'%3e%3cpath%20d='M13.1407%204.34375L9.12548%205.80383L6.93536%209.45402L4.38023%205.80383L0.365019%204.34375L5.11027%2011.6441L0%2019.6745H2.92015L6.57034%2013.8342L10.5856%2019.6745H13.5057L8.39544%2011.6441L13.1407%204.34375ZM17.1559%2012.0091C17.5209%2010.5491%2018.981%209.089%2020.8061%209.089C22.6312%209.089%2024.0913%2010.5491%2024.4563%2012.0091H17.1559ZM20.8061%206.89888C17.1559%206.89888%2014.2357%209.81904%2014.2357%2013.4692C14.2357%2017.4844%2017.1559%2020.0396%2020.8061%2020.0396C23.3612%2020.0396%2025.9164%2018.5795%2027.0114%2016.0244H24.0913C23.7262%2017.1194%2022.2662%2017.8495%2020.8061%2017.8495C18.616%2017.8495%2017.1559%2016.3894%2016.7909%2014.1993H27.0114C27.3764%2010.1841%2024.8213%206.89888%2020.8061%206.89888ZM40.8821%207.2639H37.597L32.1217%2012.7392V7.2639H29.5665V19.6745H32.1217V13.8342L38.327%2019.6745H41.6122L35.0418%2013.1042L40.8821%207.2639ZM48.5475%209.45402C50.0076%209.45402%2051.4677%2010.1841%2051.8327%2011.6441H54.3878C54.0228%208.72398%2051.4677%206.89888%2048.5475%206.89888C44.5323%206.89888%2041.9772%209.81904%2041.9772%2013.4692C41.9772%2017.1194%2044.5323%2020.0396%2048.1825%2020.0396C51.1027%2020.0396%2054.0228%2018.2145%2054.3878%2015.2943H51.8327C51.4677%2016.7544%2050.0076%2017.4844%2048.1825%2017.4844C45.9924%2017.4844%2044.5323%2016.0244%2044.5323%2013.4692C44.5323%2011.2791%2045.9924%209.45402%2048.5475%209.45402ZM58.403%2014.5643C58.038%2017.1194%2057.673%2017.4844%2056.2129%2017.4844H55.4829V20.0396H56.943C58.7681%2020.0396%2060.2281%2018.5795%2060.9582%2014.9293L61.6882%209.81904H66.0684V19.6745H68.6236V7.2639H59.4981L58.403%2014.5643ZM73.7338%2012.0091C74.4639%2010.5491%2075.5589%209.089%2077.7491%209.089C79.5742%209.089%2080.6692%2010.5491%2081.0342%2012.0091H73.7338ZM77.7491%206.89888C73.7338%206.89888%2071.1787%209.81904%2071.1787%2013.4692C71.1787%2017.4844%2073.7338%2020.0396%2077.7491%2020.0396C80.3042%2020.0396%2082.8593%2018.5795%2083.5894%2016.0244H81.0342C80.3042%2017.1194%2079.2091%2017.8495%2077.7491%2017.8495C75.5589%2017.8495%2074.0989%2016.3894%2073.7338%2014.1993H83.9544C84.3194%2010.1841%2081.7643%206.89888%2077.7491%206.89888ZM91.9848%207.2639H85.4145V9.81904H89.4297V19.6745H91.9848V9.81904H96V7.2639H91.9848Z'%20fill='%231D1D1B'%20/%3e%3cpath%20d='M13.1429%202.51607L6.93753%20-0.0390625L0.367188%202.51607L6.93753%204.70618L13.1429%202.51607Z'%20fill='%23136EF6'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_139_18360'%3e%3crect%20width='96'%20height='24'%20fill='%23fff'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Python: Визуализация данных
Теория: Визуализация статистических данных
Графическое представление статистических значений и распределений дает аналитику возможность извлекать значимые характеристики из больших объемов данных. В этом уроке мы рассмотрим основные графики и диаграммы, которые используются аналитиками в своей работе, а именно:
- Гистограммы распределений —
hist - Ящики с усами —
boxplot - Скрипичные графики —
violinplot - Круговые диаграммы —
pie
Импорт библиотек и подготовка данных
Для работы нам понадобятся модули sklearn.datasets для получения данных и matplotlib.pyplot для их визуализации:
В качестве данных возьмем тренировочный датасет с классификацией цветков ириса. Подробнее об этом можно прочитать в документации:
Код выше инициализирует две переменные. Переменная X отвечает за работу с характеристиками цветков. В ней обозначена длина и ширина лепестков и листочков в сантиметрах. В нашем случае есть четыре признака:
sepal length (cm)sepal width (cm)petal length (cm)petal width (cm)
Перейдем к переменной y, которая нужна для работы с классификацией цветков. У нее есть три значения (таргета), каждое число обозначает один из видов ириса:
0—setosa1—verticolor2—virginica
На датасете цветков ириса аналитики часто учатся работе с табличными данными. Далее мы проанализируем статистические характеристики признаков и количественные показатели таргетов с использованием визуализации.
Гистограмма распределения
Один из частых подходов к визуализации — это графические представление распределения данных.
Для этого подходит гистограмма, которая реализуется с использованием метода hist(). Аналитик выбирает нужно количество интервалов и задает его через значение bins. Мы выбрали значение 8:
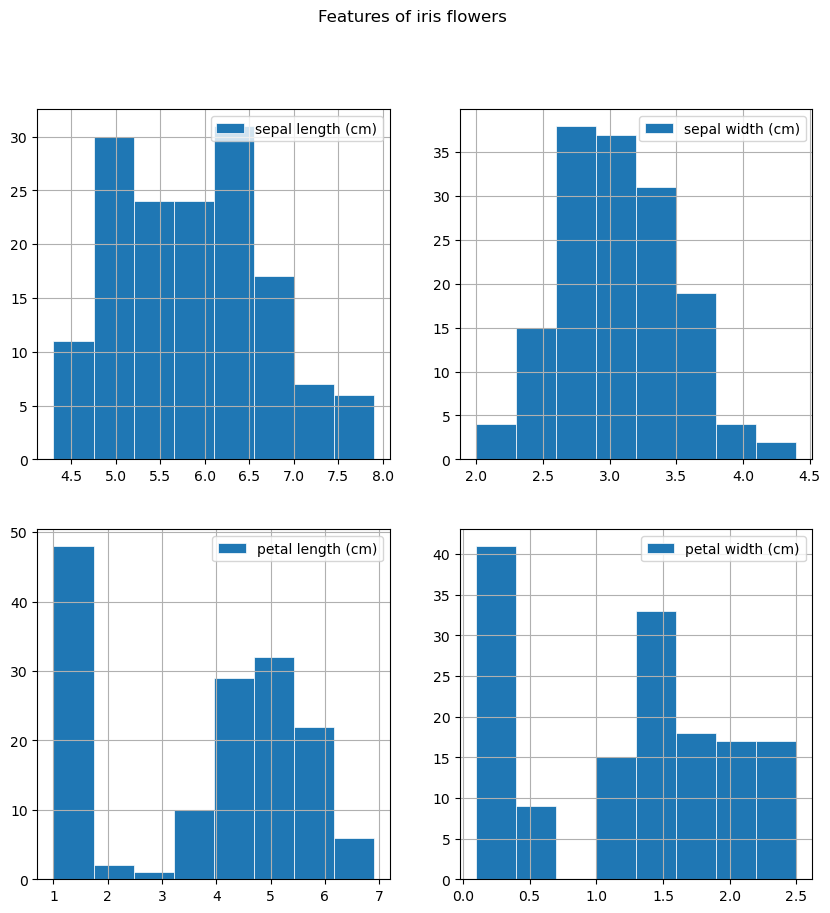
Для построения гистограммы все значения раскладываются по соответствующим числовым интервалам и подсчитывается их количество в каждом интервале. В нашем случае интервалов 8 — столько же столбцов на графике. Ширина столбца и его позиция по горизонтальной оси описывает интервал, а высота — количество значений, которые в него попали.
Код выше можно сократить, если использовать циклы. Положение каждого из признаков на соответствующей области визуализации определяется через выражения n // 2 и n % 2:
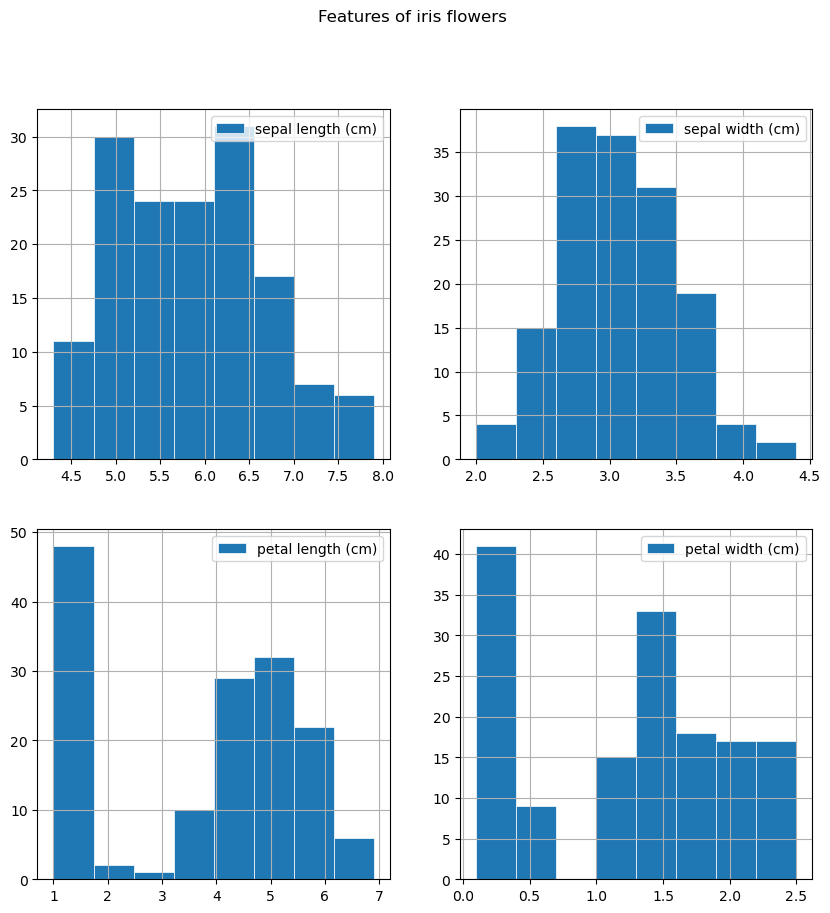
Гистограммы хорошо описывают то, какие наиболее типичные значения признаков встречаются в данных. В примере выше значения sepal width (cm) сосредоточены в районе 3.
Чтобы получить ту же информацию о квантилях и медианных значениях, построим еще один график.
Ящик с усами
Чтобы построить этот график, воспользуемся методом boxplot(). Первый необходимый параметр для него — это набор данных. В нашем случае мы используем ранее инициализированную переменную X, в которой хранятся значения признаков.
Остальные параметры отвечают за формат и расположение ящиков на области визуализации. Стоит помнить, что positions должно быть столько, сколько признаков. Мы указали четыре значения, поскольку у нас ровно четыре признака:
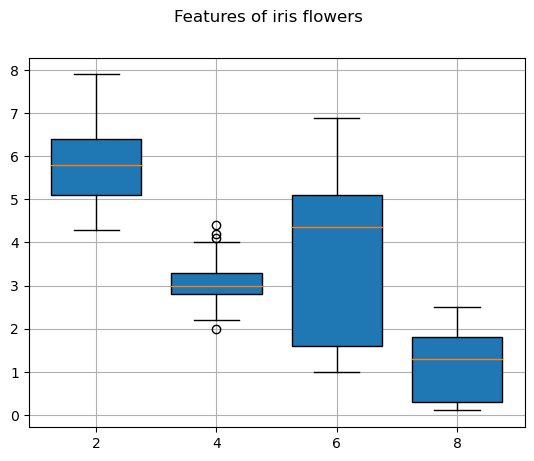
Это тип графиков читают так:
- Синий ящик — это область, в которую попадают большая часть всех значений
- Линия в ящике — значение, меньше которого столько же признаков, сколько и больше него (медиана)
- Усы — границы, в пределах которых лежат практически все признаки (вариативность признаков)
Не всегда удобно размещать признаки на одной области визуализации, потому что значения признаков могут сильно отличаться. В нашем примере этого не происходит — все значения расположены в интервале от 0 до 8. Для примера представим, что среди признаков есть зарплата работника и его возраст. В таком случае лучше выделить отдельную область под каждый признак.
Посмотрим, как сделать это с помощью циклов. При этом мы ограничиваемся каждый раз только одним признаком, вырезая его из данных вот так:
Так это выглядит на практике:
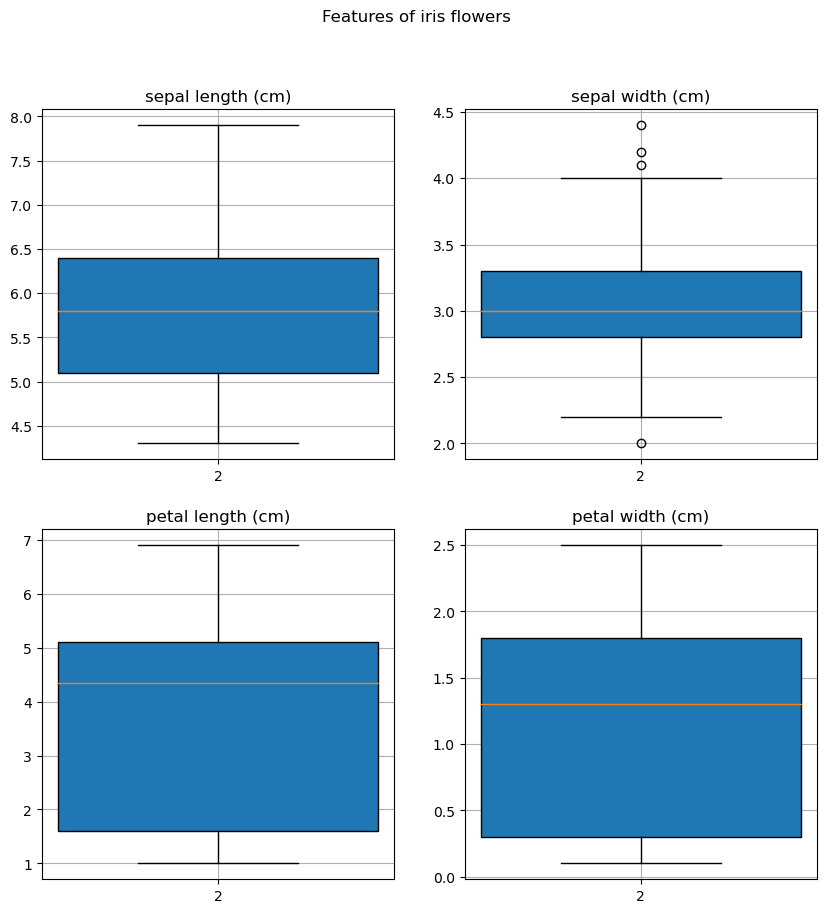
Посмотрим на графики выше. Какие-то признаки выходят за пределы усов — значит, в данных есть некоторые нехарактерные значения. Обычно аналитик находит эти значения и выясняет причину их появления — это либо редкий реальный случай, либо ошибка в данных. В нашем примере у признака sepal width (cm) наблюдаются такие значения.
Рассмотрим еще один график, который добавляет немного статистической информации о данных.
Скрипичная диаграмма
Чтобы построить этот график, заменим метод boxplot() на violinplot() в коде предыдущего примера:
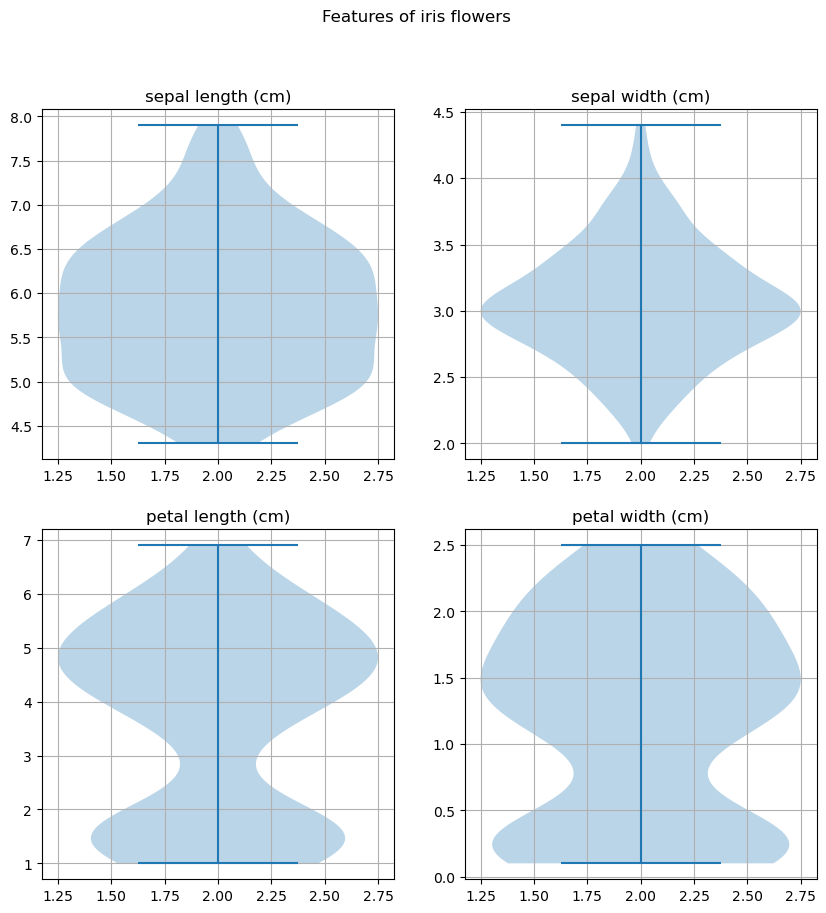
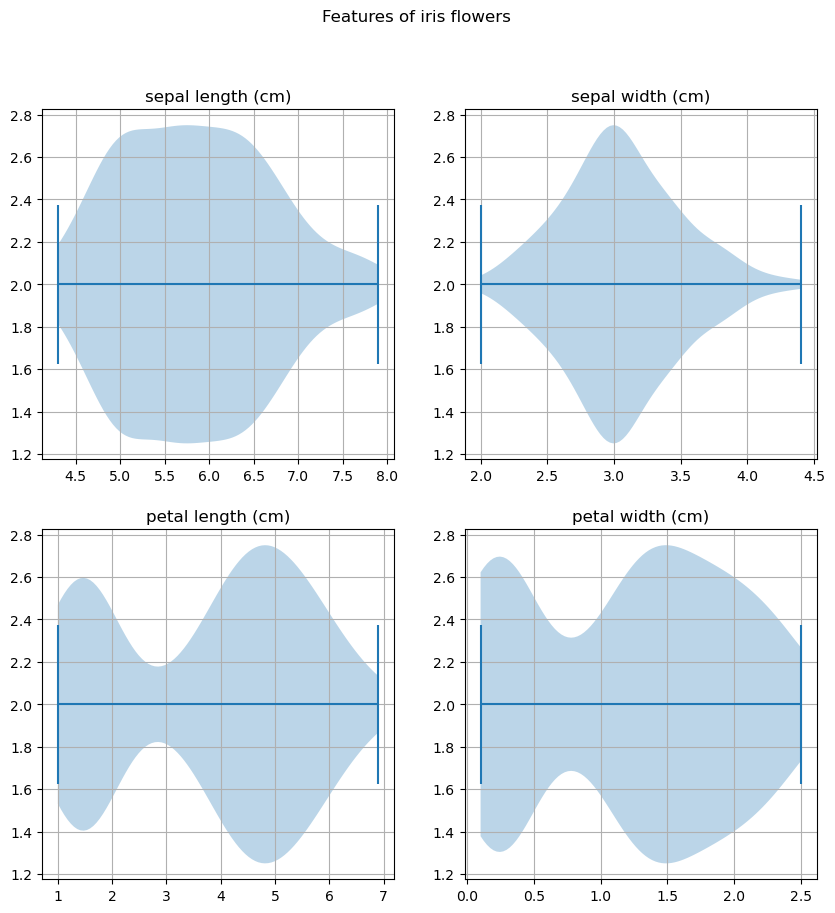
Таким образом мы строим график распределения значений. Там где он толще, туда и попадает наибольшее количество значений. Иногда этот график рассматривают горизонтально. Для этого необходимо добавить параметр vert=False:
Мы разобрались с признаками, но оставили без внимания значения целевых переменных. Поработаем и с ними с помощью круговой диаграммы.
Круговая диаграмма
Для работы с целевыми переменными мы сперва посчитаем их количество. Воспользуемся методами библиотеки Numpy:
Теперь мы можем построить круговую диаграмму. Воспользуемся методом pie(). Возьмем количество наших таргетов y_counts[:, 1] в качестве данных для отрисовки.
Зададим параметр autopct лямбда-функцией, которая формирует подписи на секторах. Этот метод можно дополнительно параметризировать положением на области визуализации и размером. Не забудем также добавить легенду для наших секторов и отрисовать ее в отдельном окошке:
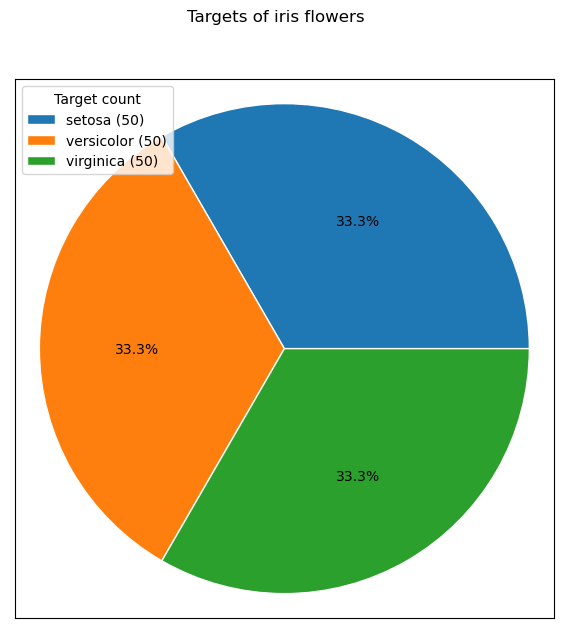
График выше показывает, сколько цветков ириса мы рассмотрели. В этом случае все классы имеют одинаковый размер по 50 штук. Размеры целевых классов существенно влияют на построение методов машинного обучения и подбор метрик качества обучаемых алгоритмов, поэтому к круговой диаграмме часто прибегают при первичном анализе данных.
Выводы
На этом уроке мы изучили методы статистического анализа данных с использованием визуализации:
- Гистограммы распределений —
hist - Ящики с усами —
boxplot - Скрипичные графики —
violinplot - Круговые диаграммы —
pie
На практических примерах разобрали, когда и как правильно применять рассмотренные методы. Это стандартный набор любого аналитика, с помощью которого можно производить первичный анализ данных, выявлять ошибки в них и даже формулировать гипотезы о их свойствах.




