'%3e%3cpath%20d='M13.1407%204.34375L9.12548%205.80383L6.93536%209.45402L4.38023%205.80383L0.365019%204.34375L5.11027%2011.6441L0%2019.6745H2.92015L6.57034%2013.8342L10.5856%2019.6745H13.5057L8.39544%2011.6441L13.1407%204.34375ZM17.1559%2012.0091C17.5209%2010.5491%2018.981%209.089%2020.8061%209.089C22.6312%209.089%2024.0913%2010.5491%2024.4563%2012.0091H17.1559ZM20.8061%206.89888C17.1559%206.89888%2014.2357%209.81904%2014.2357%2013.4692C14.2357%2017.4844%2017.1559%2020.0396%2020.8061%2020.0396C23.3612%2020.0396%2025.9164%2018.5795%2027.0114%2016.0244H24.0913C23.7262%2017.1194%2022.2662%2017.8495%2020.8061%2017.8495C18.616%2017.8495%2017.1559%2016.3894%2016.7909%2014.1993H27.0114C27.3764%2010.1841%2024.8213%206.89888%2020.8061%206.89888ZM40.8821%207.2639H37.597L32.1217%2012.7392V7.2639H29.5665V19.6745H32.1217V13.8342L38.327%2019.6745H41.6122L35.0418%2013.1042L40.8821%207.2639ZM48.5475%209.45402C50.0076%209.45402%2051.4677%2010.1841%2051.8327%2011.6441H54.3878C54.0228%208.72398%2051.4677%206.89888%2048.5475%206.89888C44.5323%206.89888%2041.9772%209.81904%2041.9772%2013.4692C41.9772%2017.1194%2044.5323%2020.0396%2048.1825%2020.0396C51.1027%2020.0396%2054.0228%2018.2145%2054.3878%2015.2943H51.8327C51.4677%2016.7544%2050.0076%2017.4844%2048.1825%2017.4844C45.9924%2017.4844%2044.5323%2016.0244%2044.5323%2013.4692C44.5323%2011.2791%2045.9924%209.45402%2048.5475%209.45402ZM58.403%2014.5643C58.038%2017.1194%2057.673%2017.4844%2056.2129%2017.4844H55.4829V20.0396H56.943C58.7681%2020.0396%2060.2281%2018.5795%2060.9582%2014.9293L61.6882%209.81904H66.0684V19.6745H68.6236V7.2639H59.4981L58.403%2014.5643ZM73.7338%2012.0091C74.4639%2010.5491%2075.5589%209.089%2077.7491%209.089C79.5742%209.089%2080.6692%2010.5491%2081.0342%2012.0091H73.7338ZM77.7491%206.89888C73.7338%206.89888%2071.1787%209.81904%2071.1787%2013.4692C71.1787%2017.4844%2073.7338%2020.0396%2077.7491%2020.0396C80.3042%2020.0396%2082.8593%2018.5795%2083.5894%2016.0244H81.0342C80.3042%2017.1194%2079.2091%2017.8495%2077.7491%2017.8495C75.5589%2017.8495%2074.0989%2016.3894%2073.7338%2014.1993H83.9544C84.3194%2010.1841%2081.7643%206.89888%2077.7491%206.89888ZM91.9848%207.2639H85.4145V9.81904H89.4297V19.6745H91.9848V9.81904H96V7.2639H91.9848Z'%20fill='%231D1D1B'%20/%3e%3cpath%20d='M13.1429%202.51607L6.93753%20-0.0390625L0.367188%202.51607L6.93753%204.70618L13.1429%202.51607Z'%20fill='%23136EF6'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_139_18360'%3e%3crect%20width='96'%20height='24'%20fill='%23fff'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Python: Визуализация данных
Теория: Создание базовых графиков
С помощью визуализации можно представить данные на графиках и диаграммах, и таким образом упростить анализ данных. В этом уроке мы научимся использовать инструменты визуализации на примере первичного анализа датасета Titanic. Мы будем использовать:
- Частотные графики
- Диаграммы
- Ящики с усами
- Скрипичные графики
- Гистограммы
- Тепловые карты
- Попарные графики
Подготовка данных
Начнем с предобработки датасета. Мы будем использовать следующие три модуля для разных задач:
Аналитики часто работают со структурированными данными в табличном виде. Для работы с ними в Python нужен модуль Pandas, который отличается скоростью и высокоуровневой реализацией функций. В этом уроке вы увидите, как этот модуль работает на практике.
Загрузим датасет в исходном виде:
Датасет Titanic содержит ряд столбцов c признаками, которые характеризуют пассажиров Титаника. Также есть метка Survived — она показывает, выжил ли пассажир во время крушения корабля. Представим, что нам нужно изучить набор признаков каждого пассажира и предсказать, кто выжил. Посмотрим на весь набор параметров:
Для просмотра данных воспользуемся методом head():
Чтобы первично обработать данные, нужно:
- Удалить или заполнить пропуски
- Привести данные в столбцах к определенному типу
- Сформировать дополнительные признаки на основе других
Эти шаги не входят в рамки этого урока, поэтому не будем подробно вдаваться в код ниже. Вы можете изучить его самостоятельно:
Исходные данные готовы — можно приступать к анализу.
Визуализация данных
Во время анализа нам нужно прийти к двум целям: выявить закономерности в данных и найти нехарактерные значения, которые могут указывать на ошибки. Для визуализации воспользуемся двумя популярными модулями:
- Matplotlib для настройки параметров графиков и форматирования вывода
- Seaborn для построения графиков
Эти модули помогают писать код с меньшим количеством дополнительных параметров. Это упрощает разработку и делает код более читабельным:
Мы объявили модули — можно начинать строить графики.
Частотные графики
Для начала посмотрим на частотный график для столбца Survived:
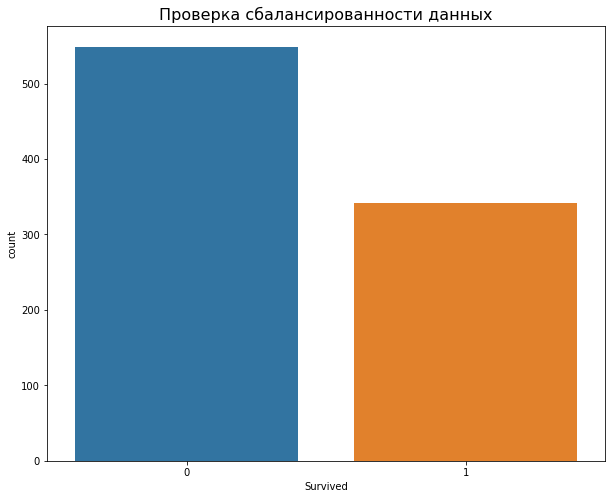
На диаграмме выше видно, что погибших больше, чем выживших. Это важная характеристика датасета, потому что сбалансированность классов влияет на подходы к построению моделей, которые предсказывают тот или иной класс. В случае несбалансированности классов, нужно выполнять несколько дополнительных преобразований с данными.
Для примера приведем аналогичный график распределения пассажиров по полу:
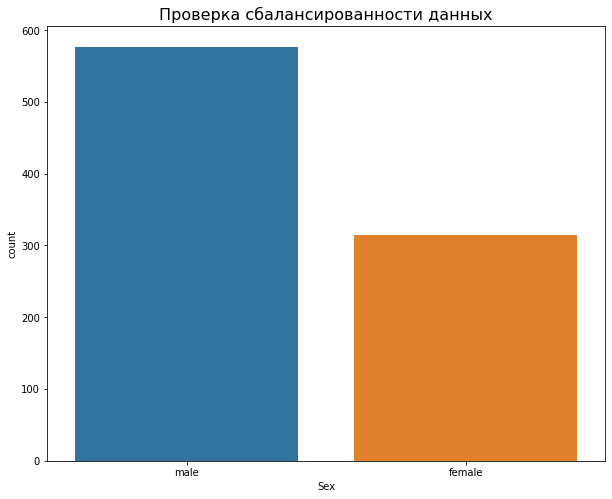
Библиотека Matplotlib позволяет создавать несколько графиков на одном полотне в виде окон. Причем в каждое окно можно поместить различные графики как самой библиотеки Matplotlib, так и ее приемников:
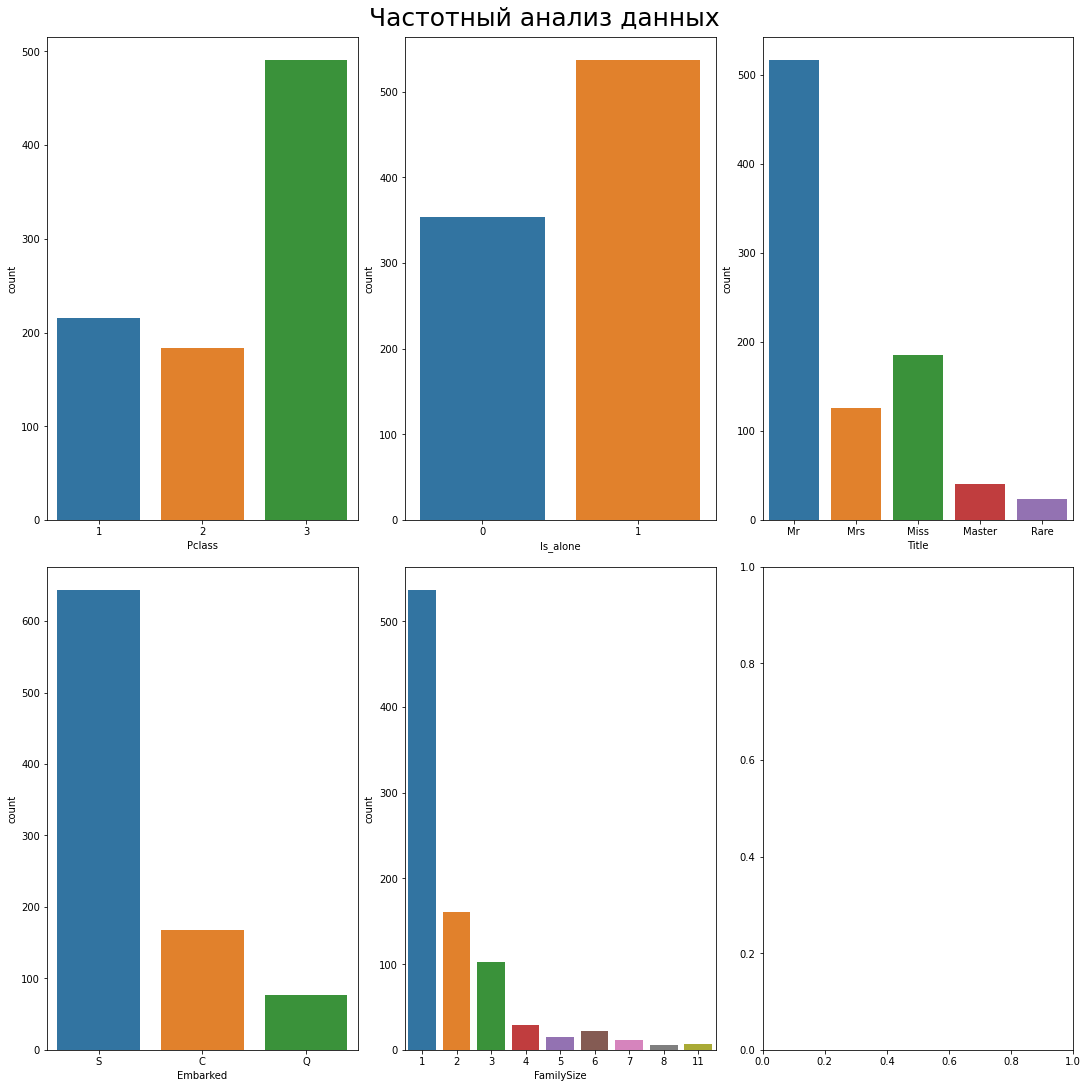
На картинке выше вы видите пять графиков. Они показывают частотную картину для значений из различных столбцов данных. Пустое окно создается по умолчанию, потому что Matplotlib отрисовывает прямоугольную таблицу по заранее заданным параметрам метода subplots(). В нашем случае размер таблицы по умолчанию — 2 на 3.
Далее попробуем предсказать выживаемость пассажира. Для этих целей аналитики строят частотные графики в разрезе целевой переменной.
В случае с Seaborn можно использовать параметр hue:
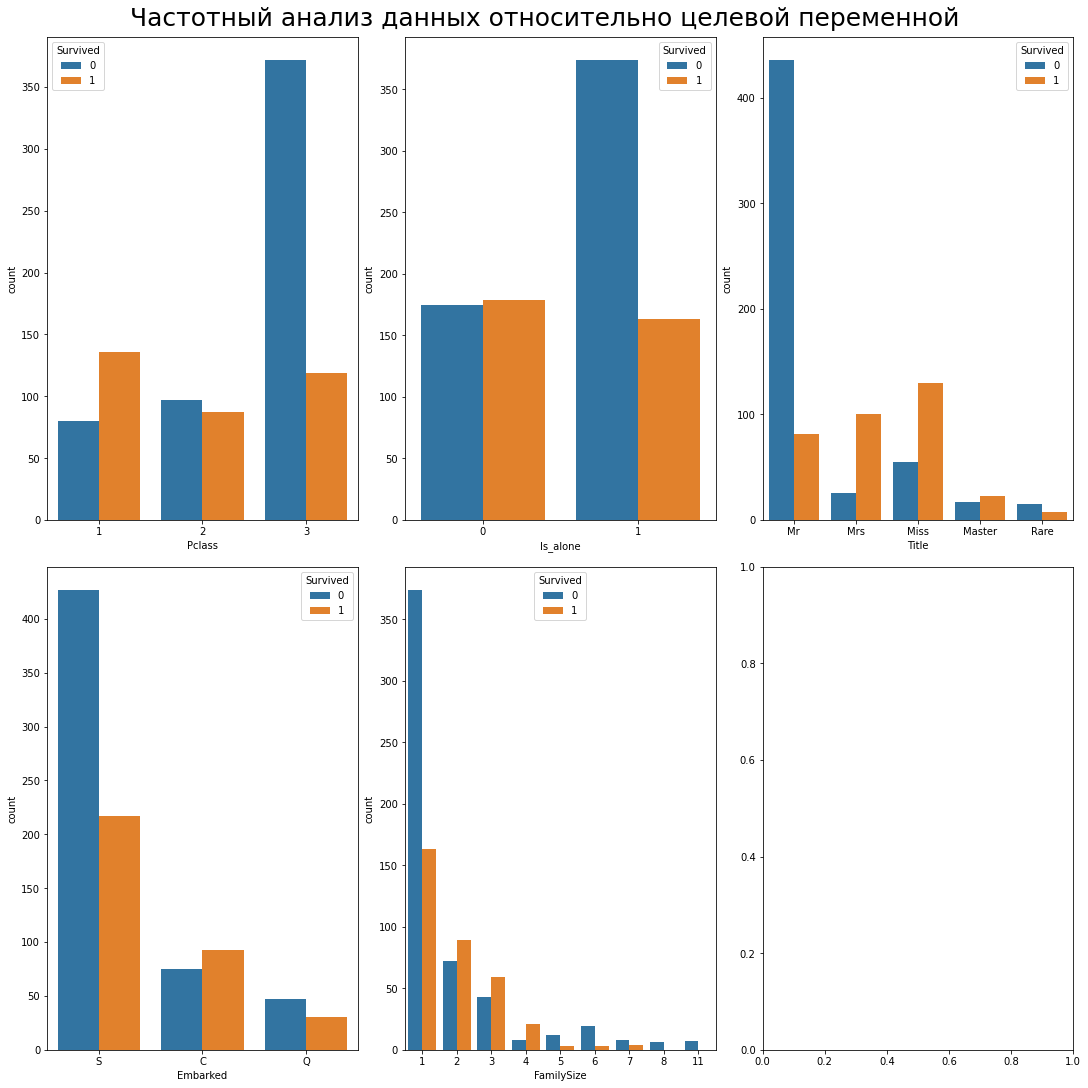
Графики выше показывают, что с большой вероятностью не выжили одинокие мистеры из третьего класса, севшие в Саутгемптоне — примерно такие гипотезы аналитики обычно выдвигают по графикам и диаграммам. Дальше эти гипотезы нужно подтвердить или опровергнуть методами статистического и корреляционного анализа — это типичный порядок работы аналитика.
Рассмотрим картину выживаемости для различных возрастов. По ней видно, что среди погибших много людей среднего возраста:
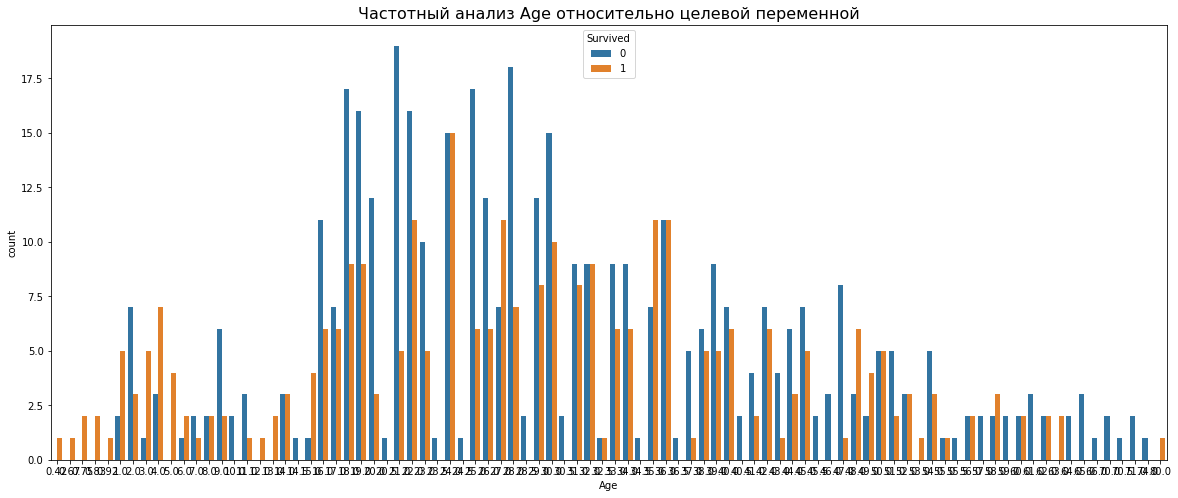
Столбчатые диаграммы
Перейдем от частотного анализа к оценке статистических показателей. Воспользуемся методом barplot() и построим среднее значение целевой переменной в зависимости от признака:
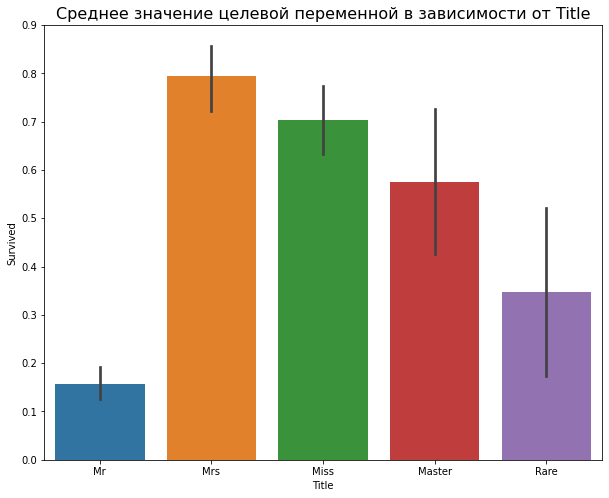
Этот график показывает среднюю вероятность выживаемости в зависимости от признака Title. Черная вертикальная линия демонстрирует разброс вероятности относительно среднего — чем длиннее линия, тем разброс больше. Аналогичный график зависимости вероятности выживаемости в зависимости от размера семьи:
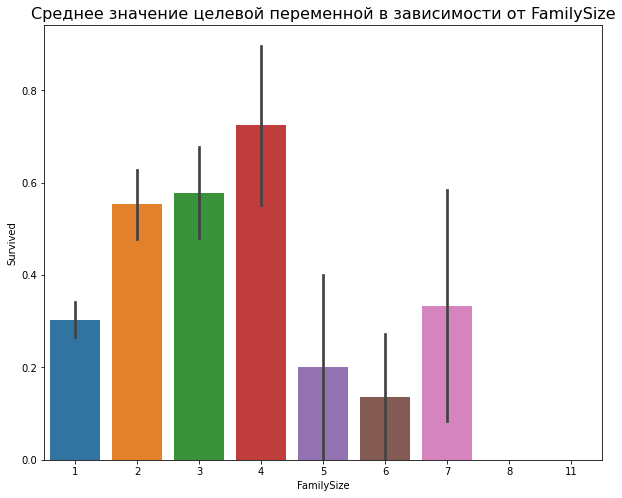
Можно строить более сложные диаграммы для среднего, добавляя разрез по признакам. Для этого нужно добавить параметр `hue``. Изучим пример для среза по классу каюты:
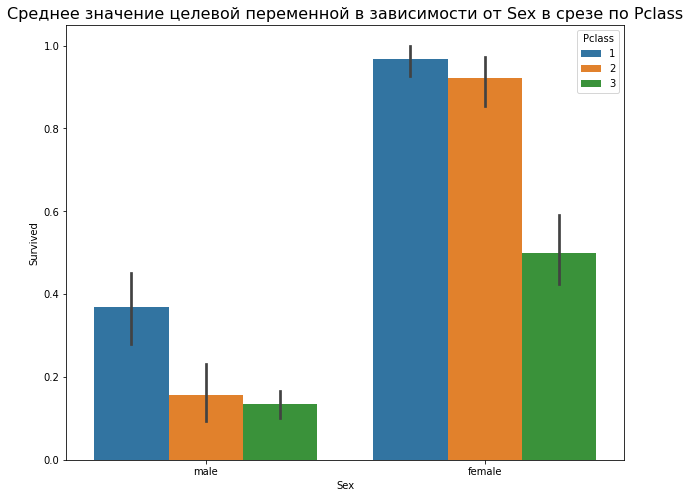
Ящики с усами
Более детальный статистический анализ можно провести с помощью метода boxplot():
Этот метод отрисовывает график под названием «ящики с усами». Ящик показывает наиболее вероятные значения, а усы дают представление о разбросе. Это удобный способ определить выбросы — значения, которые выходят за границы усов, маловероятны и могут указывать на ошибки. Посмотрим, как выглядит сам график:
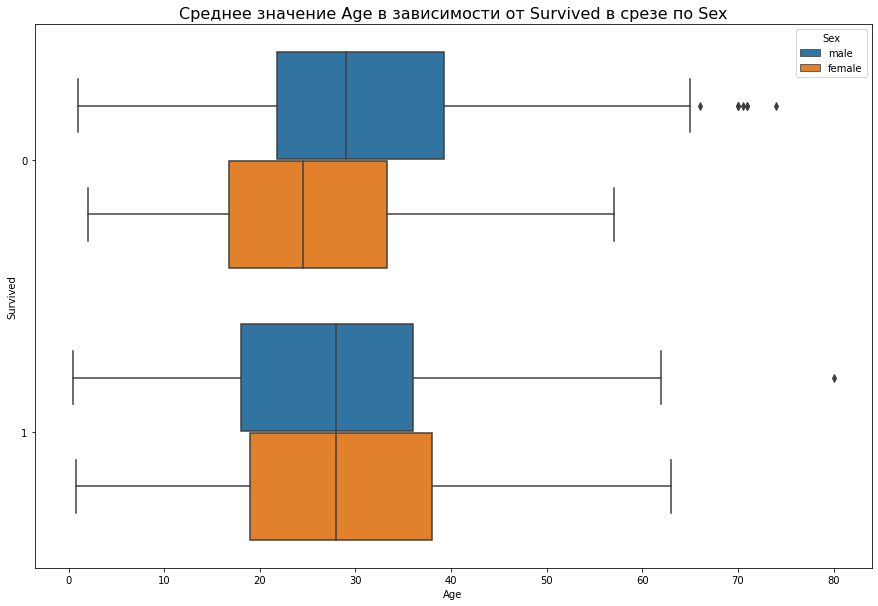
Обратите внимание на точки, не попавшие в границы усов — там могут быть ошибки, поэтому лучше проверить эти данные.
Скрипичные графики
Для дополнительного отображения формы распределения используют метод violinplot(). Его следует читать по аналогии с boxplot():
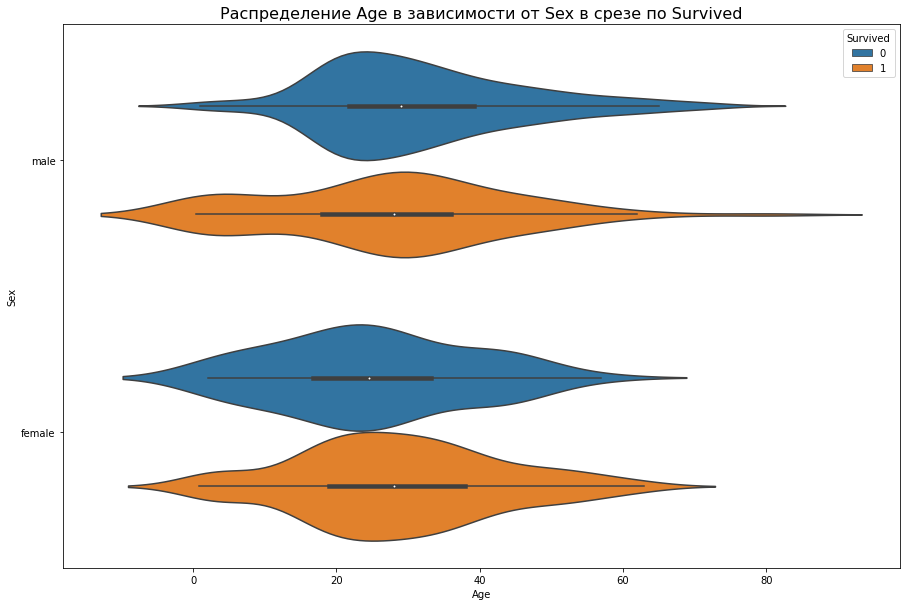
Гистограммы
Для анализа характера распределения значений используют гистограммы. По ним можно судить о типе распределения, его значениях среднего, разброса и скошенности. Эта информация используется для дальнейшей подготовки данных в методах машинного обучения. Для построения гистограммы используем метод displot():
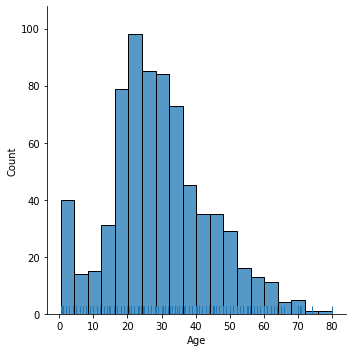
Попарные графики
Оценка влияния признаков на целевую переменную является основной целью анализа. Но взаимосвязь признаков друг с другом также несет важную информацию. На ее основе могут приниматься решения о формировании новых признаков или же наоборот удалении зависимых признаков как избыточных и влияющих на качество предиктивных моделей.
Для построения попарных графиков для всех признаков датасета используется метод pairplot():
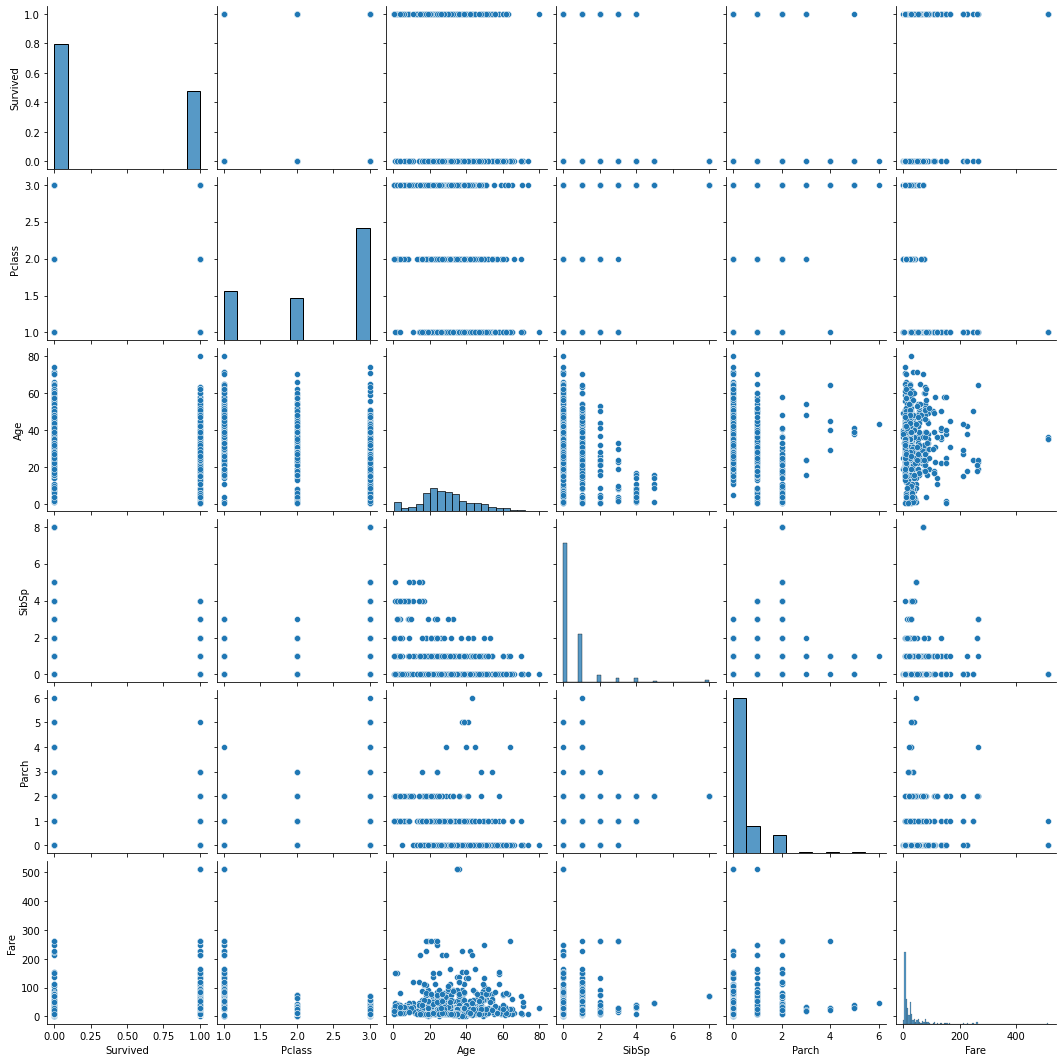
Тепловые карты
Представление многомерных данных в виде плоской картинки — довольно непростая задача, потому что плоскость ограничивается только двумя измерениями. Для введения еще одного измерения используется цветовая дифференциация и тепловые карты.
Для построения тепловой карты в Seaborn существует метод heatmap(). Попробуем составить карту вероятности выживания в зависимости от размера семьи и пола пассажира:

Ниже пример для зависимости от признаков is_alone и Sex:
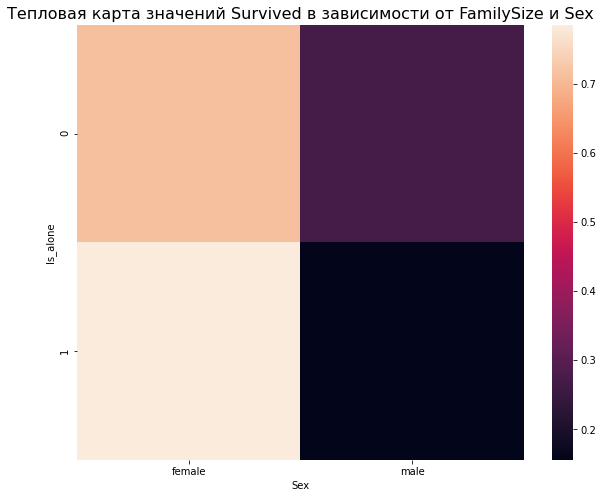
Самые светлые и темные области тепловой карты говорят о явной зависимости целевой переменной для конкретного квадрата — пары соответствующих значений признаков.
Выводы
В этом уроке мы реализовали основные графики, который аналитик использует в своей работе. На практическом примере разобрали, в каких случаях стоит применять:
- Частотные графики
- Диаграммы
- Ящики с усами
- Скрипичные графики
- Гистограммы
- Тепловые карты
- Попарные графики
Визуализация данных позволила выдвинуть ряд гипотез о качестве данных и закономерностях в них. Результаты этого урока могут использоваться как отчетный материал по первичному анализу данных.




