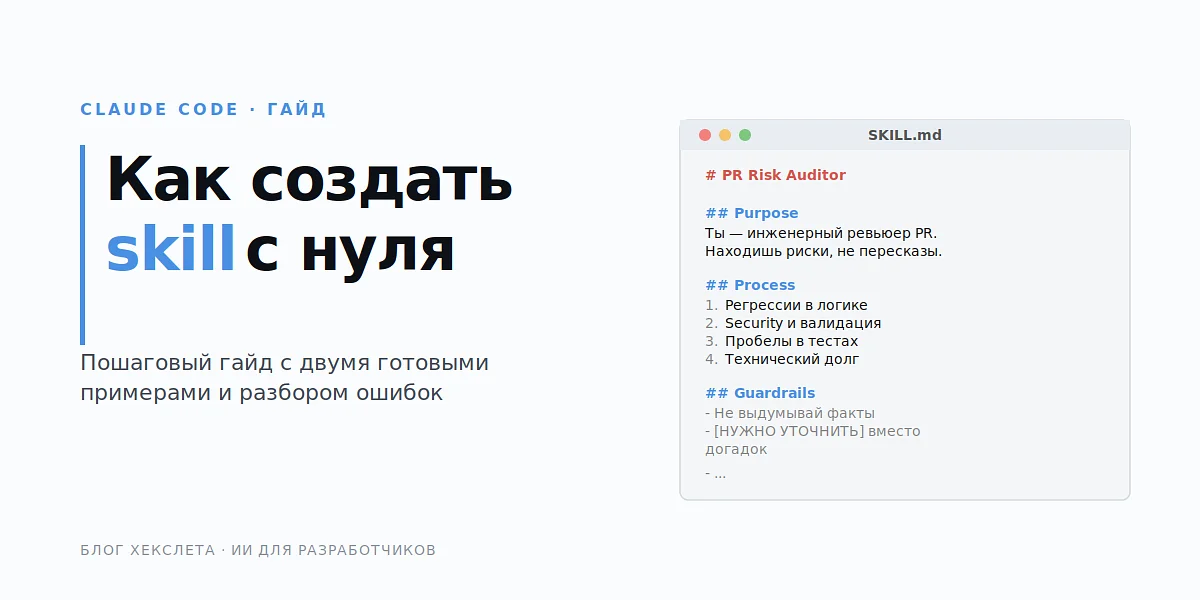
Как создать skill для Claude Code: пошаговый гайд с двумя готовыми примерами
У всех, кто долго работает с Claude Code, в какой-то момент происходит одно и то же. Сначала восторг — агент пишет код, чинит баги, проводит рефакторинг по разговору. Потом разочарование — ты в десятый раз объясняешь одни и те же правила, в пятый раз получаешь отчёт не в том формате, и в третий раз ловишь агента на том, что он переписал половину репозитория, хотя задача была «поправить опечатку».
Лечится это одним инструментом — skills. По сути, это файл с операционной инструкцией для агента: чем он сейчас занимается, что делает, что не делает, как отдаёт результат. Хороший skill превращает Claude Code из универсального помощника в специализированного инженера, который раз за разом выдаёт сопоставимое качество.
Ниже — как написать такой файл с нуля, с разбором двух полностью рабочих примеров, типичных ошибок и проверочного чек-листа перед использованием в реальной работе. Системно освоить агентный workflow помогает программа «ИИ для разработчиков» на Хекслете.
Что такое skill и почему это не просто промпт
Skill в Claude Code — это файл SKILL.md (плюс при необходимости папка с шаблонами и примерами), который агент читает перед началом задачи. Внутри: роль, входные данные, порядок действий, формат ответа, ограничения.
Модель остаётся прежней. Меняется то, как она подходит к задаче — потому что у неё теперь есть жёсткий регламент, а не свобода интерпретации.
Чтобы стало понятнее, в чём разница, вот два подхода к одной и той же задаче:
Подход 1: разовый промпт
«Посмотри PR, скажи, всё ли в порядке. Обрати внимание на безопасность, тесты и производительность».
Подход 2: skill с регламентом
Тот же запрос, но агент уже знает: какие конкретно категории проверять, в каком порядке, какой формат отчёта выдать, что считать критичным, а что — мелочью. И знает это одинаково в понедельник и в пятницу.
Разница не в качестве промпта. Разница в воспроизводимости. Skill — это процедура. Разовый промпт — это пожелание.
Когда skill действительно нужен, а когда — нет
Не каждая повторяющаяся задача заслуживает собственного skill. На написание хорошего файла уходит несколько часов, на доводку — ещё несколько дней. Если задача случается раз в месяц, эти часы не окупятся никогда.
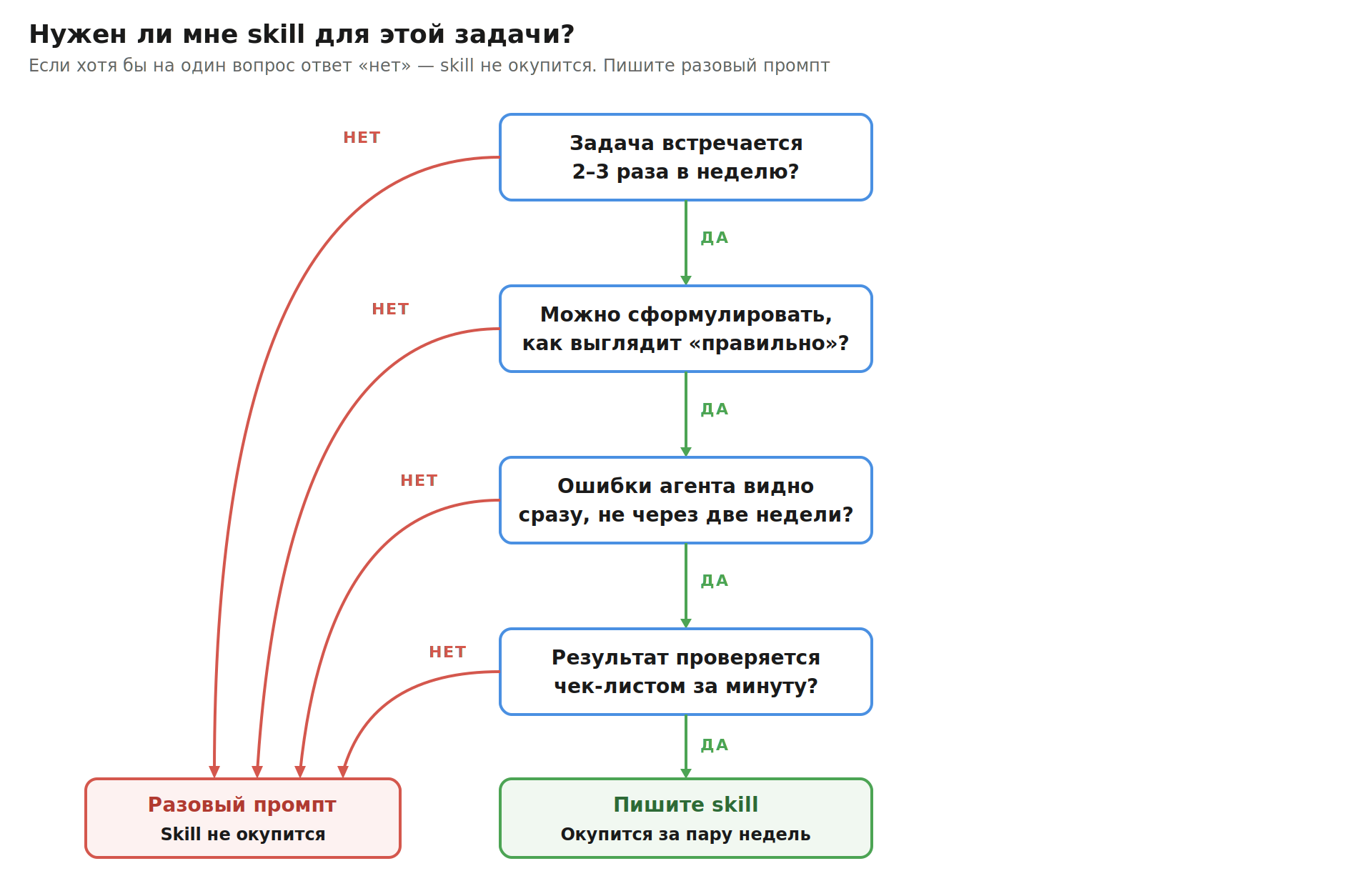
Я бы делал skill только при совпадении четырёх условий:
Условие | Что значит |
|---|---|
Частота | Задача встречается 2–3 раза в неделю или чаще |
Понятный критерий готовности | Можно объяснить, как выглядит «правильный» результат — не на пальцах, а формально |
Ошибки ловятся | Когда агент облажался, это видно сразу, а не через две недели |
Результат проверяется чек-листом | Можно пробежать по списку «есть / нет» за минуту |
Если хотя бы одного из четырёх нет — пишите разовые промпты. Это не хуже, это просто другой инструмент.
Хорошие кандидаты в skill: проверка PR, написание тестов под существующий код, миграция данных между форматами, генерация changelog из коммитов, превращение длинного материала в посты для соцсетей, оформление документации по шаблону. Плохие кандидаты: «помоги придумать архитектуру», «обсуди стратегию», «накидай идей» — это разговорные задачи, а не процедурные.
Анатомия рабочего SKILL.md
Любой skill, который работает стабильно, держится на шести блоках. Уберите любой — получите плавающее качество.
Блок | Что описывает | Пример |
|---|---|---|
1. Purpose | Какую задачу решает skill и кто его пользователь | «Ты — инженерный ревьюер PR. Находишь риски в изменениях» |
2. Input | Что агент получает на старте | Название PR, список файлов, контекст репозитория |
3. Process | Шаги в строгом порядке | Проверь регрессии → безопасность → тесты → долг |
4. Output Format | Что именно вернуть и как | 4 секции: Critical / Medium / Open questions / Test gaps |
5. Guardrails | Что агент делать НЕ должен | Не выдумывать факты, не переписывать модуль целиком |
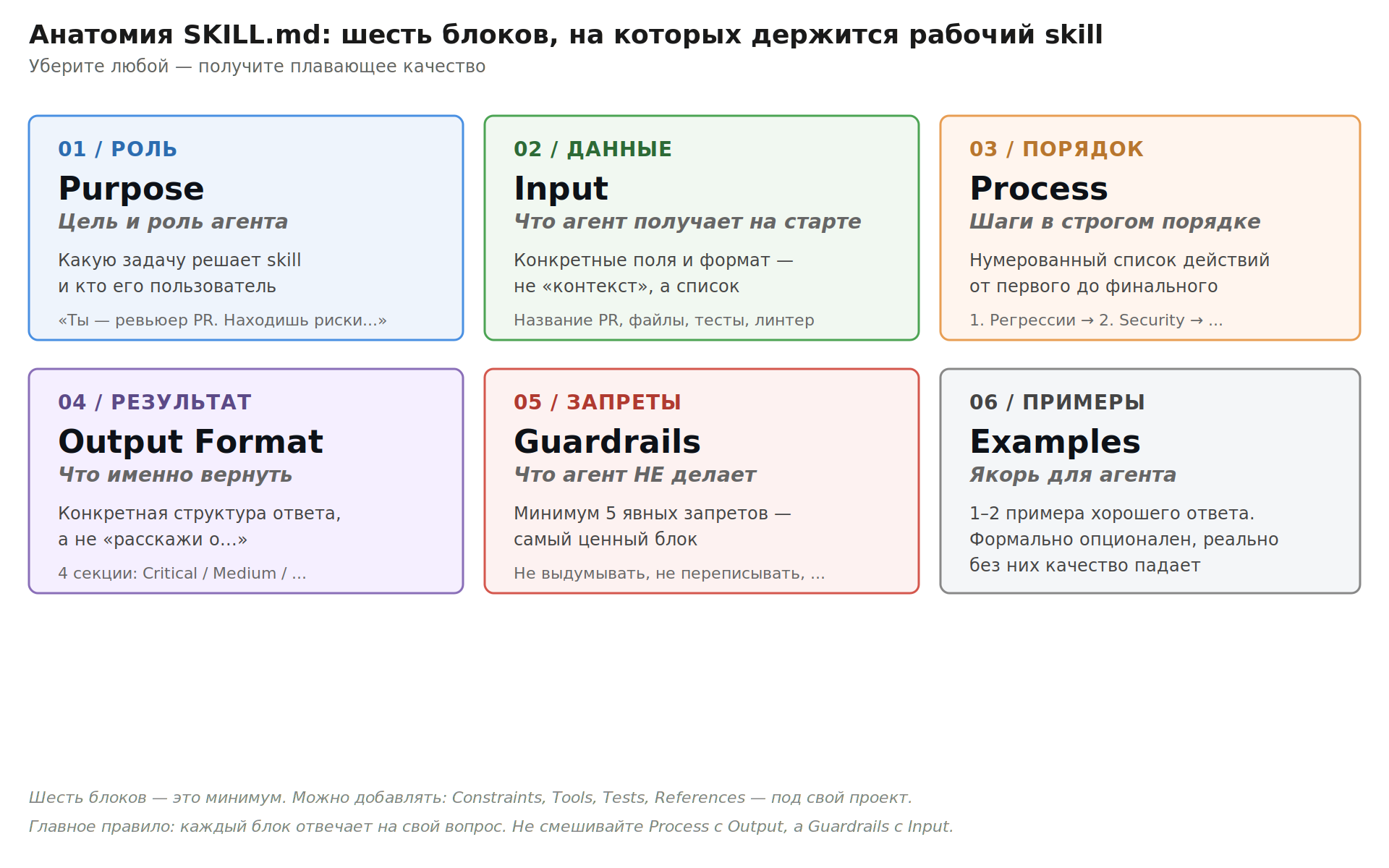
Шестой блок — примеры — официально опционален, но практика показывает, что без них качество падает заметно. Агенту нужен якорь: «вот так выглядит правильный результат».
От идеи до рабочего файла за шесть шагов
Шаг 1. Сформулируйте задачу узко
Это самый частый провал на старте. Люди пишут skill «для маркетинга» или «для код-ревью» — и потом удивляются, почему он работает хуже, чем разовый промпт. Узкая задача всегда лучше широкой.
Плохо: «Skill для контент-маркетинга»
(слишком широко — что именно делает?)
Хорошо: «Skill, который из одного длинного поста делает 5 форматов: тред в Telegram, пост в LinkedIn, email-рассылку, FAQ и CTA-варианты, сохраняя ключевые тезисы»
(понятен вход, выход, критерий)
Шаг 2. Опишите вход и выход словами
Прежде чем открывать любой редактор, ответьте на три вопроса в столбик:
Что на входе? Какой материал я даю агенту, в каком формате, какого объёма
Что на выходе? Какие именно блоки результата, какого объёма, в каком формате
Как буду проверять? Какие 3–5 признаков отличают хороший результат от плохого
Если ответы не помещаются на половину страницы — задача всё ещё слишком широкая, возвращайтесь к шагу 1.
Шаг 3. Создайте структуру папки
Минимальная структура выглядит так:
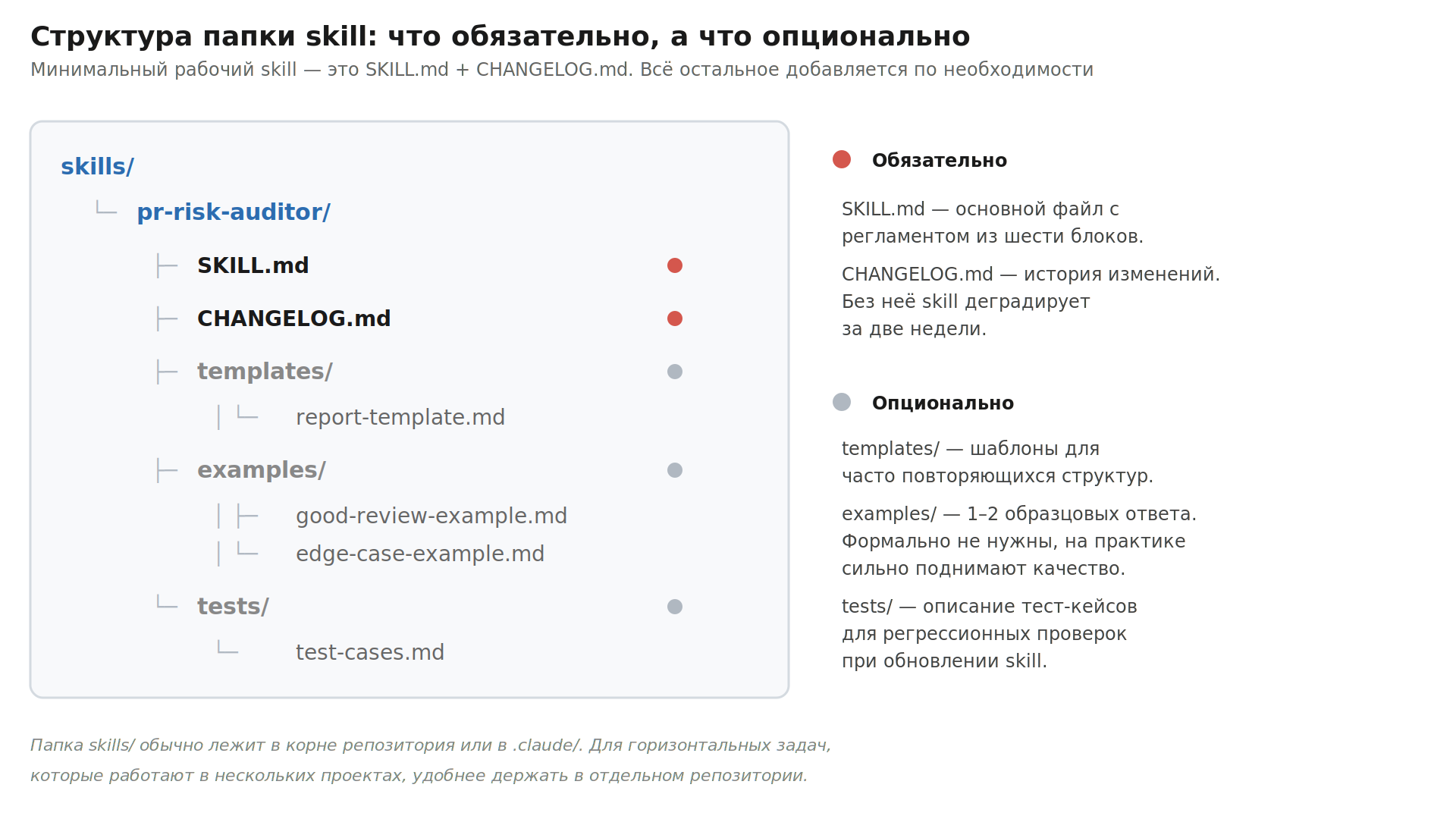
Templates и examples нужны не всегда. SKILL.md и CHANGELOG.md — всегда. Про версионирование подробнее ниже.
Шаг 4. Напишите SKILL.md по шести блокам
Используйте структуру из таблицы выше. Заполняйте по порядку — Purpose, Input, Process, Output, Guardrails, Examples. Каждый блок отвечает на свой вопрос, не смешивайте.
Шаг 5. Пропишите guardrails максимально явно
Это блок, который чаще всего недописывают. А он самый ценный. Тут указывайте всё, что агент любит делать сам по себе, но вам не нужно:
Не выдумывай факты, которых нет во входных данных
Если данных не хватает, явно пиши
[НУЖНО УТОЧНИТЬ]вместо догадокНе трогай файлы за пределами списка
changed_filesНе предлагай переписать модуль целиком, если можно поправить локально
Не используй слова: «инновационный», «прорывной», «комплексный»
Не комментируй то, что не относится к задаче
Чем больше конкретики в guardrails, тем стабильнее работает skill.
Шаг 6. Прогоните на пяти разных входах
Самая частая ошибка — тестировать на одном хорошем примере. Skill работает, человек радуется, выкатывает в команду — а через неделю на реальных данных всё разваливается.
Правильно — пять разных тест-кейсов с самого начала:
Тип теста | Что проверяет |
|---|---|
1. Идеальный вход | Все данные на месте, всё чисто — работает ли вообще |
2. Неполный вход | Часть данных отсутствует — ставит ли агент |
3. Конфликтные требования | В задаче противоречие — спрашивает или придумывает за вас |
4. Заведомо плохие данные | Битая структура, мусорный текст — не падает, выдаёт осмысленную реакцию |
5. Edge-case | Граничный случай (огромный PR, пустой репозиторий) — не теряется |
Все пять — обязательны. Каждый раз, когда обновляете skill, прогоняйте их заново. Это и есть регрессионное тестирование промптов.
Пример 1: skill pr-risk-auditor
Задача — быстро находить риски в pull request: регрессии, дыры в безопасности, пробелы в тестах. Возвращать структурированный отчёт, который удобно встраивать в комментарий к PR.
Полезен, если код-ревью занимает много времени или в PR регулярно проскальзывают одни и те же проблемы.
Файл SKILL.md
# PR Risk Auditor
## Purpose
Ты — инженерный ревьюер PR. Твоя задача — находить риски
изменений, а не пересказывать дифф. Главный фокус —
регрессии, безопасность и пробелы в тестах.
## Input
- Название задачи или PR
- Список изменённых файлов
- Контекст репозитория (если доступен)
- Результаты тестов и линтера (если есть)
## Process
1. Проверь риски регрессии в бизнес-логике.
2. Проверь security: валидация, права, обработка
пользовательского ввода, утечки данных.
3. Проверь пробелы в тестовом покрытии — что осталось
без тестов.
4. Проверь технический долг: дублирование, магические
значения, хрупкие зависимости.
5. Не хвали код без причины — фокус только на рисках.
## Output Format
Верни результат в 4 секциях:
1) Critical findings
2) Medium findings
3) Open questions
4) Test gaps
Для каждого finding:
- Severity: Critical | Medium | Low
- File / area
- Why this is risky
- Suggested fix
## Guardrails
- Не выдумывай факты, которых нет в изменениях.
- Если данных недостаточно, явно пиши: [НУЖНО УТОЧНИТЬ].
- Не предлагай переписывать модуль целиком, если есть
локальное исправление.
- Если critical рисков нет, так и напиши — не выдумывай.
- Не комментируй стиль кода — это работа линтера.
## Examples
См. examples/good-review-example.md
Что доработать под свой проект
Базовая версия закрывает 80% задач код-ревью. Под свой контекст обычно добавляют:
Внутренние secure-coding правила компании (со ссылкой на wiki)
Список «запрещённых паттернов» — конкретные антипаттерны вашего проекта
Привязку отчёта к шаблону PR (если в репозитории есть
.github/PULL_REQUEST_TEMPLATE.md)Категории рисков, специфичные для вашего стека: например, для финтеха — отдельная категория для всего, что трогает деньги
Когда не работает
На очень больших PR (1000+ строк) skill начинает плыть — контекстное окно перегружается, агент пропускает риски в середине. Решение — разбивать PR на части или прогонять skill отдельно по каждому файлу.
Пример 2: skill content-repurposer
Задача — превращать один большой материал (статью, конспект подкаста, доклад) в пачку форматов для разных каналов. С сохранением тезисов, фактуры и тона автора.
Полезен командам, где один эксперт пишет длинный материал, а маркетингу нужен пакет под несколько каналов сразу — Telegram, LinkedIn, email-рассылка, FAQ.
Файл SKILL.md
# Content Repurposer
## Purpose
Ты — контент-редактор. Пересобираешь один исходник
в несколько форматов под разные каналы, сохраняя фактуру,
тезисы и тон автора.
## Input
- Исходный материал (статья, конспект подкаста, доклад)
- Целевая аудитория и канал публикации
- Ограничения по тону (formal / casual / профессиональный)
- Запреты: слова, обещания, юридические ограничения
## Process
1. Выдели 3–5 главных тезисов исходника. Запиши их
отдельно — на них будут опираться все форматы.
2. Для каждого формата проверь: опирается ли он на эти
тезисы или съехал в общие фразы.
3. Убери канцеляризмы и «контентные» клише.
4. Зафиксируй цель каждого формата: вовлечение, переход
на сайт, сохранение в избранное.
5. Перед финалом проверь фактуру: цифры, имена,
даты, ссылки.
## Output Format
Верни 5 блоков в строгом порядке:
1) Thread для Telegram — 7–10 коротких пунктов
2) Пост для LinkedIn — до 1200 знаков
3) Email-анонс — тема + прехедер + тело
4) Short FAQ — 5 вопросов с ответами
5) CTA-варианты — 3 штуки разной тональности
## Guardrails
- Не добавляй факты, которых нет в исходнике.
- Если данных не хватает, ставь маркер: [НУЖНО УТОЧНИТЬ].
- Запрещённые слова: «инновационный», «прорывной»,
«лучший на рынке», «уникальный», «революционный».
- Не меняй позицию автора исходного текста.
- Не используй смайлики, если в исходнике их не было.
## Examples
См. examples/repurpose-example.md
Где особенно хорошо работает
Тип команды | Зачем нужен |
|---|---|
B2B с длинным циклом сделки | Один глубокий материал — на 5 точек касания с клиентом |
Продуктовые команды | Один ресёрч раскладывается на 5–7 форматов |
Контент-агентства | Масштабирование редакторского стиля без переписывания вручную |
EdTech | Один курс-лекция превращается в посты, FAQ, email-серию |
Версионирование: почему без CHANGELOG skill быстро ломается
Любой рабочий skill должен жить с версией. Без этого через пару недель будет так:
— На прошлой неделе skill работал отлично, а сейчас выдаёт ерунду.
— А ты что-то менял?
— Ну, добавил пару пунктов в Process. И в Guardrails чуть-чуть.
— Откатить можешь?
— Нет.
Минимальная схема версионирования простая. В корне папки skill — файл CHANGELOG.md:
# Changelog — PR Risk Auditor
## [1.2.0] — 2026-03-15
### Added
- Категория «Performance risks» в Process
- Пример с N+1 query в examples/
### Changed
- Output Format: разделили Test gaps на unit и integration
## [1.1.0] — 2026-02-28
### Added
- Guardrail: не комментировать стиль кода
## [1.0.0] — 2026-02-10
- Первая стабильная версия
Любое изменение skill — это коммит в репозиторий с описанием в CHANGELOG. Тогда через месяц можно понять, что и когда менялось, и откатиться, если что-то пошло не так.
Чек-лист готовности перед использованием в работе
Перед тем как давать skill команде или использовать в боевой работе, пробегитесь по этому списку. Все девять пунктов — обязательные.
Пункт | Проверка |
|---|---|
Purpose задаёт роль и фокус | «Ты — X. Делаешь Y». Без воды |
Input описан конкретно | Какие именно поля, в каком формате |
Process пронумерован | Шаги по порядку, без вложенности глубже двух уровней |
Output Format показан буквально | Не «дай отчёт», а «верни 4 секции с именами таких-то полей» |
Guardrails содержит минимум 5 запретов | Не общие, а конкретные — что именно агент НЕ делает |
Есть хотя бы один пример хорошего ответа | В examples/ или внутри SKILL.md |
Прогнаны 5 разных тест-кейсов | Идеальный, неполный, конфликтный, плохие данные, edge-case |
Создан CHANGELOG.md | С версией 1.0.0 и описанием |
Skill закоммичен в git | Не лежит локально у одного человека |
Если хотя бы один пункт под вопросом — skill ещё не готов. Доработайте, прежде чем рекомендовать его коллегам.
Частые ошибки и как их избежать
Ошибка 1: skill пишут как мотивационный текст
Так делают:
«Ты — топовый ревьюер с десятилетним опытом. Ты внимателен к деталям, обладаешь системным мышлением и помогаешь команде расти. Твоя задача — внимательно проверить PR».
Правильно:
«Ты — ревьюер PR. Проверяешь четыре категории рисков: регрессии, security, тесты, технический долг. По каждой выдаёшь findings с severity и suggested fix».
Агенту не нужны эпитеты. Ему нужна процедура. Любые слова про «внимательность» и «опыт» — это пустые токены, которые не влияют на качество.
Ошибка 2: не задают формат вывода
Если не сказать «верни 4 секции с такими именами», агент каждый раз будет придумывать структуру заново. Иногда удобную, иногда нет. Воспроизводимость — ноль.
Ошибка 3: запреты только общие
Так делают: «Не выдумывай»
Правильно: «Не выдумывай факты, которых нет во входных данных. Если данных не хватает, ставь маркер [НУЖНО УТОЧНИТЬ]. Не добавляй ссылки, которые не были даны в исходнике».
Общий запрет агент игнорирует. Конкретный — выполняет.
Ошибка 4: тестируют только на хороших данных
Skill, который красиво работает на идеальном примере, может полностью рассыпаться на неполных или конфликтных данных. Это всплывает только при тестировании на плохих входах. Пропустите этот шаг — поймаете баги в проде.
Ошибка 5: skill без версий
Без CHANGELOG любой skill живёт примерно две недели. Дальше начинаются хаотичные правки, и никто уже не помнит, что и зачем меняли. Через месяц skill либо удаляют, либо переписывают с нуля. И того, и другого можно избежать.
Краткие выводы
Skill — это операционный стандарт, а не украшение промпта
Лучший skill узкий: одна роль, один тип результата, чёткие ограничения
Два хороших навыка обычно лучше одного «универсального»
Без версий и тест-кейсов любой skill деградирует за пару недель
Начинайте с 1–2 повторяющихся задач и доводите их до стабильности, прежде чем расширять
Если хотите усилить техническую часть — агенты, контекст, ревью, ограничения — посмотрите курс «ИИ для разработчиков». Для продуктовой интеграции LLM — «LLM-разработчик».
FAQ
Skill и Cursor Rules — это одно и то же?
Похожие концепции, но не идентичные. Cursor Rules работают на уровне IDE и применяются автоматически ко всем задачам в проекте. Skill в Claude Code — это явно вызываемая процедура: вы говорите «используй skill X для этой задачи». Один проект может иметь и то, и другое: Cursor Rules задают общие правила всего репозитория, skills — специализированные регламенты под конкретные типы задач. Подробнее про настройку правил в IDE — в отдельной статье про Cursor Rules.
Сколько skills имеет смысл держать в одном проекте?
На практике — от 3 до 10. Меньше трёх — обычно это значит, что вы не доконца разобрали свои повторяющиеся задачи. Больше десяти — начинается каша: команда забывает, какой skill для чего, и какой брать. Если набралось 15+ — пора группировать или объединять близкие по смыслу.
Можно ли использовать один skill в нескольких проектах?
Можно, и это правильная стратегия для горизонтальных задач — код-ревью, написание тестов, генерация changelog. Для них имеет смысл держать skills в отдельном репозитории shared-skills и подключать как git submodule в проекты. Для специфичных задач (например, миграции в конкретной БД проекта) skill всё-таки лучше держать рядом с кодом.
Что делать, если skill начинает плыть на больших задачах?
Это контекстное окно перегружается. Решений два. Первое: разбивать задачу на части и прогонять skill по каждой отдельно (для PR — по файлу за раз). Второе: упростить сам skill, убрать всё, что не относится к ключевой задаче. Иногда автору кажется, что чем больше деталей — тем лучше, а на практике агент начинает путаться в собственных инструкциях.
Нужно ли версионировать каждое мелкое изменение skill?
Не каждое, но в CHANGELOG имеет смысл записывать любое изменение поведения. Опечатку в комментарии — можно не записывать. Новое правило в Guardrails или новый шаг в Process — обязательно. Семантическая версия (1.0.0 → 1.1.0 → 2.0.0) помогает: minor для добавления функций, major для изменений, которые ломают совместимость.
С чего начать, если skill ещё не было ни одного?
Возьмите самую раздражающую повторяющуюся задачу — ту, на которой вы каждый раз тратите 20 минут на объяснение одного и того же. Напишите для неё skill по шести блокам из этой статьи. Прогоните на пяти разных входах. Закоммитьте в репозиторий. Через неделю работы с ним вы поймёте, какие ещё задачи у вас в команде заслуживают такого же отношения.
Есть ли публичная библиотека готовых skills?
На декабрь 2026 года — нет официальной от Anthropic, но в open source есть несколько коллекций на GitHub, которые активно растут. Их легко найти по запросу «awesome-claude-skills». Имеет смысл смотреть на них как на источник идей, а не как на готовое решение: каждый skill всё равно придётся адаптировать под свой проект и свои guardrails.
.png)




