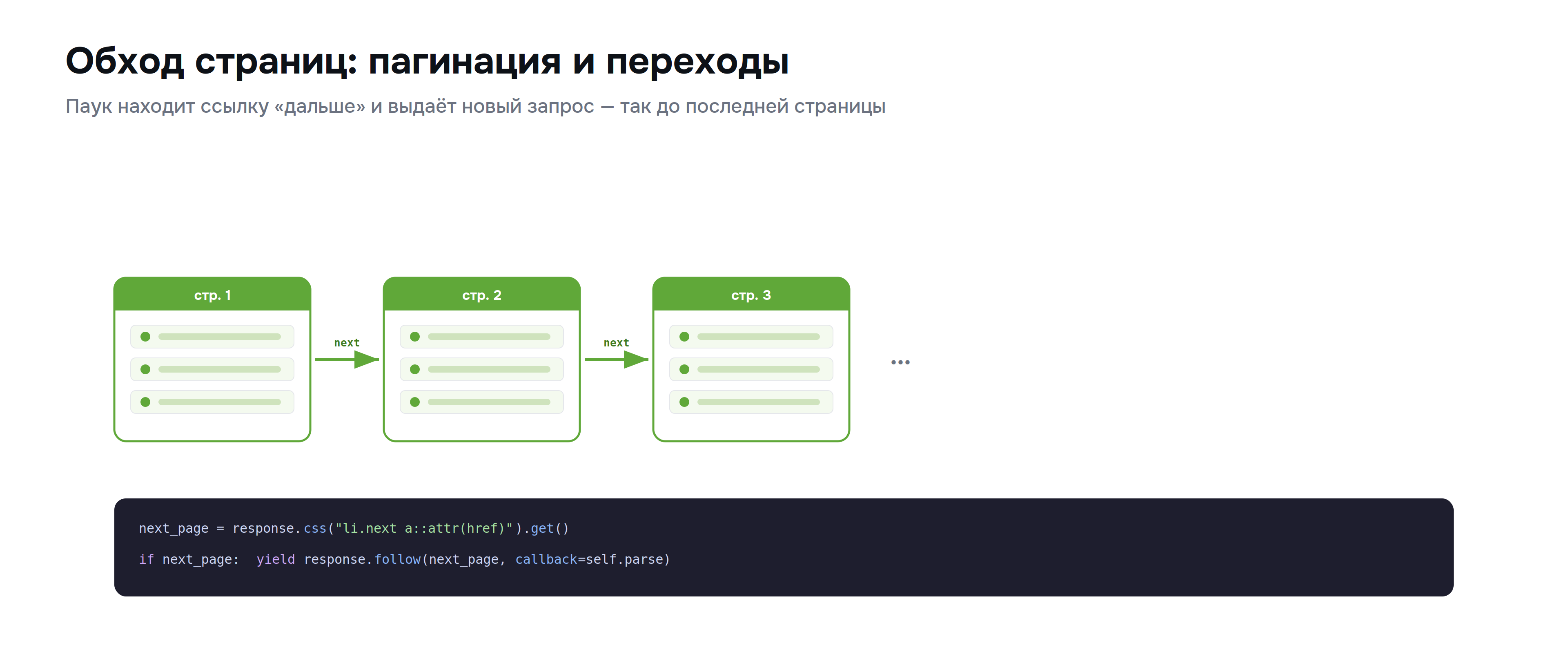
Чтобы перейти на следующую страницу, паук находит ссылку и выдаёт новый запрос через response.follow, указывая, каким методом разбирать результат:
def parse(self, response):
for quote in response.css("div.quote"):
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("small.author::text").get(),
}
# переход на следующую страницу
next_page = response.css("li.next a::attr(href)").get()
if next_page:
yield response.follow(next_page, callback=self.parse)Логика такая: собрали данные с текущей страницы, нашли ссылку «дальше», выдали новый запрос с тем же обработчиком. Движок подхватит его, скачает следующую страницу, снова вызовет parse — и так до последней. Тот же приём работает для перехода в карточку товара: находите ссылку на карточку и выдаёте запрос с отдельным методом-обработчиком, который разберёт уже страницу товара.
Почему Scrapy быстрый
Здесь кроется главное преимущество перед самописным скриптом. Обычный цикл на requests работает последовательно: отправил запрос, ждёшь ответа, обрабатываешь, отправляешь следующий. Пока страница качается — а это доли секунды или секунды — программа простаивает.
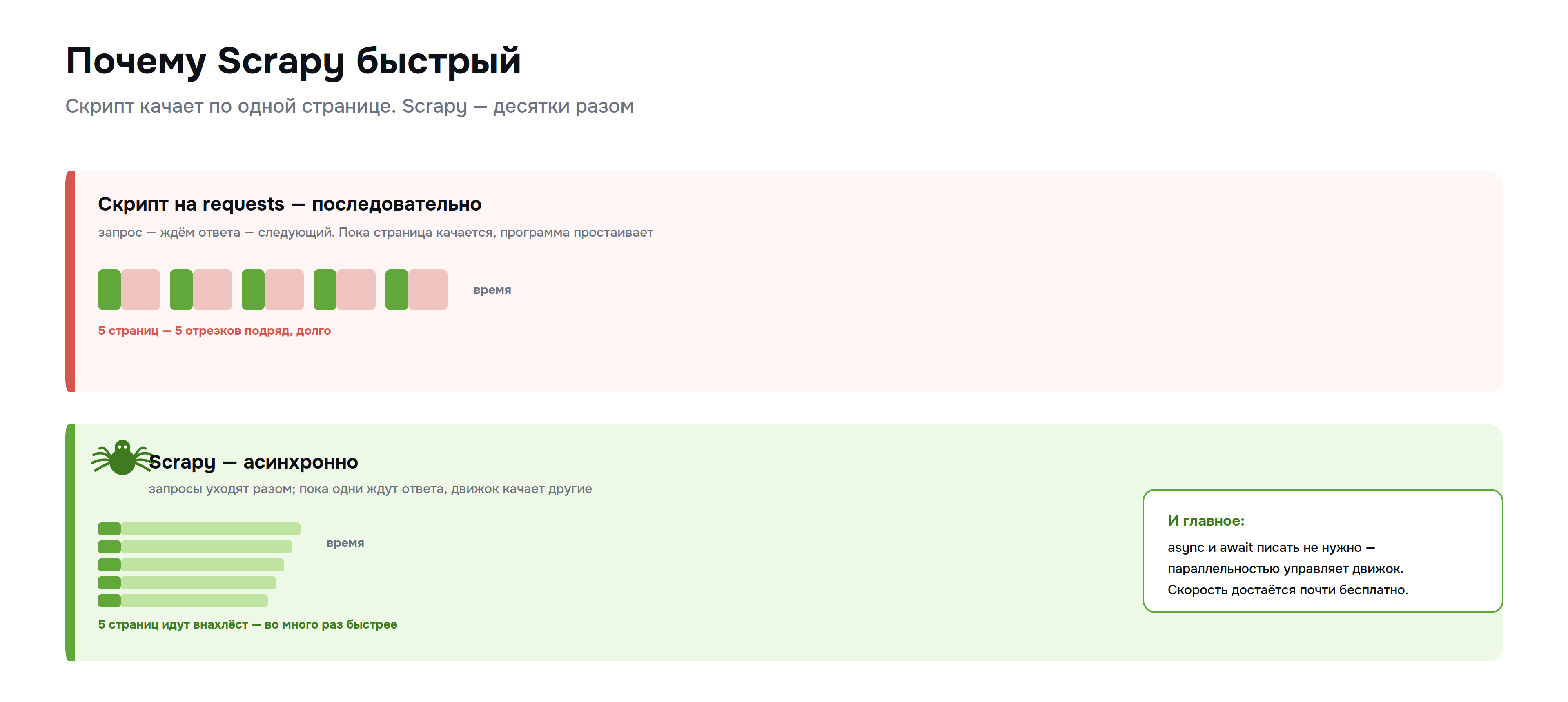
Scrapy работает иначе. Его асинхронный движок отправляет много запросов, не дожидаясь ответов, и обрабатывает их по мере поступления. Пока один запрос ждёт ответа сервера, движок уже качает десятки других. Простой исчезает, и сбор ускоряется во много раз.
Скрипт на requests | Scrapy | |
|---|---|---|
Загрузка | По одной странице за раз | Десятки страниц одновременно |
Ожидание сервера | Программа простаивает | Качает другие страницы |
Скорость | Медленно на объёме | Быстро на объёме |
Код параллельности | Писать самому | Уже внутри фреймворка |
Важная деталь: всю асинхронность фреймворк берёт на себя. Вам не нужно разбираться в asyncio, писать корутины и следить за циклом событий — вы пишете обычный, на вид синхронный код паука, а параллельность обеспечивает движок. Это редкий случай, когда скорость асинхронности достаётся почти бесплатно.
Items и конвейер обработки
Пока мы выдавали данные обычным словарём — на старте этого хватает. Но когда данных много и они сложные, у Scrapy есть более строгий способ: Item, описание структуры собираемой записи.
import scrapy
class ProductItem(scrapy.Item):
title = scrapy.Field()
price = scrapy.Field()
url = scrapy.Field()Item задаёт, из каких полей состоит запись, — как схема таблицы. Дальше собранные записи проходят через конвейер обработки (Item Pipeline). Это цепочка шагов, через которую течёт каждая запись перед сохранением.
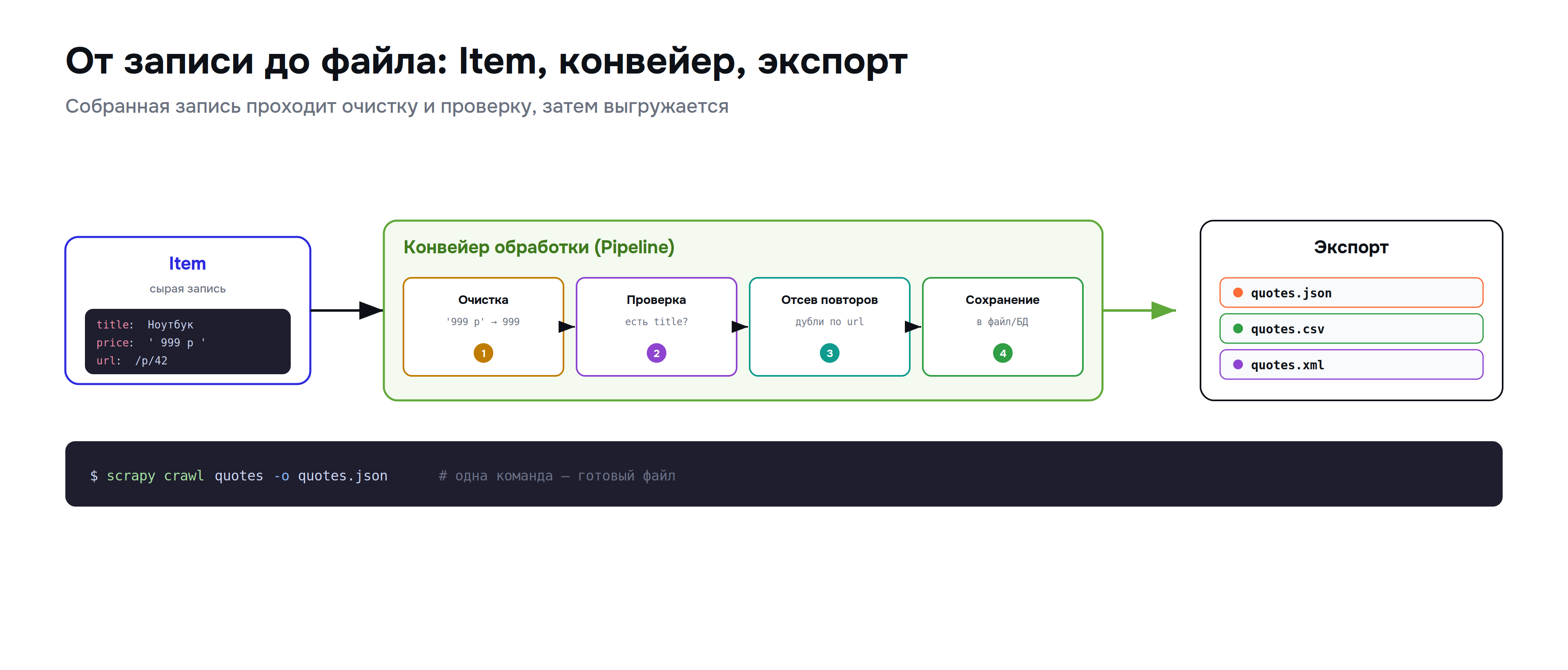
Шаг конвейера | Что делает |
|---|---|
Очистка | Убирает пробелы, приводит цену к числу |
Проверка | Отбрасывает записи без обязательных полей |
Отсев повторов | Удаляет дубликаты по ключу |
Сохранение | Пишет в базу данных или файл |
Смысл конвейера — вынести обработку из паука. Паук занят одним: найти и извлечь. А очистка, проверка и сохранение живут отдельно, в конвейере, и их легко менять, не трогая логику обхода.
Экспорт результата
Самое приятное в конце. Чтобы выгрузить собранное в файл, не нужно писать ни строчки кода сохранения — Scrapy умеет экспорт из коробки. Достаточно указать формат при запуске:
# запуск паука с выгрузкой
scrapy crawl quotes -o quotes.json # в JSON
scrapy crawl quotes -o quotes.csv # в CSV
scrapy crawl quotes -o quotes.xml # в XMLОдна команда — и на выходе готовый файл со всеми собранными записями в нужном формате. Ручное открытие файла, запись строк, закрытие — всё это фреймворк делает сам.
Вежливость: как собирать данные правильно
Сбор данных — мощный инструмент, и пользоваться им нужно ответственно. Грубый обход способен положить чужой сервер потоком запросов, а иногда и нарушить правила сайта. Scrapy помогает вести себя корректно.
Настройка | Зачем |
|---|---|
| Уважать файл robots.txt — где сайт просит не ходить |
| Пауза между запросами, чтобы не грузить сервер |
| Автоматически замедляться, если сервер отвечает медленно |
| Ограничить число одновременных запросов |
Хорошее правило: собирать не быстрее, чем сайт готов отдавать, и не трогать то, что закрыто в robots.txt. Кроме технической стороны есть юридическая — условия использования сайта и правила о персональных данных. Перед серьёзным сбором стоит убедиться, что он разрешён.
Отладка селекторов: scrapy shell
Подбирать селекторы вслепую, каждый раз перезапуская паука, — мучение. У Scrapy для этого есть отдельный инструмент: интерактивная оболочка scrapy shell. Она скачивает страницу один раз и даёт пробовать селекторы вживую, сразу видя результат.
# открыть страницу в оболочке
scrapy shell "https://quotes.toscrape.com"
# внутри пробуем селекторы и сразу видим результат
>>> response.css("span.text::text").get()
'«The world as we have created it...»'
>>> response.css("small.author::text").getall()
['Albert Einstein', 'J.K. Rowling', ...]Схема работы простая: открыли страницу в оболочке, подобрали работающие селекторы, перенесли их в паука. Это экономит уйму времени — вместо десятков перезапусков всего паука вы отлаживаете извлечение на одной странице за секунды. Первым делом при незнакомом сайте открывают именно оболочку.
Практика: паук для сбора цитат
Соберём рабочий паук с нуля — с обходом всех страниц и выгрузкой в файл.
Шаг 1. Создать проект. Scrapy ставится через pip, проект создаётся одной командой:
pip install scrapy
scrapy startproject quotes_projectШаг 2. Написать паука. Класс с извлечением данных и переходом по страницам:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = ["https://quotes.toscrape.com"]
def parse(self, response):
for quote in response.css("div.quote"):
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("small.author::text").get(),
"tags": quote.css("div.tags a.tag::text").getall(),
}
next_page = response.css("li.next a::attr(href)").get()
if next_page:
yield response.follow(next_page, callback=self.parse)Шаг 3. Запустить с выгрузкой. Одна команда обходит все страницы и пишет результат:
scrapy crawl quotes -o quotes.jsonГотово. Паук сам прошёл по всем страницам сайта, собрал цитаты с авторами и метками, обошёл пагинацию и выгрузил всё в JSON — асинхронно и быстро. Того же на самописном цикле пришлось бы добиваться десятками строк с обработкой ошибок и ручным сохранением.
Антипаттерны
Собирать без пауз и ограничений. Обход на максимальной скорости кладёт чужой сервер и быстро приводит к блокировке. Ставят задержку между запросами и разумный предел одновременных запросов — и себе спокойнее, и сайту.
Игнорировать robots.txt и правила сайта. Файл robots.txt и условия использования говорят, что можно собирать. Обходить их — риск и технический, и юридический. Уважать эти правила — не только вежливость, но и защита от проблем.
Вся логика в одном методе parse. Когда извлечение, очистка и сохранение свалены в один метод, паука невозможно поддерживать. Извлечение оставляют в пауке, а очистку и сохранение выносят в конвейер обработки.
Хрупкие селекторы. Селектор, завязанный на случайные классы вроде div.css-1x2y3z, ломается при первом же обновлении вёрстки. Опираются на устойчивые признаки: смысловые классы, структуру, атрибуты.
Не обрабатывать пустые результаты. Селектор ничего не нашёл, get() вернул None — и дальше по цепочке всё падает. Пустые результаты предусматривают: значения по умолчанию, проверки, пропуск битых записей.
FAQ
Чем Scrapy лучше связки requests и BeautifulSoup?
Для одной страницы разницы почти нет, и связка проще. Scrapy выигрывает на объёме: он даёт готовый движок обхода, асинхронную загрузку многих страниц разом, повторы при сбоях и экспорт. Всё это в самописном скрипте пришлось бы писать и отлаживать самому. Правило простое: одна страница — можно на requests, тысячи страниц с обходом — Scrapy.
Нужно ли знать асинхронный Python для Scrapy?
Нет, и это одна из сильных сторон фреймворка. Асинхронностью управляет движок, а вы пишете обычный на вид код паука. Понимание asyncio пригодится для тонкой настройки и сложных случаев, но начать можно без него — скорость асинхронной загрузки достанется сама.
Справится ли Scrapy с сайтами на JavaScript?
Сам по себе Scrapy качает HTML, каким его отдаёт сервер, и не выполняет JavaScript. Если контент подгружается скриптами уже в браузере, нужен дополнительный инструмент — например, связка с headless-браузером. Для обычных серверных страниц Scrapy хватает, для сложных одностраничных приложений — добавляют отрисовку страницы.
Законно ли собирать данные с сайтов?
Зависит от сайта и данных. Публичные данные часто собирать можно, но есть ограничения: условия использования сайта, файл robots.txt, законы о персональных данных и авторском праве. Перед серьёзным сбором стоит проверить правила конкретного сайта и не трогать личные данные без оснований. Технически Scrapy не решает за вас — ответственность на том, кто собирает.
Как не получить блокировку при сборе?
Вести себя вежливо: ставить паузы между запросами, ограничивать их число, уважать robots.txt, не бить по серверу на полной скорости. Резкий агрессивный обход быстро приводит к блокировке по адресу. Медленный аккуратный сбор и надёжнее, и дольше остаётся незамеченным для защиты сайта.
В каких форматах Scrapy сохраняет данные?
Из коробки — JSON, CSV и XML, указанием формата при запуске. Через конвейер обработки данные можно сохранять куда угодно: в базу данных, в облачное хранилище, отправлять по сети. Для простых задач хватает встроенного экспорта в файл, для сложных пишут свой шаг сохранения в конвейере.