DevOps: Автоматизация локального окружения
Теория: Операционные системы и сети
Инфраструктурные задачи неразрывно связаны с работой операционных систем. Причём как на уровне конкретной машины, так и на уровне их взаимодействия. То есть сеть на программном уровне – это тоже операционные системы. Такие понятия, как права доступа, сетевые интерфейсы, порты и многое другое появляются сразу, как только мы начинаем настраивать сервер и запускать Docker.
Тема эта глубокая и большая, но есть вещи, которые надо знать прямо здесь и сейчас. В этом уроке мы пройдёмся по некоторым аспектам, без которых не получится эффективно работать. Мы зададим направления, но для хорошего понимания операционных систем нужно читать книги, одними уроками и статьями в интернете не отделаться. Хорошая новость в том что этих книг всего лишь несколько. Смотреть тут.
И не забудьте пройти курс основы командной строки, если вы этого еще не сделали. Дальше мы вспомним некоторые моменты из этого курса и добавим немного новых.
На десктопе Linux занимает небольшую долю, что и не удивительно. Большая часть пользователей никак не связана с разработкой. А вот на серверах ситуация совершенно другая, практически везде Linux. Именно поэтому важно понимать, как работает Linux, и уметь с ним работать. К тому же, в идеале, локальная среда должна соответствовать продакшен среде, для полного погружения и отработки тех же ошибок.
Пользователи и права
Linux – многопользовательская операционная система, на ней одновременно могут работать разные люди под своими аккаунтами. Кроме обычных аккаунтов, которые нужно создавать самому, один аккаунт в системе есть сразу. Это аккаунт суперпользователя root. Так называется пользователь имеющий 100% права в системе. С него начинается настройка любой новой машины. Использовать его напрямую очень опасно и с точки зрения случайного уничтожения данных и с точки зрения безопасности. Поэтому на новых машинах первым делом создают специальных пользователей для входа или выполнения инфраструктурных задач. Этим пользователям выдают определенные доступы через механизм sudo. С его помощью можно разрешить обычному пользователю выполнение каких-то важных операций.
ФС
Файловая система в Linux не содержит дисков как в Windows. Она начинается с корня /, и всё остальное, включая любые устройства, лежит внутри в виде файлов. Общая концепция в Linux – всё есть файл. Любое устройство – это файл, любое (почти) взаимодействие – тоже файл. Хочется распечатать что-то? Пишем в файл. Хотим передать информацию в другой процесс? Пишем в файл. То же самое на чтение. На верхнем уровне языки и библиотеки предоставляют более удобные механизмы, но внутри всё это выглядит как работа с файлами.
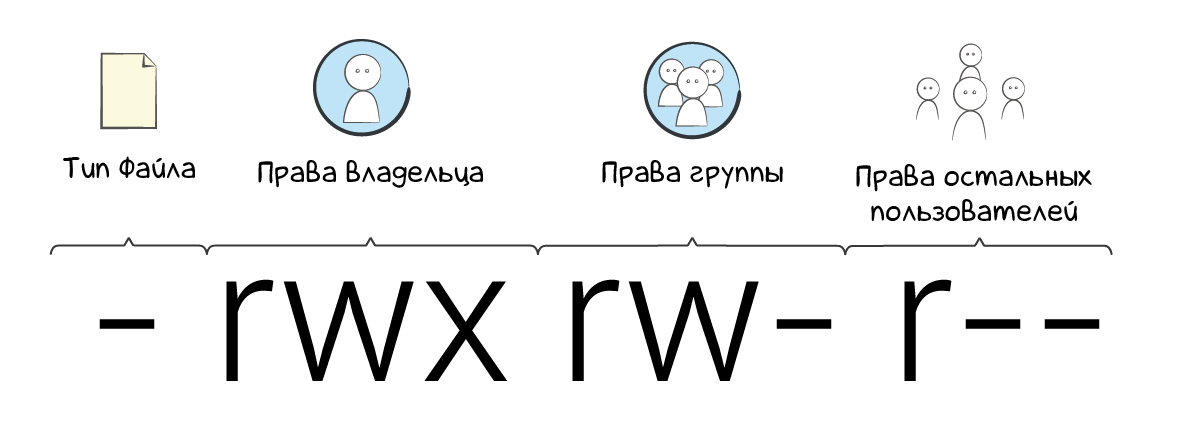
В Linux файловая система имеет определенную, стандартизированную структуру. Из важного: у каждого пользователя есть своя директория с полными правами. Находится она внутри /home (/ в начале обозначает корневую директорию). Логи программ, включая саму операционную систему, находятся внутри /var/logs. Конфигурация программ в директории /etc, а временные файлы внутри /tmp. Подробнее на wiki.
Процессы и Сигналы
Единица работы в Linux – процесс. Каждый раз, когда мы что-то запускаем, то стартует процесс и, возможно, не один. Нормально, когда одна программа состоит из множества процессов и порождает их во время работы. Зачем это сделано? Что вообще такое процесс? Операционная система сама по себе является программой, и она управляет тем, что мы запускаем внутри неё. Процесс – это представление запущенной программы внутри операционной системы. Благодаря вытесняющей многозадачности, современные операционные системы способны запускать и исполнять сотни и больше процессов вместе. Мы привыкли слушать музыку, серфить в браузере и рядом чатиться практически одновременно, и у нас не вызывает вопросов, как это вообще возможно.
Хороший пример – браузер. У современных браузеров одна вкладка – один процесс. Такой подход позволяет переложить обеспечение одновременной работы разных вкладок на саму операционную систему. Кроме того, процессы в операционной системе изолированы друг от друга. Сбой в одном процессе, как правило, не влияет на другие процессы. Поэтому мы видим, как одна зависшая вкладка не мешает работать с другими. Раньше было не так, и зависшая вкладка приводила к полной блокировке браузера.
Процессы внутри себя могут делиться на потоки для обеспечения более высокой производительности или для параллельного запуска. Но это значительно усложняет сам код
Каждому процессу внутри операционной системы соответствует структура данных, внутри которой находится вся информация по процессу. Главный параметр – PID (Process Identificator), то есть идентификатор процесса. Кроме этого там хранится информация о том, какой файл был запущен, от какого пользователя, из какой рабочей директории и так далее. Много данных, которые целиком описывают окружение запуска.
С процессами связано понятие сигналов, позволяющее управлять процессами или взаимодействовать с ними снаружи. Простой пример. Мы хотим завершить какую-то программу. Как это сделать? Существует сигнал SIGTERM, который говорит процессу, что его хотят завершить. Код процесса должен поймать этот сигнал и завершить своё выполнение. Отправка сигнала в Linux выглядит так:
Сигнал SIGTERM не обрабатывается сам по себе. Нужно прямо написать код, который его ловит и выполняет остановку сервиса. Вот пример на JS:
Сигнал SIGTERM не даёт гарантии завершения. Процесс может его вообще проигнорировать или быть настолько загруженным, что он просто не успеет его выполнить за разумный срок. Поэтому в особо важных случаях используют другой сигнал – SIGKILL. Этот сигнал перехватить невозможно, он не попадает внутрь процесса. Операционная система завершает процесс, которому послан такой сигнал, принудительно, в ту же секунду. Процесс будет прерван в любом месте, а значит, скорее всего, он что-то обработает не до конца.
Разных видов сигналов довольно много и они активно используются в администрировании. Некоторые программы используют сигналы, как команду перечитать файлы конфигурации, что позволяет обновляться без остановки.
Супервизор
Запуском процессов занимается супервизор, процесс, задачей которого является контроль других процессов, их запуск, перезапуск и остановку. Супервизор стартует в системе первым и затем запускает всё остальное по описаниям, которые ему дали. В свою очередь запущенные программы (их процессы) запускают свои процессы. В конечном итоге формируется дерево процессов, которое постоянно изменяется. Его можно вывести командой ps auxf:
Супервизор – такая же программа, как и всё остальное. Причём супервизоры бывают разные и могут меняться. На текущий момент в большинстве Linux дистрибутивов используется Systemd. Ниже пример файла, описывающего как запустить процесс программы Nginx с помощью Systemd:
Обычно такие файлы поставляются прямо с программами, но иногда их нужно делать самостоятельно. Systemd – гибкая система, позволяющая не только задавать правила старта, но и ограничивать ресурсы процессов, например, ставить лимиты по памяти или процессу.
Кроме того, systemd собирает логи со всех запущенных процессов. Для этого каждый процесс, контролируемый systemd, должен выводить свои логи в STDOUT. Затем их можно просматривать с помощью утилиты journalctl:
Сеть
Практически все взаимодействия в веб-приложениях – являются сетевыми. Запросы к сайтам из браузера, взаимодействие с базами данных, между Docker-контейнерами, системами кеширования, API внешних сервисов – всё это сводится к сетевым запросам. Сети крайне важны и для инфраструктурных задач. Начиная с ssh подключений к машинам, заканчивая организацией сетевого взаимодействия между сервисами внутри кластера или даже датацентрами.
Знание сетей можно грубо разделить на два уровня – инфраструктурный и прикладной. Первый – это всё что касается проводов, устройств и технологий (wi-fi, соты). На данном уровне работают сетевые инженеры и это слишком далеко от прикладной разработки. Второй уровень работает поверх инфраструктуры и не завязан на неё. Здесь мы оперируем программами на разных компьютерах, которые общаются друг с другом, не задумываясь (почти) о том, как физически данные ходят между ними.
Типичная ситуация – обращение к сайту. Здесь мы со своего компьютера отправляем запрос на другой компьютер и в ответ получаем страницу, которую показывает браузер. И хотя, судя по адресной строке, запрос выполняется по протоколу HTTP, всё чуть сложнее. HTTP – протокол прикладного уровня, он не знает про существование компьютеров в сети и работает уже поверх установленного соединения между компьютерами. А вот соединение делается с помощью протокола TCP, который нас интересует больше всего. На TCP держится практически всё сетевое взаимодействие.
TCP/IP
Протокол TCP позволяет общаться между собой процессам расположенным как на одном компьютере, так и на разных. Процессам, а не компьютерам, что очень важно. Подключение по TCP идёт из конкретного процесса в конкретный процесс. Для соединения нужно два параметра: ip–адрес и порт. Ip-адрес обычно устанавливается автоматически, а вот порт выбирается самим разработчиком, хотя и он может присваиваться автоматически. Связка адреса и порта однозначно говорит нам о том, с какой программой происходит связь. Именно поэтому параметра два. Одного ip-адреса недостаточно, тогда мы не сможем понять, какая программа хочет работать по сети.
TCP клиент-серверный протокол. То есть один компьютер выступает в качестве сервера, а те, кто к нему присоединяются – клиенты. Сервер во время старта указывает ip-адрес и порт, на которых нужно запуститься. Говорят, что сервер "слушает" порт.
Примерно так происходят все сетевые взаимодействия. И даже HTTP отправляется по установленному TCP-соединению.
Интерфейсы
Сетевое взаимодействие в Linux работает через понятие "сетевой интерфейс". Сетевой интерфейс – это программный способ обращаться к сетевой карте в том случае, когда он связан с физическим устройством. Но сетевой интерфейс может быть "виртуальным", то есть он не связан с железом, а существует лишь на уровне самой операционной системы. Нужно это для взаимодействия программ, которые изначально сетевые, но запускаются на одном компьютере. Посмотреть сетевые интерфейсы внутри операционной системы можно командой ifconfig:
ifconfig
eth0 Link encap:Ethernet HWaddr 08:00:27:31:65:b5
inet addr:10.0.2.15 Bcast:10.0.2.255 Mask:255.255.255.0
inet6 addr: fe80::3db9:eaaa:e0ae:6e09/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1089467 errors:0 dropped:0 overruns:0 frame:0
TX packets:508121 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:903808796 (903.8 MB) TX bytes:31099448 (31.0 MB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:9643 errors:0 dropped:0 overruns:0 frame:0
TX packets:9643 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:719527 (719.5 KB) TX bytes:719527 (719.5 KB)
eth0 – интерфейс, связанный с сетевой картой, работающей через Ethernet (по кабелю). В выводе выше можно увидеть множество полезной информации, например, ip-адрес, привязанный к этому интерфейсу. Если бы сетевых карт было несколько, то кроме eth0, мы бы увидели eth1 и так далее.
lo (lookpback device) – виртуальный интерфейс, присутствующий по умолчанию в любом Linux. Он используется для отладки сетевых программ и запуска серверных приложений на локальной машине. С этим интерфейсом всегда связан адрес 127.0.0.1. У него есть dns-имя – localhost. Посмотреть привязку можно в файле /etc/hosts.
Запуск сервисов
Понимание принципов работы интерфейсов (и в целом tcp/ip) крайне важно для запуска любых сетевых сервисов, будь то веб-сервер или база данных. От этого зависит как доступность сервиса, так и безопасность всего процесса. Мы уже знаем, что запуск сервиса – это запуск процесса операционной системы, который внутри себя должен начать слушать порт на определенном ip-адресе, то есть интерфейсе. По умолчанию большинство сервисов стартует на localhost либо в документации предлагают стартовать на нём.
На это есть 2 причины. По умолчанию это безопасно. Сервис, запущенный на одном интерфейсе, недоступен с другого. То есть при таком запуске сервис занимает 8000 порт на 127.0.0.1 адресе, но 8000 порт на интерфейсе eth0 остается свободным, а значит снаружи до него не достучаться. Как правило, сервисы не выставляют напрямую во внешний мир, часто для этого служат специальные прокси, которые прокидывают запросы внутрь и обеспечивают дополнительные функции связанные с производительностью или безопасностью.
С другой стороны часть сервисов всё же нужно выставлять наружу. И здесь появляется сложность: нам нужно знать точный ip-адрес интерфейса, на который мы хотим завязаться. Подобное не всегда возможно, адреса имеют свойство меняться. Более того, если сервис запущен на разных машинах, то адреса вообще не совпадут. Как выкручиваться из этой ситуации? Через специальный псевдо-адрес 0.0.0.0. В Linux это не конкретный адрес, а скорее указатель, который говорит о необходимости связать запуск сервиса со всеми доступными интерфейсами в системе. То есть привязавшись к 0.0.0.0, сервис автоматически станет доступным через все сетевые интерфейсы системы.
Завершено
0 / 7