'%3e%3cpath%20d='M13.1407%204.34375L9.12548%205.80383L6.93536%209.45402L4.38023%205.80383L0.365019%204.34375L5.11027%2011.6441L0%2019.6745H2.92015L6.57034%2013.8342L10.5856%2019.6745H13.5057L8.39544%2011.6441L13.1407%204.34375ZM17.1559%2012.0091C17.5209%2010.5491%2018.981%209.089%2020.8061%209.089C22.6312%209.089%2024.0913%2010.5491%2024.4563%2012.0091H17.1559ZM20.8061%206.89888C17.1559%206.89888%2014.2357%209.81904%2014.2357%2013.4692C14.2357%2017.4844%2017.1559%2020.0396%2020.8061%2020.0396C23.3612%2020.0396%2025.9164%2018.5795%2027.0114%2016.0244H24.0913C23.7262%2017.1194%2022.2662%2017.8495%2020.8061%2017.8495C18.616%2017.8495%2017.1559%2016.3894%2016.7909%2014.1993H27.0114C27.3764%2010.1841%2024.8213%206.89888%2020.8061%206.89888ZM40.8821%207.2639H37.597L32.1217%2012.7392V7.2639H29.5665V19.6745H32.1217V13.8342L38.327%2019.6745H41.6122L35.0418%2013.1042L40.8821%207.2639ZM48.5475%209.45402C50.0076%209.45402%2051.4677%2010.1841%2051.8327%2011.6441H54.3878C54.0228%208.72398%2051.4677%206.89888%2048.5475%206.89888C44.5323%206.89888%2041.9772%209.81904%2041.9772%2013.4692C41.9772%2017.1194%2044.5323%2020.0396%2048.1825%2020.0396C51.1027%2020.0396%2054.0228%2018.2145%2054.3878%2015.2943H51.8327C51.4677%2016.7544%2050.0076%2017.4844%2048.1825%2017.4844C45.9924%2017.4844%2044.5323%2016.0244%2044.5323%2013.4692C44.5323%2011.2791%2045.9924%209.45402%2048.5475%209.45402ZM58.403%2014.5643C58.038%2017.1194%2057.673%2017.4844%2056.2129%2017.4844H55.4829V20.0396H56.943C58.7681%2020.0396%2060.2281%2018.5795%2060.9582%2014.9293L61.6882%209.81904H66.0684V19.6745H68.6236V7.2639H59.4981L58.403%2014.5643ZM73.7338%2012.0091C74.4639%2010.5491%2075.5589%209.089%2077.7491%209.089C79.5742%209.089%2080.6692%2010.5491%2081.0342%2012.0091H73.7338ZM77.7491%206.89888C73.7338%206.89888%2071.1787%209.81904%2071.1787%2013.4692C71.1787%2017.4844%2073.7338%2020.0396%2077.7491%2020.0396C80.3042%2020.0396%2082.8593%2018.5795%2083.5894%2016.0244H81.0342C80.3042%2017.1194%2079.2091%2017.8495%2077.7491%2017.8495C75.5589%2017.8495%2074.0989%2016.3894%2073.7338%2014.1993H83.9544C84.3194%2010.1841%2081.7643%206.89888%2077.7491%206.89888ZM91.9848%207.2639H85.4145V9.81904H89.4297V19.6745H91.9848V9.81904H96V7.2639H91.9848Z'%20fill='%231D1D1B'%20/%3e%3cpath%20d='M13.1429%202.51607L6.93753%20-0.0390625L0.367188%202.51607L6.93753%204.70618L13.1429%202.51607Z'%20fill='%23136EF6'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_139_18360'%3e%3crect%20width='96'%20height='24'%20fill='%23fff'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Python: Визуализация данных
Теория: Упрощение работы с Seaborn
Библиотека Matplotlib предоставляет широкий спектр методов визуализации данных. Аналитики часто прибегают к ней в своей работе. Данная библиотека имеет низкоуровневую реализацию, что дает возможность тонкой настройки всех параметров отрисовки графиков и диаграмм. Однако за это приходится платить большим количеством шаблонных кодовых структур, что может быть излишним при решении типичных задач.
Для облегчения визуализации часто используемых графиков и диаграмм вместо Matplotlib используют библиотеку Seaborn. Эта библиотека специально создана для уменьшения объема кода и, тем самым, увеличения скорости разработки аналитических решений. На этом уроке мы познакомимся с некоторыми наиболее популярными графиками библиотеки Seaborn:
- реляционными и регрессионными
- распределениями данных и статистических показателей
- совместными распределениями и попарными отношениями
- тепловыми картами
Для работы будем использовать датасеты, которые поставляются вместе с Seaborn при установке. И начнем с простых графиков для анализа отношений между нескольками показателями в табличных данных.
Реляционные графики
Для работы возьмем табличный датасет tips. Это записи о величине чаевых, которые оставляли посетители кафе. В качестве дополнительной информации приведены пол посетителя, день недели, время посещения и другие.
Будем использовать устоявщееся сокращение sns. Выше мы загрузили датасет в формате pandas.DataFrame библиотеки pandas.
Воспользуемся методом sns.relplot() для нанесения на координатную плоскость точек, где по горизонтальной оси отложим значения итогового чека total_bill, а по вертикальной - размер чаевых tip.
Для дополнительной информации точки раскрасим в соответствии с днем недели.
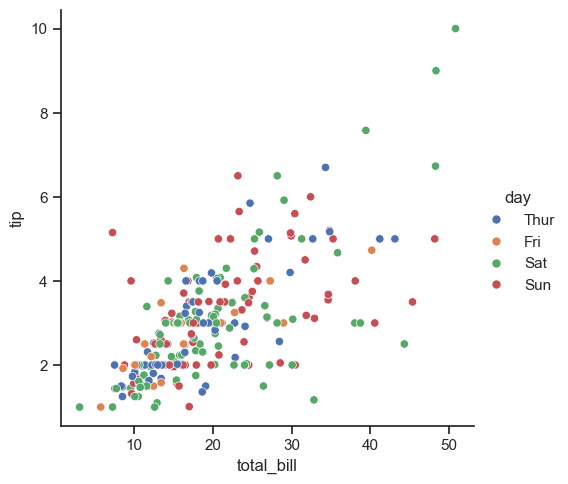
В кодовой строке выше мы указали датафрейм tips в качестве data параметра, а все необходимые настройки передавали в виде названия соответствующих столбцов.
Данный тип графиков можно усложнять, добавляя разрезы по столбцам. В качестве примера мы сделаем разрез по времени time.
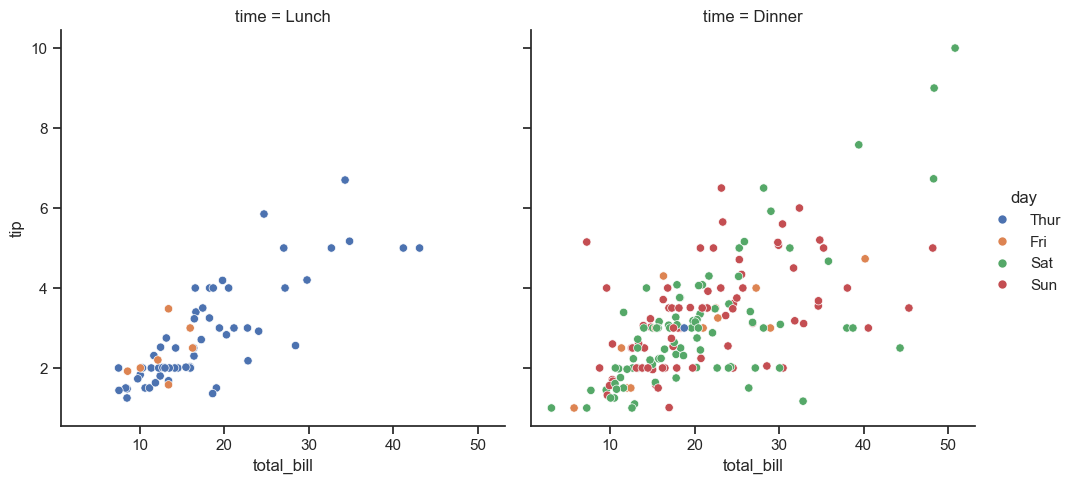
Данный подход позволил нам на одном холсте отрисовать 2 графика зависимости показателей чека и чаевых в зависимости от времени посещения кафе.
В случае, если требуется отображать всю информацию на 1 графике, можно воспользоваться методом построения точечных графиков sns.scatterplot().
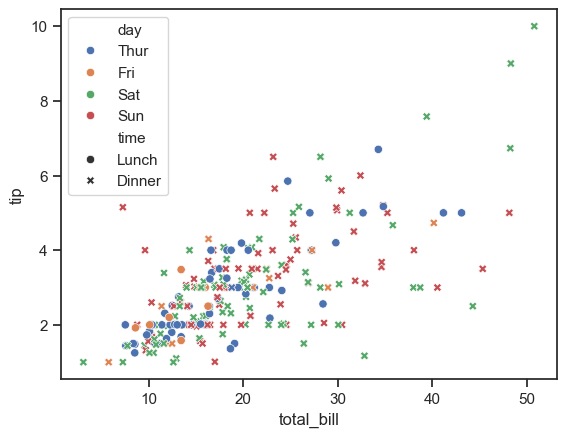
В данном случае время посещения кафе отображается стилем точек на графике.
Указанные выше типы графиков используются аналитиками для оценки зависимостей в данных. Цвета и стили точек показывают группировку в данных, а также пересечения разных групп в разрезе времени или дня недели. На таких графиках часто можно увидеть зависимости линейного характера, когда увеличение или уменьшение одного показателя приводит к соответствующему увеличению или уменьшению другого. В этом случае используют регрессионные графики.
Регрессионные графики
Для построения регрессионных графиков необходимо воспользоваться методом sns.lmplot().
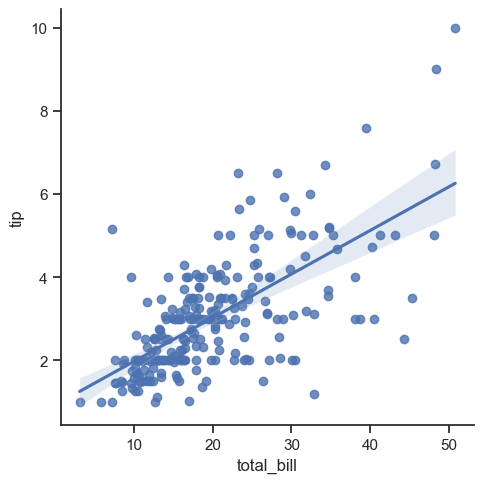
Как и на графиках выше, мы получили точки на графике, но при этом дополнительно появилась прямая, которая проведена "по середине" между точками. Для ее построения решается специальная задача минимизации суммарной удаленности точек от проводимой прямой. Область полутени рядом с прямой демонстрирует разброс ошибок при построении регрессии. Чем уже данная область, тем более точно построена прямая регрессии и тем сильнее линейная зависимость между показателями.
Дополнительно прибегают к построению регрессии в разрезе еще какого-либо параметра. В коде ниже покажем это в разрезе признака smoker курящего и некурящего гостя.

Можно также добавить расределения значений на один график с регрессией. Так мы будем понимать характер распределения наших признаков и их статистические характеристики.
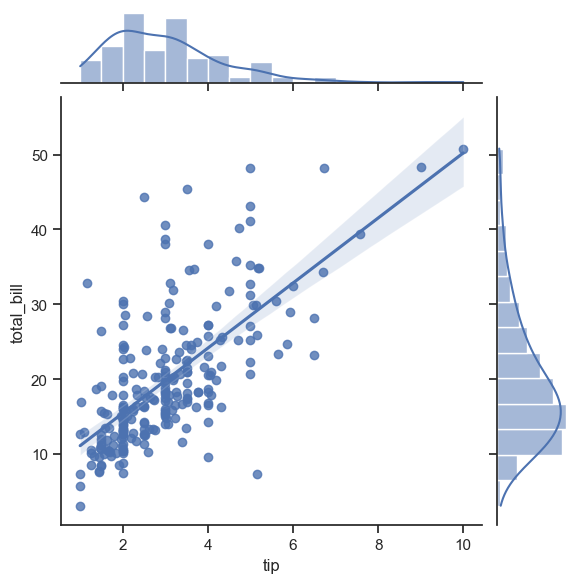
Мы рассмотрели подходы к совместным распределениям для двух признаков. Далее посмотрим, как это сделать сразу со всеми признаками данных.
Анализ совместных распределений и попарных отношений
Загрузим датасет классификации цветков ириса по 4 метрическим параметрам.
Построим попарные графики для каждой пары признаков в данных
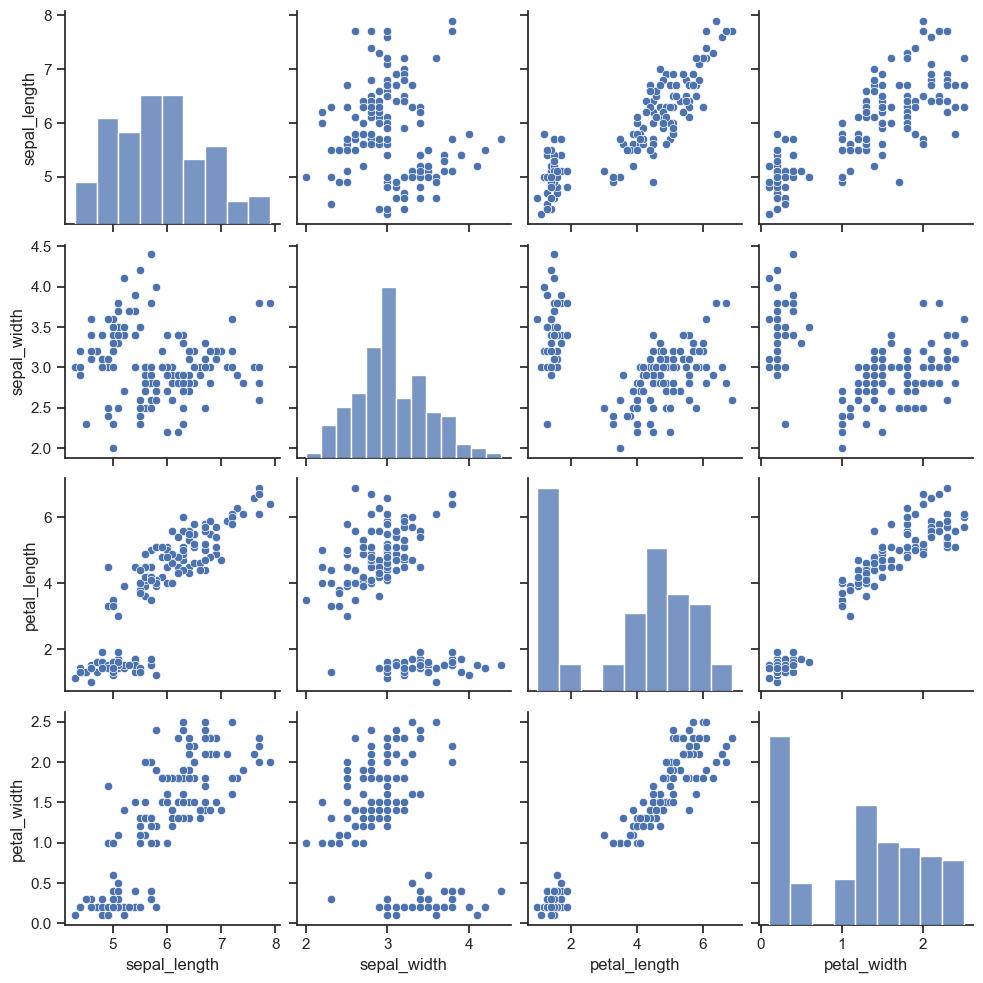
На рисунке по диагонали расположились гистограммы распределений каждого признака, а на остальных местах точечные графики для пар признаков.
Реляционные графики, регрессионный анализ и совместные распределения демонстрируют характер попарной зависимости признаков в данных. Следующим инструментом, который характеризует данные в целом, является статистический анализ. Далее мы посмотрим на доступные функции Seaborn для работы с ним.
Статистические характеристики данных
Для демонстрациии воспользуемся датасетом titanic, хранящем информацию о пассажирах затонувшего Титаника.
Данный датасет достаточно богат на признаки, более подробно о нем можно прочитать в документации.
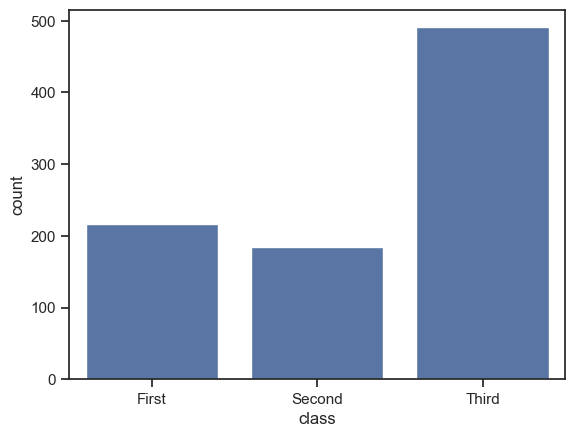
Мы начнем анализ с простого подсчета каждой категории билетов пассажиров. Воспользуемся методом sns.countplot().
Продолжим со столбчатыми диаграммами. Посмотрим на средний возраст пассажиров каждого класса в разрезе пола. Для этого будем использовать метод sns.barplot().
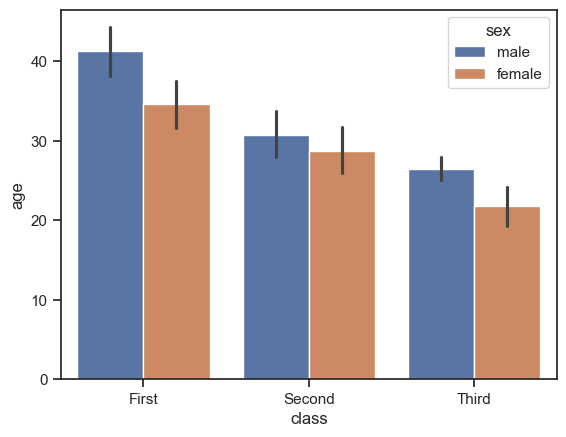
На графике выше помимо средних значений отрисовываются вертикальные штрихи. Это отклонение значений возраста от среднего. Чем длиннее штрих, тем больше разброс возраста.
Для анализа среднего, разброса и поиска выбросов удобно использовать "ящики с усами" и "виолончели". Посмотрим на первый вариант.
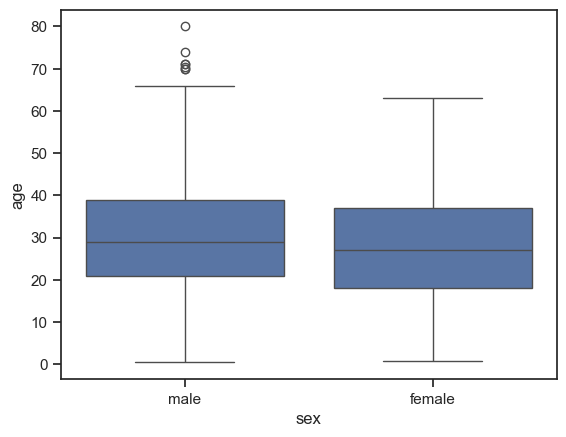
На диаграмме выше границы синего ящика описывают интервал, в который попадает наибольшее число значений возраста. Отходящие вверх и вниз от ящика "усы" показывают границы, в которых лежат практически все наблюдаемые значения. Если же значения выходят за пределы "усов", то это показатель того, что они маловероятны. Возможно это ошибка в данных - аналитик обязан обратить на это внимание.
В случае с виолончелью отрисовывается концентрация значений для определенного возраста: где виолончель шире, туда попадает наибольшее количество значений.
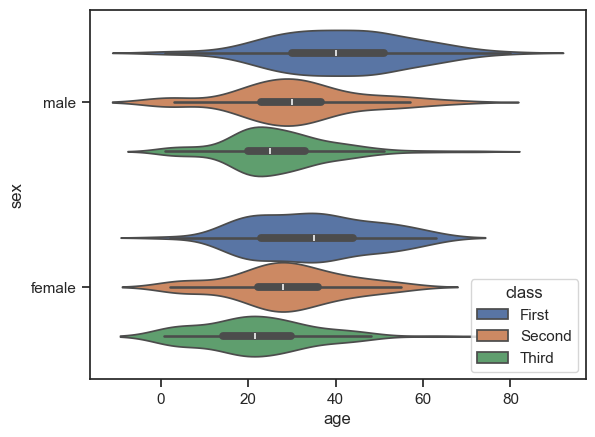
Для отображения распределения значений используется метод sns.displot().
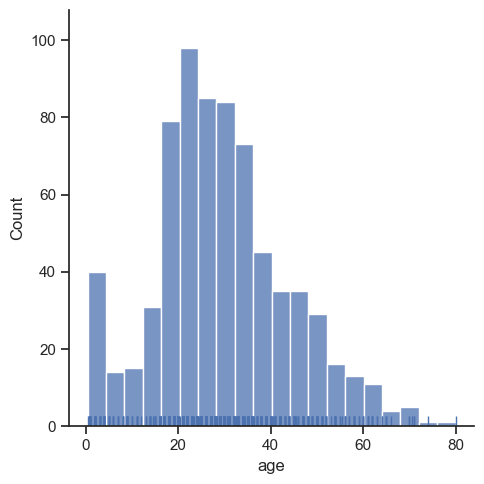
Гистограмма выше подсказывает аналитику о характере распределения значений и их концентрации. Позволяет выдвинуть гипотезы о типе распределения и его характеристиках.
Для анализа статистических характеристик исходных данных удобно использовать указанные выше методы. Однако иногда необходимо проанализировать и подсветить минимальные и максимальные значения признаков. Для этого используют тепловые карты.
Тепловые карты
Для примера сперва соберем сводную таблицу, в которой найдем количество пассажиров определенного пола и класса билета.
Далее будем использовать метод sns.heatmap(), которым раскрасим полученную таблицу.
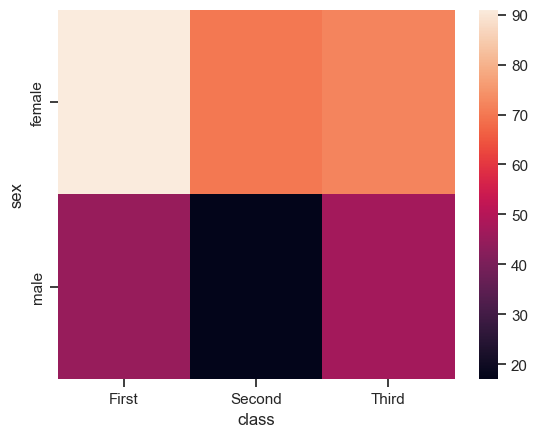
На рисунке выше мы подсвечиваем изменения значений от меньшего к большему оттенками от темного к светлому.
Выводы
На уроке мы познакомились с наиболее употребимыми типами графиков библиотеки Seaborn. Основной акцент был сделан на локаничности кода: многие графики строились в одну строку. На тестовых датасетах мы познакомились с
- реляционными и регрессионными графиками для визуализации и анализа взаимосвязи между показателями в данных
- типами графиков для визуализации распределейний и статистических показателей
- совместными распределениями и попарными отношениям
- тепловыми картами для упрощения чтения численных показателей в данных
Однако функционал библиотеки Seaborn гораздо шире. Для углубления знаний можно обратиться к документации Seaborn.




