Одна из главных фич эрланг -- устойчивость к ошибкам (fault tolerance). Считается, что система, сделанная на эрланг, может легко переживать ошибки в коде и в данных, аппаратные сбои, сбои в сети, и продолжать обслуживать клиентов.
Это не значит, что любой код на эрланг сразу обладает такими свойствами. Об этом должен позаботиться программист. А эрланг только дает средства, которыми программист может обеспечить устойчивость. Давайте посмотрим, что это за средства.
link
Устойчивость к ошибкам построена на способности потоков наблюдать друг за другом. Два потока можно связать друг с другом так, что при падение одного, второй получит специальное сообщение и тоже упадет.
Можно связать группу потоков, так, что при падении одного из них, упадет вся группа. Предполагается, что потоки зависят друг от друга в своей работе. Отсутствие одного потока приводит к нештатной ситуации, в которой остальные не могут выполнять осмысленных действий. Они только усугубляют и распространяют проблемы. Так что лучше остановить и рестартовать всю группу.
Информация о падении передается в системном сообщении, тем же способом, что и обычные сообщения между потоками. Но системные сообщения (их еще называют сигналы), не попадают в почтовый ящик. Их нельзя обработать обычным способом. Вместо этого, они просто завершают поток, который их получил, и распространяются дальше по имеющимся связям.
При нормальной остановке потока сигнал распространяется, но не вызывает завершение связанных потоков.
Вызов link(Pid) создает связь между текущим потоком и Pid. Связь двухсторонняя. Чтобы связать несколько потоков, нужно сделать несколько вызовов link. Если потоки уже связаны, то вызов link не оказывает никакого эффекта.
Вызов unlink(Pid) разрывает связь.
Часто бывает нужно создать новый поток и связь с ним. Это можно сделать последовательными вызовами spawn и link. Но поток может завершиться до вызова link. Поэтому лучше использовать функцию spawn_link, которая объединяет эти две операции, но выполняется атомарно.
Рассмотрим пример кода:
-module(sample1).
-export([run/0, run_and_crash/0, work/1, work_and_crash_one/1]).
run() ->
[spawn_link(?MODULE, work, [Id]) || Id <- lists:seq(0, 5)],
ok.
work(Id) ->
io:format("~p ~p started~n", [Id, self()]),
timer:sleep(1000),
io:format("~p ~p stopped~n", [Id, self()]),
ok.
Здесь мы запускаем 5 потоков, и связываем их все с потоком консоли. Они стартуют, ждут 1 секунду, и завершаются:
2> sample1:run().
0 <0.40.0> started
1 <0.41.0> started
2 <0.42.0> started
3 <0.43.0> started
4 <0.44.0> started
5 <0.45.0> started
ok
5 <0.45.0> stopped
4 <0.44.0> stopped
3 <0.43.0> stopped
2 <0.42.0> stopped
1 <0.41.0> stopped
0 <0.40.0> stopped
Теперь сделаем, чтобы один из потоков завершался. Это будет 3-й поток, как раз в середине всей группы потоков:
run_and_crash() ->
[spawn_link(?MODULE, work_and_crash_one, [Id]) || Id <- lists:seq(0, 5)],
ok.
work_and_crash_one(Id) ->
io:format("~p ~p started~n", [Id, self()]),
if
Id == 3 ->
io:format("~p ~p exiting~n", [Id, self()]),
exit(for_some_reason);
true -> ok
end,
timer:sleep(1000),
io:format("~p ~p stopped~n", [Id, self()]),
ok.
Видим, что стартуют все потоки, но ни один из них не выполняется до конца, потому что вместе с 3-м потоком завершились и все остальные.
7> self().
<0.68.0>
8> sample1:run_and_crash().
0 <0.71.0> started
1 <0.72.0> started
2 <0.73.0> started
3 <0.74.0> started
4 <0.75.0> started
5 <0.76.0> started
3 <0.74.0> exiting
ok
** exception exit: for_some_reason
9> self().
<0.77.0>
Поток консоли также завершился, и рестартовал заново.
Системные потоки
Связи -- это хорошо, но этого мало. Наш следующий инструмент -- разделение ролей между потоками. Есть рабочие потоки, которые делают полезную работу. И есть системные потоки, которые следят за состоянием рабочих потоков.
Чтобы сделать поток системным, достаточно вызывать:
process_flag(trap_exit, true)
При этом для потока устанавливается специальный флаг trap_exit. После чего сигналы, которые они получает, превращаются в обычные сообщения и попадают в почтовый ящик. Таким образом системный поток может обработать падение рабочего потока.
Сигнал превращается в сообщение вида:
{'EXIT', Pid, Reason}
Это кортеж из 3-х элементов. На первой позиции атом 'EXIT', на второй -- Pid рабочего потока, на третей позиции -- причина завершения потока (обычно атом или исключение).
Рассмотрим пример:
-module(sample2).
-export([run/0, system_process/0, worker/0]).
run() ->
spawn(fun system_process/0),
ok.
system_process() ->
io:format("~p system process started~n", [self()]),
process_flag(trap_exit, true),
spawn_link(fun worker/0),
receive
Msg -> io:format("~p system process got message ~p~n", [self(), Msg])
after 2000 -> ok
end,
ok.
worker() ->
io:format("~p worker started~n", [self()]),
timer:sleep(500),
exit(some_reason),
ok.
Здесь сперва создается системный поток, затем связанный с ним рабочий поток. Рабочий поток завершается после небольшой паузы, а системный поток получает сообщение об этом.
2> sample2:run().
<0.40.0> system process started
<0.41.0> worker started
ok
<0.40.0> system process got message {'EXIT',<0.41.0>,some_reason}
Варианты событий при завершении потока
Поток может завершится двумя способами: нормально или аварийно. В первом случае поток просто выполнил до конца ту функцию, с которой он стартовал. Во втором случае произошла какая-то ошибка или исключение.
Кроме этого, поток можно принудительно завершить вызовом функции exit.
exit/1 завершает текущий поток с заданной причиной:
exit(normal)
exit(some_reason)
exit/2 завершает поток с заданным Pid:
exit(Pid, normal)
exit(Pid, some_reason)
Таким образом можно эмулировать и нормальное и аварийное завершение потока.
Возьмем систему из 5 связанных потоков:
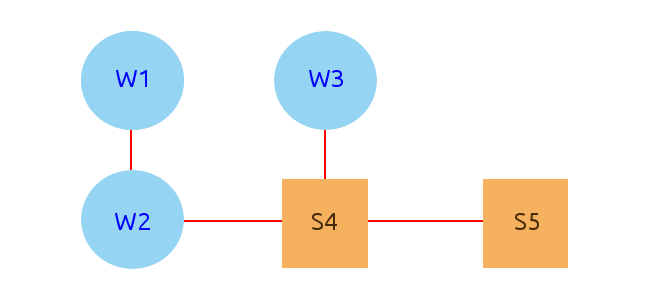
Здесь три рабочих потока: W1, W2, W3, и два системных потока: S4, S5. Красными линиями показаны связи.
Рассмотрим, что будет происходить в системе при завершении потока W2 с разными причинами.
Нормальное завершение потока
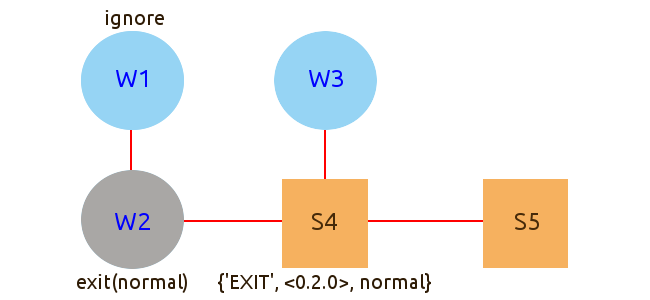
Поток W2 завершается нормально. Сигнал доходит до потока W1, но игнорируется. W1 продолжает работать, хотя теперь он ни с кем не связан.
Сигнал доходит до потока S4, превращается в сообщение {'EXIT', <0.2.0>, normal}, и попадает в почтовый ящик S4. Дальше сигнал не распространяется.
Аварийное завершение потока
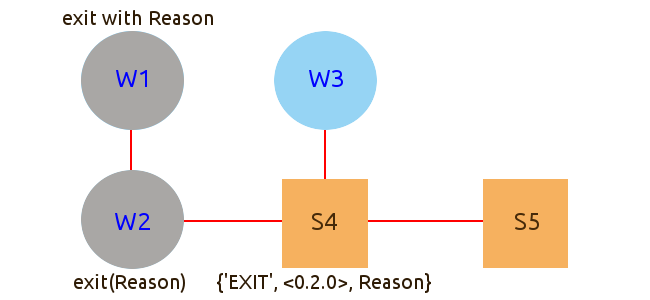
Поток W2 завершается аварийно с некой причиной Reason. Сигнал доходит до потока W1, и W1 тоже завершается аварийно с той же причиной.
Сигнал доходит до потока S4, превращается в сообщение {'EXIT', <0.2.0>, Reason}, и попадает в почтовый ящик S4. Дальше сигнал не распространяется.
Завершение потока с причиной kill
Пока все просто. Но создатели эрланг предусмотрели способ аварийно завершить системный поток на случай, если большая часть системы придет в неконсистентное состояние. Этот способ -- завершение потока с причиной kill.
Сигнал с причиной kill не превращается в сообщение, не перехватывается системным потоком, а заставляет поток завершиться с причиной killed. Тут важно, что меняется причина с kill на killed, иначе такой сигнал невозможно было бы остановить, и он завершил бы все потоки. Ну а killed перехватывается системными потоками обычным способом.
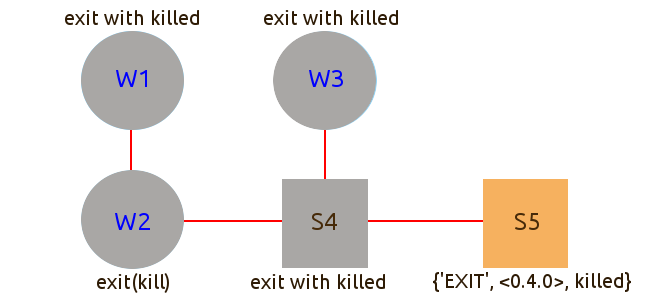
Поток W2 завершается с причиной kill. Сигнал доходит до потока W1, и W1 завершается с причиной killed. Сигнал доходит до потока S4, и S4 завершается с причиной killed.
Сигнал распространяется дальше. Доходит до W3, и W3 завершается с причиной killed. Наконец, сигнал доходит до S5, превращается в сообщение {'EXIT', <0.4.0>, killed}, и попадает в почтовый ящик S5.
monitor
Кроме link, есть еще один механизм наблюдения за состоянием потоков -- монитор. Этот механизм существенно отличается:
- связь односторонняя;
- информация сразу приходит в виде сообщения, а не в виде сигнала;
- мониторов может быть несколько, и каждый работает независимо от остальных;
- получателю не нужно быть системным потоком;
- информация о нормальном завершении тоже доходит и обрабатывается.
Текущий поток может установить монитор над другим потоком вызовом:
Reference = erlang:monitor(process, Pid)
А аргументах передаются атом process и Pid потока, который нужно мониторить. Возвращается ссылка на установленный монитор. (Первый аргумент предполагает, что мониторить можно что-то еще, кроме потоков. Но подробности смотрите в документации).
Если поток завершается, то второй поток получает сообщение:
{'DOWN', Reference, process, Pid, Reason}
Где Reference -- это ссылка на монитор, Pid -- завершившийся поток, Reason -- причина завершения потока.
Установленный монитор можно снять:
erlang:demonitor(Reference, [flush]).
Опция flush удаляет из почтового ящика сообщение вида {'DOWN', Reference, process, Pid, Reason}, если оно есть.
Заключение
Использовать низкоуровневые функции link/unlink и создавать свои системные процессы не рекомендуется. Нужен хороший опыт, чтобы грамотно пользоваться этими средствами. К счастью, это редко бывает нужно, потому что у нас есть высокоуровневое средство -- супервизор.
Супервизор построен поверх link и trap_exit, построен хорошо и отлажен годами использования в нагруженных проектах. Вот его и нужно использовать. Это тема следующего урока.
monitor используется чаще, когда нам не хватает тех вариантов обработки, которые предлагает супервизор.
Остались вопросы? Задайте их в разделе «Обсуждение»
Вам ответят команда поддержки Хекслета или другие студенты
