'%3e%3cpath%20d='M13.1407%204.34375L9.12548%205.80383L6.93536%209.45402L4.38023%205.80383L0.365019%204.34375L5.11027%2011.6441L0%2019.6745H2.92015L6.57034%2013.8342L10.5856%2019.6745H13.5057L8.39544%2011.6441L13.1407%204.34375ZM17.1559%2012.0091C17.5209%2010.5491%2018.981%209.089%2020.8061%209.089C22.6312%209.089%2024.0913%2010.5491%2024.4563%2012.0091H17.1559ZM20.8061%206.89888C17.1559%206.89888%2014.2357%209.81904%2014.2357%2013.4692C14.2357%2017.4844%2017.1559%2020.0396%2020.8061%2020.0396C23.3612%2020.0396%2025.9164%2018.5795%2027.0114%2016.0244H24.0913C23.7262%2017.1194%2022.2662%2017.8495%2020.8061%2017.8495C18.616%2017.8495%2017.1559%2016.3894%2016.7909%2014.1993H27.0114C27.3764%2010.1841%2024.8213%206.89888%2020.8061%206.89888ZM40.8821%207.2639H37.597L32.1217%2012.7392V7.2639H29.5665V19.6745H32.1217V13.8342L38.327%2019.6745H41.6122L35.0418%2013.1042L40.8821%207.2639ZM48.5475%209.45402C50.0076%209.45402%2051.4677%2010.1841%2051.8327%2011.6441H54.3878C54.0228%208.72398%2051.4677%206.89888%2048.5475%206.89888C44.5323%206.89888%2041.9772%209.81904%2041.9772%2013.4692C41.9772%2017.1194%2044.5323%2020.0396%2048.1825%2020.0396C51.1027%2020.0396%2054.0228%2018.2145%2054.3878%2015.2943H51.8327C51.4677%2016.7544%2050.0076%2017.4844%2048.1825%2017.4844C45.9924%2017.4844%2044.5323%2016.0244%2044.5323%2013.4692C44.5323%2011.2791%2045.9924%209.45402%2048.5475%209.45402ZM58.403%2014.5643C58.038%2017.1194%2057.673%2017.4844%2056.2129%2017.4844H55.4829V20.0396H56.943C58.7681%2020.0396%2060.2281%2018.5795%2060.9582%2014.9293L61.6882%209.81904H66.0684V19.6745H68.6236V7.2639H59.4981L58.403%2014.5643ZM73.7338%2012.0091C74.4639%2010.5491%2075.5589%209.089%2077.7491%209.089C79.5742%209.089%2080.6692%2010.5491%2081.0342%2012.0091H73.7338ZM77.7491%206.89888C73.7338%206.89888%2071.1787%209.81904%2071.1787%2013.4692C71.1787%2017.4844%2073.7338%2020.0396%2077.7491%2020.0396C80.3042%2020.0396%2082.8593%2018.5795%2083.5894%2016.0244H81.0342C80.3042%2017.1194%2079.2091%2017.8495%2077.7491%2017.8495C75.5589%2017.8495%2074.0989%2016.3894%2073.7338%2014.1993H83.9544C84.3194%2010.1841%2081.7643%206.89888%2077.7491%206.89888ZM91.9848%207.2639H85.4145V9.81904H89.4297V19.6745H91.9848V9.81904H96V7.2639H91.9848Z'%20fill='%231D1D1B'%20/%3e%3cpath%20d='M13.1429%202.51607L6.93753%20-0.0390625L0.367188%202.51607L6.93753%204.70618L13.1429%202.51607Z'%20fill='%23136EF6'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_139_18360'%3e%3crect%20width='96'%20height='24'%20fill='%23fff'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Python: Визуализация данных
Теория: Введение в визуализацию данных
В этом курсе мы разберем библиотеки языка Python для визуализации данных. Это инструментарий аналитика, который позволяет:
- Смотреть на данные за длительный период в емкой форме
- Обнаруживать зависимости и тренды в данных
- Находить ошибки в данных и нехарактерные значения
- Исследовать статистические характеристики данных
- Строить различные гипотезы о данных перед их дальнейшим аналитическим подтверждением
После обучения вы сможете анализировать ваши данные с использованием популярных библиотек:
- Matplotlib
- Seaborn
- Plotly
В этом уроке мы разберем, по каким причинам аналитики используют указанные библиотеки, и как выглядит типичный порядок работы с ними.
Визуализация в анализе данных
Когда мы передаем информацию третьим лицам, нам часто не хватает места и времени для ее демонстрации. В таких случаях мы подаем информацию в графическом виде — например, составляем презентацию с инфографикой для доклада выступления на конференции.
Качественная презентация позволяет:
- Увидеть тренды изменения показателей компаний, рост или убывание прибыли
- Провести сравнительный анализ при переходе от одной стратегии развития бизнеса к другой
- Подчеркнуть зависимость одних показателей от других
Еще с помощью инструментов для визуализации можно посчитать статистические показатели или сделать агрегацию данных — допустим, найти сумму месячной прибыли по дневным показателям. Также эти инструменты позволяют построить графики и диаграммы самих данных или их агрегаций.
Аналитики должны обладать всеми перечисленными навыками. В рамках курса мы подробнее остановимся на последнем — построении графиков и диаграмм. Мы будем визуализировать данные с помощью библиотек языка Python.
Существует множество готовых открытых и коммерческих решений для аналитики. Но Python — это один из самых распространенных языков для решения задач, связанных с анализом данных и машинным обучением. Освоив Python, аналитик получает мощный инструмент, который помогает получать, обрабатывать и анализировать данные.
Библиотеки визуализации и типы графиков
Для визуализации данных на языке Python используют библиотеки:
- Matplotlib
- Seaborn
- Plotly
Matplotlib — это одна из первых библиотек языка Python, разработанная для визуализации данных. У нее гибкая конфигурация свойств и широкий спектр графиков, который покрывает востребованные аналитические задачи. Среди них наиболее популярны:
- Линейные графики
- Столбчатые и круговые диаграммы
- Гистограммы
Все эти графики можно построить с помощью Pyplot, специального модуля для Matplotlib. В коде название модуля Pyplot часто сокращается до plt. Рассмотрим построение каждого из графиков подробнее.
Строим линейные графики
Для начала построим линейный график с помощью метода plot():
В итоге мы получим такой график:
Строим столбчатые и круговые диаграммы
Для сравнительного анализа показателей используют столбчатые и круговые диаграммы. Построим круговой график:
Изучим получившуюся диаграмму. Весь круг — это общее количество фруктов в магазине. Сектора этого круга показывают отдельно количество яблок, бананов, апельсинов и винограда в процентах:
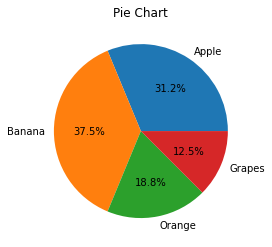
По этой диаграмме мы можем визуально оценить относительные показатели, даже не зная конкретного количества фруктов.
Строим гистограмму
Чтобы проанализировать распределение величин в данных, используют гистограмму — это график частоты встречаемости значений или частоты попадания значений в определенный числовой интервал.
Перейдем к примеру:
Здесь мы дополнительно используем библиотеку NumPy для генерации случайной последовательности. В этом курсе мы будем иногда использовать конструкции NumPy, потому что библиотеки по визуализации данных используют ее в своих методах.
В итоге мы получим такую визуализацию:
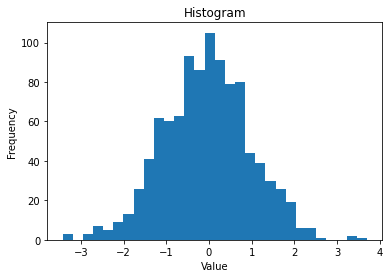
Здесь каждый столбец — это количество значений, которые попадают в соответствующий интервал, отложенный на горизонтальной оси. В качестве параметра bins мы указали, что хотим взять отрезок со всеми значениями и разбить его на 30 равных частей. Так на рисунке появился 30 столбцов.
Использование Matplotlib осложняется тем, что необходимо понимать ее внутреннее устройство: иерархию объектов и их методы. Чтобы облегчить задачу, поверх Matplotlib мы будем использовать библиотеки Seaborn и Plotly, более простые в использовании.
Строим гистограмму в Seaborn и Plotly
Построение гистограммы в Seaborn выглядит так:
Результат аналогичен построению в Matplotlib:
Код для Plotly тоже достаточно лаконичен:
Библиотека Plotly отличается от других интерактивностью. Например, построенные с ее помощью графические объекты могут изменять масштаб и подсвечивать значения в конкретных точках.
Выводы
Визуализация данных — это один из необходимых инструментов, которым должен владеть аналитик данных. Она позволяет обозревать большие объемы данных, что актуально для современных аналитических задач. В этом уроке мы познакомились с библиотеками языка Python для визуализации данных:
- Matplotlib
- Seaborn
- Plotly
С их помощью построили графики, которые часто используются аналитиками на практике:
- Линейные графики
- Гистограммы
- Столбчатые и круговые диаграммы
Далее мы погрузимся в основные возможности этих библиотек и все нюансы их использования.




