
ИИ-разработчик в 2026: три разные профессии под одним словом
Знакомая сцена. Кандидат на собеседовании говорит: «Я хочу работать в ИИ». В трёх разных компаниях за неделю ему задают три совершенно разных следующих вопроса. В первой: «Какие провайдеры моделей знаете, работали ли с function calling и structured outputs?» Во второй: «Расскажите, как организуете дообучение трансформера на своём корпусе?» В третьей: «Как бы вы автоматизировали обработку обращений из почты через ИИ-агента, чтобы выписки шли прямо в CRM?»
Все три вакансии назывались одинаково — «AI Engineer». Все три компании были правы. Просто под этим словом в 2026 году скрываются три разные профессии — с разными задачами, разным стеком и разной зарплатой.
Дальше — карта этих трёх ролей, что реально просят у каждой, какой путь в них самый короткий и где платят больше всего. Если вы хотите «в ИИ» и не знаете, в какую именно сторону — этот текст поможет выбрать. Если уже выбрали, но застряли в обучении — поможет не распыляться.
Цельный маршрут для разработчика, который хочет работать с LLM в продакшене — программа «LLM-разработчик» на Хекслете.
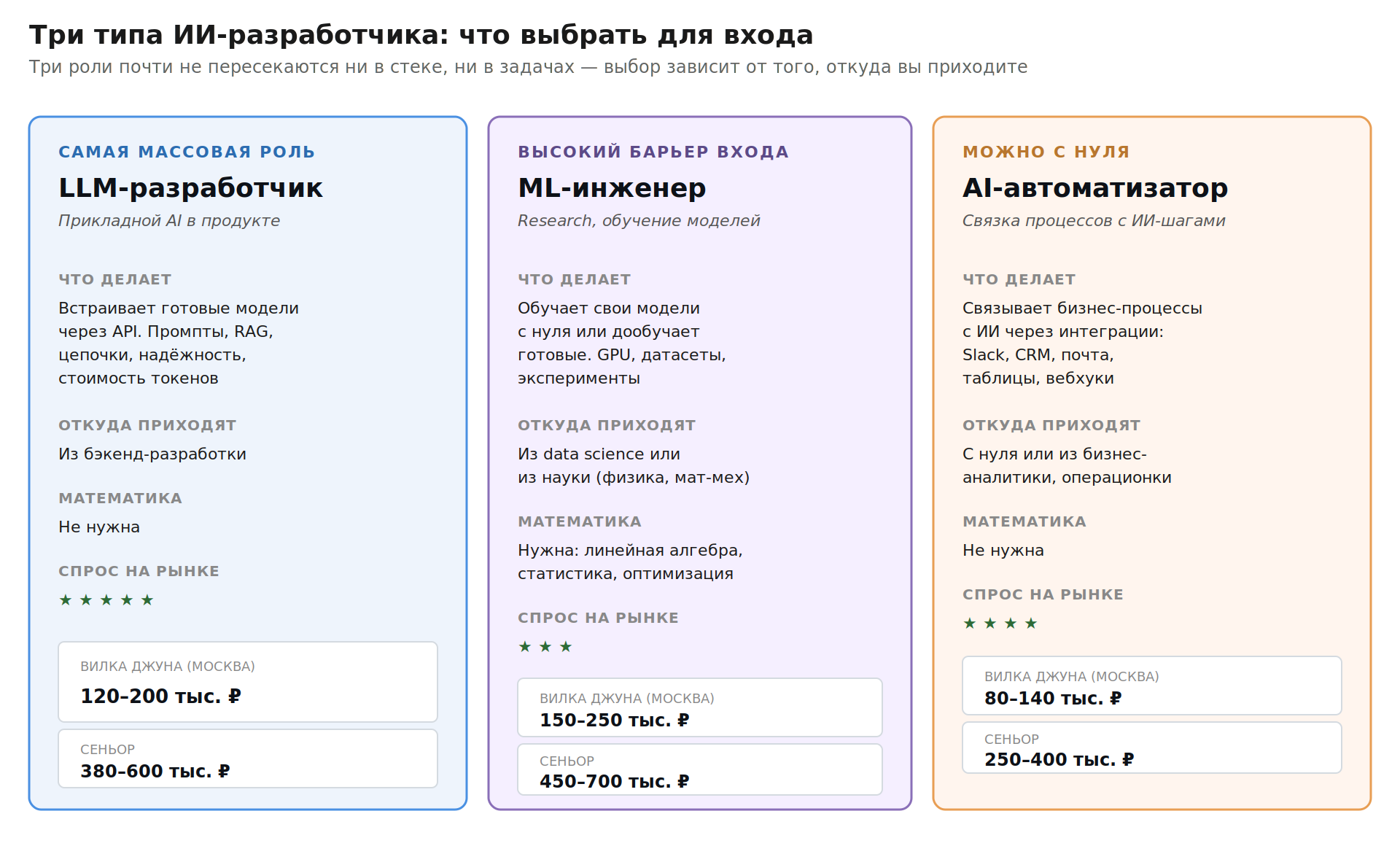
Три разных «ИИ-разработчика»: главное разделение
Прежде чем спорить про PyTorch или промпт-инжиниринг, разделите три фундаментально разные роли.
Тип | Что делает | Откуда приходят |
|---|---|---|
LLM / прикладной AI-разработчик | Встраивает готовые модели через API в продукт. Промпты, RAG, цепочки вызовов, надёжность, стоимость | Из бэкенд-разработки |
ML / Research-инженер | Обучает свои модели, дообучает существующие, работает с GPU и большими датасетами | Из data science или из науки |
AI-автоматизатор | Связывает бизнес-процессы с ИИ-шагами через интеграции (Slack, CRM, почта, таблицы) | С нуля или из бизнес-аналитики |
Эти три роли почти не пересекаются ни в стеке, ни в задачах. LLM-разработчик в продуктовой команде редко обучает модель с нуля — для 95% коммерческих задач хватает готовых от OpenAI, Anthropic или Google. ML-инженер не пишет промпты для чат-бота поддержки. AI-автоматизатор не залезает в код провайдера моделей.
В крупных компаниях эти роли разделены. В стартапах часто один человек тащит всё, но при этом ясно знает, что сейчас он надевает шляпу LLM-разработчика, а через час — AI-автоматизатора.
Самая массовая роль на рынке в 2026 году — первая. Поэтому дальше в основном про LLM-разработку в продуктовых командах.
Как реально выглядит день LLM-разработчика
В представлении новичка LLM-разработчик весь день пишет промпты и спорит про новые модели в Twitter. В реальности это нормальный бэкенд-разработчик с дополнительным набором задач.
Время | Что происходит |
|---|---|
10:00–10:30 | Дейли с командой. Обсуждаем алерт ночью: один из промптов начал возвращать невалидный JSON в 3% случаев после релиза новой версии модели |
10:30–12:00 | Чините проблему: смотрите логи, находите 50 примеров с битым JSON. Понимаете, что новая версия модели слегка иначе обрабатывает кавычки в промпте |
12:00–13:30 | Обновляете промпт, прогоняете на тестовом наборе из 200 примеров. Метрика улучшилась с 97% до 99.5%. Деплоите за функция-флагом на 10% трафика |
13:30–14:30 | Обед или встреча с продактом. Обсуждаете новую функцию: автогенерация описаний товаров. Спорите о метрике успеха |
14:30–16:00 | Прототипируете новую функцию: 30 строк кода, вызов модели, JSON-схема для structured output. Тестируете на 10 реальных примерах |
16:00–17:00 | Считаете стоимость функции: при 10 000 запросов в день на текущей модели — около $35. Если масштабировать до 100 000 — $350 в день. Думаете о более дешёвой модели для простых случаев |
17:00–18:00 | Документация в Notion: разбор инцидента и обновления промпта. Это нужно, чтобы через три месяца коллега понял, почему промпт выглядит именно так |
Что бросается в глаза — много инженерной работы, обычные практики бэкенда (логи, метрики, тесты), и большая часть дня не про сами модели, а про их обвязку и проверку качества.
Сколько платят: зарплаты ИИ-разработчиков в 2026
Цифры — из агрегаторов вакансий и опросов сообществ в первом квартале 2026 года. На руки, до налогов. ИИ-разработка — одно из самых высокооплачиваемых направлений в IT, особенно для тех, кто пришёл сюда из бэкенда с опытом.
Уровень | LLM-разработчик · Москва | ML-инженер · Москва | AI-автоматизатор · Москва |
|---|---|---|---|
Junior | 120–200 тыс. ₽ | 150–250 тыс. ₽ | 80–140 тыс. ₽ |
Middle | 200–380 тыс. ₽ | 280–450 тыс. ₽ | 140–250 тыс. ₽ |
Senior | 380–600 тыс. ₽ | 450–700 тыс. ₽ | 250–400 тыс. ₽ |
Lead / Principal | 500–900 тыс. ₽ | 600–1.2 млн ₽ | 350–500 тыс. ₽ |
Несколько наблюдений по рынку 2026 года:
ML-инженерия платит больше, но порог входа выше — нужны Python, математика, опыт с обучением моделей
LLM-разработка — самая массовая ниша, понятная для бывшего бэкенд-разработчика
AI-автоматизация платит меньше всего, но и входить туда можно с нуля без программистского опыта
Удалёнка на западные компании в ИИ работает особенно хорошо — там зарплаты в 2–4 раза выше российских в долларовом эквиваленте
Опыт со специфическими доменами (legal, medical, fintech) даёт сильную премию — там нужны люди, понимающие и ИИ, и предметную область
Почему «обучаю нейронку с нуля» — не обязательный вход
Самое частое заблуждение новичков: чтобы пойти в ИИ-разработку, нужно знать линейную алгебру, оптимизацию и архитектуру трансформеров. Это правда — если вы метите в ML-исследования. Это неправда — если ваша цель LLM-разработка в продуктовой команде.
В коммерческом продукте задача редко звучит как «обучить модель с нуля». Гораздо чаще: «взять сильную готовую модель от OpenAI, Anthropic или Google, аккуратно сформировать контекст, проверить качество ответа, вписать в API, не слить бюджет на токенах и не утечь персональные данные». Всё это — обычная инженерия, без матана.
Это не значит, что ML «бесполезен» — он критически важен в исследованиях и в крупных компаниях вроде Яндекса, Сбера, OpenAI. Это значит, что порог входа в прикладной ИИ для разработчика сегодня определяется не курсом по линейной алгебре, а умением ставить эксперимент, измерять качество и доводить функцию до продакшена.
Если математика и классический ML вам понадобятся — вы узнаете об этом по самой задаче. Не по заголовку вакансии.
Стек LLM-разработчика в 2026
Разбил на три уровня по обязательности.
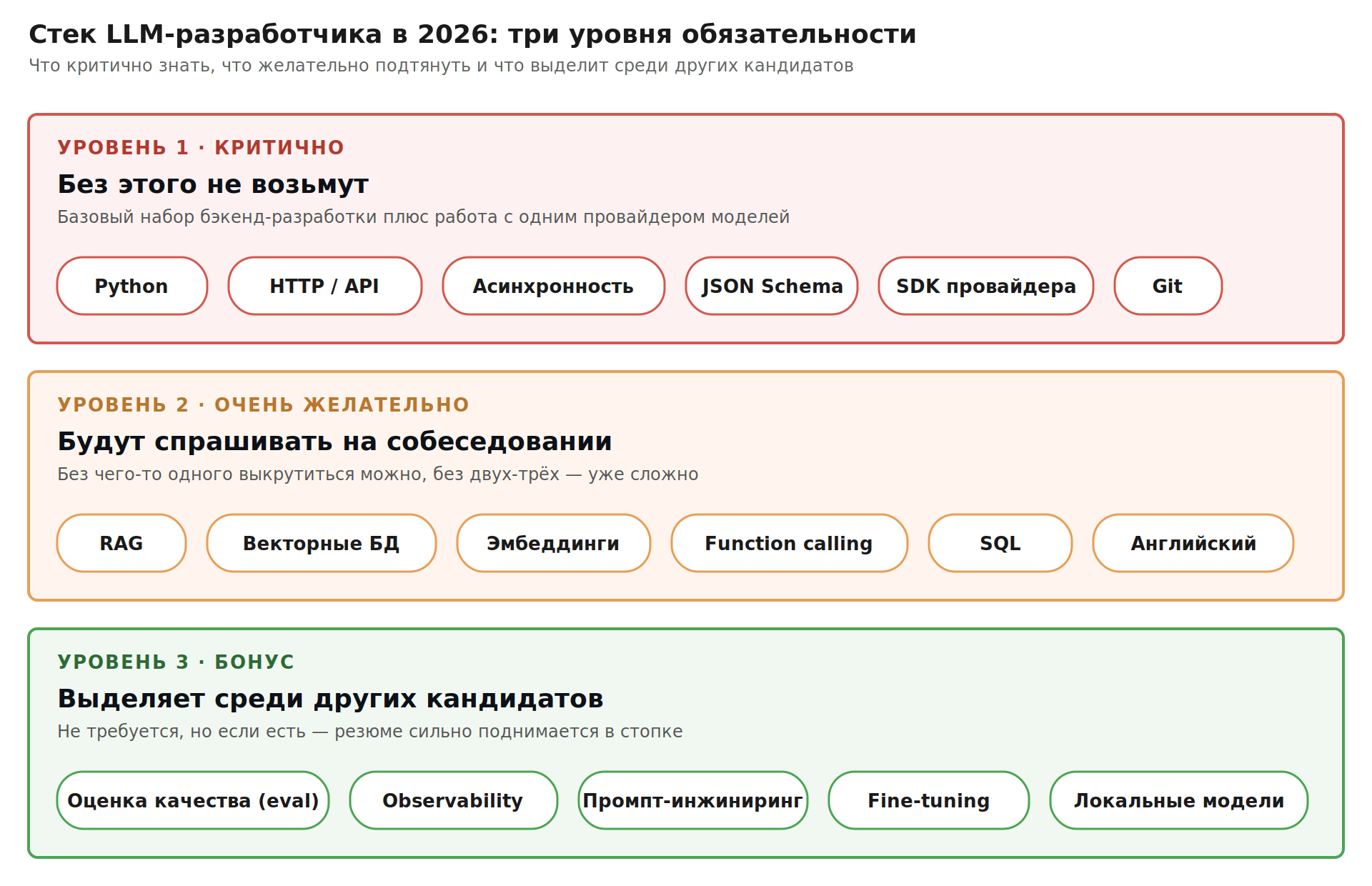
Критично — без этого не возьмут
Область | Что нужно |
|---|---|
Python | Уверенное программирование. Это де-факто язык ИИ-разработки в 2026 году |
HTTP и API | REST, статусы, заголовки, аутентификация. Все провайдеры моделей — это HTTP API под капотом |
Асинхронность | asyncio, обработка нескольких запросов параллельно. Ответы LLM медленные — это критично |
JSON и схемы | Structured outputs, валидация, обработка ошибок парсинга |
SDK провайдера | OpenAI SDK или anthropic SDK до уровня уверенной работы |
Git | Командная работа с кодом, ревью, ветки |
Желательно — будут спрашивать на собеседовании
Область | Зачем |
|---|---|
RAG (Retrieval-Augmented Generation) | Базовый паттерн: модель отвечает с опорой на ваши документы. 70% LLM-проектов используют RAG |
Векторные БД | Pinecone, Weaviate, pgvector — хотя бы одна на базовом уровне |
Эмбеддинги | Понимание, как работают и для чего нужны. Не обязательно знать математику |
Function calling / tool use | Когда LLM вызывает ваш код. Основа агентских паттернов |
Базы данных и SQL | Бэкенд-разработка никуда не делась — все эти LLM-функции живут в обычных приложениях |
Английский | Документация провайдеров и техническая литература — почти вся на английском |
Бонус — выделяет среди других кандидатов
Область | Где пригодится |
|---|---|
Оценка качества (eval) | Платформы вроде Braintrust, Langfuse, или своя система метрик |
Observability для LLM | Трассировка, мониторинг стоимости, сравнение релизов |
Промпт-инжиниринг продвинутый | Chain-of-thought, few-shot, role prompting |
Безопасность ИИ-приложений | Защита от инъекций промптов, утечек, jailbreak'ов |
Fine-tuning | Дообучение готовой модели на своих данных. Не для всех задач, но иногда даёт сильный выигрыш |
Локальные модели | Llama, Mistral на своём железе. Для компаний с требованиями к приватности |
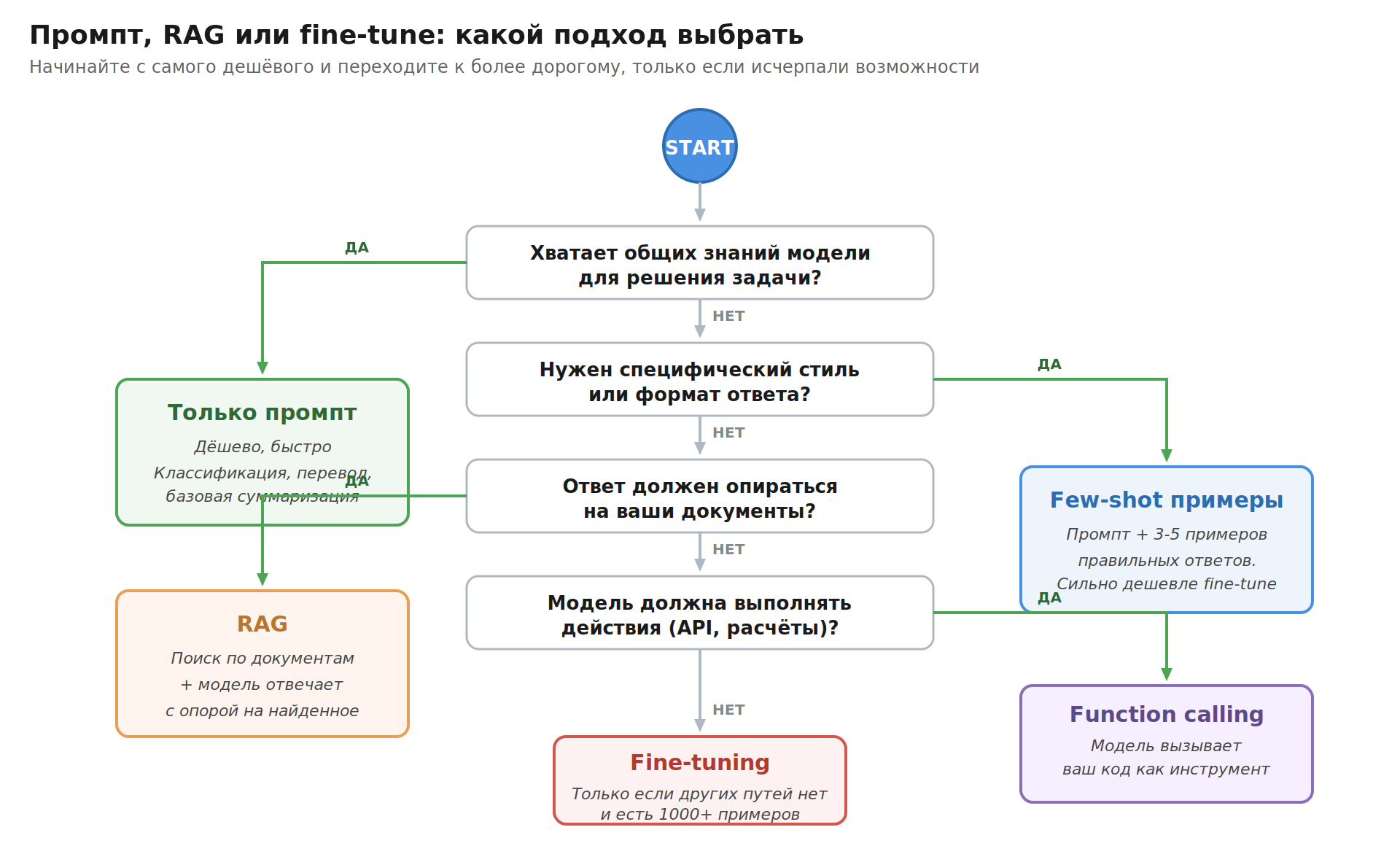
Промпт, RAG, fine-tune: когда что выбирать
Самая частая ошибка новичка в LLM-разработке — начать с дообучения модели, когда можно было обойтись правильным промптом. Или наоборот — бесконечно дорабатывать промпт, когда нужен был RAG.
Простое правило: начинайте с самого дешёвого подхода и переходите к более дорогому, только когда исчерпали возможности.
Подход | Когда уместен | Когда не работает |
|---|---|---|
Только промпт | Задача узкая, общих знаний модели хватает. Например, классификация отзывов, перевод, базовая суммаризация | Когда нужны конкретные данные вашей компании или сложная логика |
Промпт + few-shot примеры | Модель должна следовать конкретному стилю или формату — даёте 3–5 примеров правильных ответов | Когда вариативность входов слишком высокая для примеров |
RAG (поиск + ответ) | Ответ должен опираться на ваши документы: внутренние регламенты, продуктовая база знаний, юридические тексты | Когда задача чисто аналитическая или творческая, без фактов |
Function calling / агенты | Модель должна выполнять действия: запрашивать API, читать файлы, выполнять расчёты | Когда задача линейная и шаги известны заранее — обычной цепочки хватит |
Fine-tuning | Нужен очень специфический стиль, домен или формат. И есть несколько тысяч примеров для обучения | Когда хочется добавить новые знания — для этого нужен RAG, не fine-tune |
На практике 80% LLM-задач в 2026 году — это «промпт + RAG» или «промпт + function calling». Fine-tuning встречается реже и применяется, когда другие методы исчерпаны.
Что отличает LLM от обычного API
Если вы из бэкенда, то LLM-вызов кажется обычным HTTP-запросом. И это правда — на 70%. Остальные 30% важно понять до того, как функция уедет в продакшен.
Похоже на обычное API | Совсем не похоже |
|---|---|
HTTP-запрос с JSON | Ответ недетерминирован — один и тот же запрос даёт разные ответы |
Лимиты на запросы и токены | Стоимость растёт с длиной контекста квадратично, а не линейно |
Авторизация по API-ключу | «Починить баг» — это переписать промпт, не if-else |
Можно мерить latency и error rate | Качество ответа — отдельная метрика, которую нужно специально мерить |
Логи и трейсы | Версия модели в провайдере может молча измениться и сломать всё |
Главное отличие — недетерминизм. Это меняет всё в подходе к тестированию. Обычные unit-тесты не работают: вы не можете написать «модель должна вернуть строку X», потому что в следующий раз она вернёт X-похожее, но не идентичное. Поэтому в LLM-разработке появляются специфические инженерные практики: eval-наборы из примеров с ожидаемыми свойствами ответа, метрики качества, A/B-сравнения промптов.
Один вызов, цепочка или агент
Архитектурный выбор, который сильно влияет на сложность и стоимость.
Один вызов — самое простое. Запрос → ответ → валидация. Для суммаризации, классификации, черновика письма этого хватает. Низкая стоимость, простая отладка, предсказуемая стоимость.
Цепочка (pipeline) — несколько последовательных шагов. Например: извлечь сущности из текста → проверить их в БД → составить финальный ответ. Каждый шаг можно отдельно логировать и тестировать. Сложнее, чем один вызов, но всё ещё предсказуемо.
Агент — модель сама планирует, какие инструменты вызывать, и в каком порядке. Самый гибкий вариант, но и самый сложный. Если без жёстких ограничений и хорошей наблюдаемости — агент уходит в сторону, делает лишние вызовы, тратит токены и иногда вообще зависает.
Практическое правило: начинайте с самого простого варианта, который решает задачу. Один вызов справится — не делайте цепочку. Цепочка справится — не делайте агента. Агентов в проде должно быть минимум — они дорогие и сложные в отладке.
Антипаттерны новичка в LLM-разработке
Гонка за моделью вместо измерения. «Давайте перейдём на GPT-5», «попробуем Claude Opus 4.7». Прежде чем менять модель — измерьте, действительно ли проблема в её возможностях. Часто проблема в постановке задачи, а не в модели.
Тестирование «на глаз». «Я прогнал три примера — выглядит лучше». Это не оценка. Заведите набор из 50–100 примеров с ожидаемыми свойствами и прогоняйте после каждого изменения промпта. Без этого вы оптимизируете под шум.
Подглядывание в тестовый набор. Каждую неделю смотреть на тестовые примеры и подгонять под них промпт — это переобучение. У вас должна быть отложенная выборка, на которую вы не смотрите до финала.
Агент без ограничений. Красиво в демо, больно в проде. Агент может уйти в бесконечный цикл, потратить тысячи долларов на токены, вызвать опасный инструмент. Жёсткие лимиты — обязательны.
Игнорирование стоимости. Прототип на 100 запросов в день стоит копейки. Прод на 100 000 запросов — это уже тысячи долларов в месяц. Считайте стоимость функции до запуска, не после счёта.
Личный API-ключ в коде компании. Юридически плохо, при увольнении весело. Используйте корпоративный аккаунт у провайдера и переменные окружения.
Промпт-инъекции игнорируются. Если в промпт попадает пользовательский ввод, он может содержать инструкции, которые перебьют вашу логику. Это вектор атаки, особенно для агентов.
План учёбы для разработчика: 5–7 месяцев
Этот план для тех, кто уже пишет код на каком-то языке. Если идёте с нуля — добавьте 4–6 месяцев на Python и основы программирования.
Этап | Что осваиваете | Сколько времени |
|---|---|---|
1. Первые вызовы API | SDK OpenAI или Anthropic. Базовые запросы. Параметры (temperature, max_tokens) | 1–2 недели |
2. Промпт-инжиниринг | Структура промпта, role/system/user, few-shot, chain-of-thought | 2–3 недели |
3. Structured outputs | JSON Schema, валидация, обработка ошибок парсинга | 1 неделя |
4. Оценка качества | Eval-наборы, метрики, A/B сравнения. Это самый важный навык | 2 недели |
5. RAG | Чанкинг, эмбеддинги, векторный поиск, сборка контекста | 3–4 недели |
6. Function calling и агенты | Tool use, ограничения, циклы. На реальных примерах | 2–3 недели |
7. Production-ready | Таймауты, ретраи, fallback, мониторинг, стоимость | 2 недели |
8. Безопасность | Промпт-инъекции, PII, корпоративные политики | 1 неделя |
9. Портфолио | 2–3 публичных проекта на GitHub с README и метриками качества | 4–6 недель |
10. Поиск работы | Резюме, собесы, mock-интервью | 1.5–3 месяца |
Итого реалистично: 5–7 месяцев с уверенного бэкенда до первого LLM-оффера при 10–15 часах в неделю. Это короче, чем переучивание во фронтенд или DevOps — потому что база (HTTP, Python, БД) у вас уже есть.
Для системного прохождения этого пути подходит программа «ИИ для разработчиков» или более глубокая «LLM-разработчик».
Куда расти из LLM-разработчика
Через 2–3 года работы открывается несколько траекторий. Каждая со своими требованиями.
Куда | Что подтянуть | Сколько занимает |
|---|---|---|
Senior LLM Engineer | Архитектура AI-систем, наставничество, понимание бизнеса | 2–3 года из миддла |
AI Architect | Большая архитектура, выбор моделей и провайдеров, ROI расчёты для бизнеса | 3–4 года из сеньора |
ML Engineer | Глубже в data science, обучение моделей, классический ML | 1–2 года догонки (нужна математика) |
AI Product Manager | Меньше кода, больше работы с продуктом, метриками, бизнесом | 2–3 года инженерной работы |
AI Safety Engineer | Безопасность ИИ-систем: защита от инъекций, eval safety, red teaming | 2 года в области |
Independent / Consultant | Свои клиенты, проекты под ключ, обучение команд | 3+ года опыта |
Самые частые ветки на практике — Senior и AI Architect. ML Engineer — для тех, кто готов вернуться к учебникам и освоить математику. AI Safety — молодая, но быстро растущая специализация, особенно в крупных компаниях.
FAQ
Нужен ли мне PyTorch для входа?
Чаще нет. Если идёте в прикладную LLM-разработку, можно работать годами без PyTorch — все модели вызываются через HTTP API. PyTorch критичен, если идёте в ML/Research или хотите делать локальные модели и fine-tuning.
Обязательно ли учить LangChain или другой фреймворк?
Не как религию. LangChain и подобные удобны для быстрого прототипирования, но в проде команды часто отказываются от них в пользу тонкого слоя поверх SDK провайдера. Учите как один из инструментов, не как обязательный.
Чем «промпт-инженер» отличается от LLM-разработчика?
В проде граница размыта. Разработчик всё равно отвечает за API, данные, надёжность, стоимость. Чистая роль «промпт-инженер» встречается в крупных компаниях, где есть выделенный человек на исследование промптов. В большинстве команд это часть работы LLM-разработчика.
Какие модели учить в первую очередь?
Освойте одного провайдера глубоко — OpenAI или Anthropic. Когда понимаете концепции (промпты, structured outputs, function calling), переход на другую модель занимает несколько часов чтения документации. Гнаться за каждой новой моделью — путь к выгоранию.
Стоит ли гнаться за «самой новой» моделью?
Только если ваш eval-набор это подтверждает. Часто новая модель не даёт ничего нового на конкретной задаче, но стоит дороже и работает медленнее. Замените модель — прогоните набор — сравните результаты. Если разницы нет, не меняйте.
Можно ли работать удалённо?
Да, и в ИИ-разработке это особенно распространено. Многие задачи делаются автономно, общение идёт через документы и текст. На западные компании из России можно работать через посредников или удалённо — там зарплаты сильно выше.
ИИ заменит самих ИИ-разработчиков?
Это любимый вопрос. Короткий ответ — нет. ИИ ускоряет работу LLM-разработчика (написание промптов, отладка, документация), но не решает за него ключевые задачи: постановка задачи, определение метрик, дизайн пайплайна, ответственность за прод. Разработчиков, которые «просто пишут код», станет меньше. Разработчиков, которые понимают систему целиком, — больше.
Что показывать в портфолио, если всё под NDA?
Делайте pet-проекты с публичным кодом. Хороший pet — это конкретная задача (например, бот для разбора резюме), с README, тестами, eval-набором, метриками и обсуждением выборов архитектуры. Один такой проект бьёт 10 «попробовал OpenAI API в Jupyter».




.png)
