
Оперативная память и кэш: как они связаны и почему это важно знать программисту
Знакомая сцена. Программист написал функцию, которая обходит большой массив. Логика чистая, тестами покрыта, всё работает. Потом он меняет порядок двух вложенных циклов местами — просто потому что так читается удобнее. И код вдруг становится в пять раз медленнее. Те же данные, те же операции, тот же процессор. Что произошло?
Произошло столкновение с реальностью, которую большинство программистов не учитывают, пока она не ударит больно: между процессором и оперативной памятью есть прослойка под названием «кэш», и от того, попадает ваш код в эту прослойку или промахивается, зависит реальная скорость работы. Не теоретическая. Не та, которую вы видите в Big O. А та, которую видит пользователь.
Ниже разберём, как устроена связка ОЗУ и кэша в современных процессорах, почему это важно для производительности и какие конкретные приёмы есть в арсенале программиста, чтобы писать код, который не тормозит из-за промахов кэша.
Что такое ОЗУ и кэш — короткое определение
Оперативная память — это рабочее место компьютера. Когда вы запускаете программу, её код и данные загружаются с диска в ОЗУ, и дальше процессор работает с ними оттуда. Размеры — гигабайты, доступ — наносекунды, всё пропадает при выключении питания.
Кэш — это маленький, но очень быстрый буфер прямо внутри процессора. В нём лежат копии данных из ОЗУ, к которым программа обращалась недавно или с большой вероятностью обратится в ближайшие микросекунды.
Главный фокус в том, что разрыв между скоростью процессорного ядра и скоростью ОЗУ огромный. Современное ядро может выполнять миллиарды операций в секунду, а доступ к ОЗУ занимает примерно столько времени, сколько процессор успел бы выполнить несколько сотен операций. Без буфера между ними процессор большую часть времени простаивал бы в ожидании данных.
Зачем кэш, если у нас есть ОЗУ
Самый частый вопрос новичка: «Если ОЗУ такая быстрая, зачем нужна ещё одна "ещё более быстрая" память?» Ответ — в фундаментальном законе физики: чем меньше расстояние от процессорного ядра до памяти, тем меньше задержка доступа. ОЗУ физически живёт на материнской плате в нескольких сантиметрах от процессора. Свет за наносекунду проходит около 30 сантиметров — а сигнал в кремнии ещё медленнее.
Поэтому в современных процессорах сделали иерархию. Прямо в самом ядре — крошечная, но мгновенная память (кэш L1). Чуть дальше, но больше по объёму — L2. Ещё дальше, общая для всех ядер — L3. И только потом, через шину памяти, — собственно ОЗУ.
Эта иерархия работает по принципу локальности. Программы редко обращаются к случайным адресам — они обычно работают с одними и теми же данными подряд (временная локальность) или с соседними участками памяти (пространственная локальность). Кэш ловит обе закономерности.
Уровни кэша L1, L2, L3 — что это и в каких процессорах сейчас
Чтобы было понятно, насколько разные масштабы у этих уровней, вот реальные цифры из современных процессоров 2026 года.

Уровень | Где живёт | Объём | Задержка | Кто использует |
|---|---|---|---|---|
L1 | В каждом ядре, разделён на инструкции и данные | 32–64 КБ на ядро | ~1 нс (3–5 тактов) | Только это ядро |
L2 | В каждом ядре или на кластер ядер | 256 КБ – 2 МБ на ядро | ~3–4 нс (10–15 тактов) | Ядро или группа ядер |
L3 | Общий для всех ядер | 16–96 МБ суммарно | ~10–15 нс (40–60 тактов) | Все ядра процессора |
ОЗУ | Отдельные модули на материнской плате | 16–128 ГБ типично | ~80–100 нс (300+ тактов) | Вся система |
Чтобы оценить, насколько эти цифры драматичны — переведём задержки в человеческое восприятие. Если время доступа к L1 (1 наносекунда) приравнять к одной секунде, то получится такая картина:
L1 — 1 секунда (мгновенно)
L2 — 3–4 секунды
L3 — около 15 секунд
ОЗУ — полторы минуты
SSD — 14 часов
HDD — 11 дней
То есть когда программа промахивается мимо кэша и идёт в ОЗУ — это эквивалентно тому, что вы хотели взять документ со стола, а он лежит в архиве на другом конце города. Если она ещё и в swap уходит на HDD — это уже архив на другом континенте.
Как процессор находит данные: пошагово
Когда ядру нужны данные по конкретному адресу, оно идёт по иерархии сверху вниз и останавливается на первом попадании.
Проверка L1. Если данные здесь — попадание (cache hit), задержка ~1 нс. Дальше не идём.
L1 промахнулся — проверка L2. Если данные здесь — копируем их в L1 (по правилам политики кэша) и работаем.
L2 тоже промахнулся — проверка L3. Тут же подгружаем в L2 и L1.
L3 промахнулся — идём в ОЗУ. Это самый медленный сценарий из «нормальных». Процессор берёт не один байт, а целую кэш-линию (обычно 64 байта) — потому что соседние данные с высокой вероятностью понадобятся следом.
Данных нет в ОЗУ. Они выгружены на диск из-за нехватки памяти. Срабатывает виртуальная память, и страница подгружается с SSD или HDD — это уже задержка не в наносекундах, а в микросекундах или миллисекундах.
Ключевая деталь, которую часто упускают: процессор всегда читает данные целыми кэш-линиями по 64 байта. Если вы запросили один байт, в кэш загрузится 64 байта подряд — вы и соседи слева-справа. Это и есть пространственная локальность в железе.
Как промахи кэша убивают производительность: пример
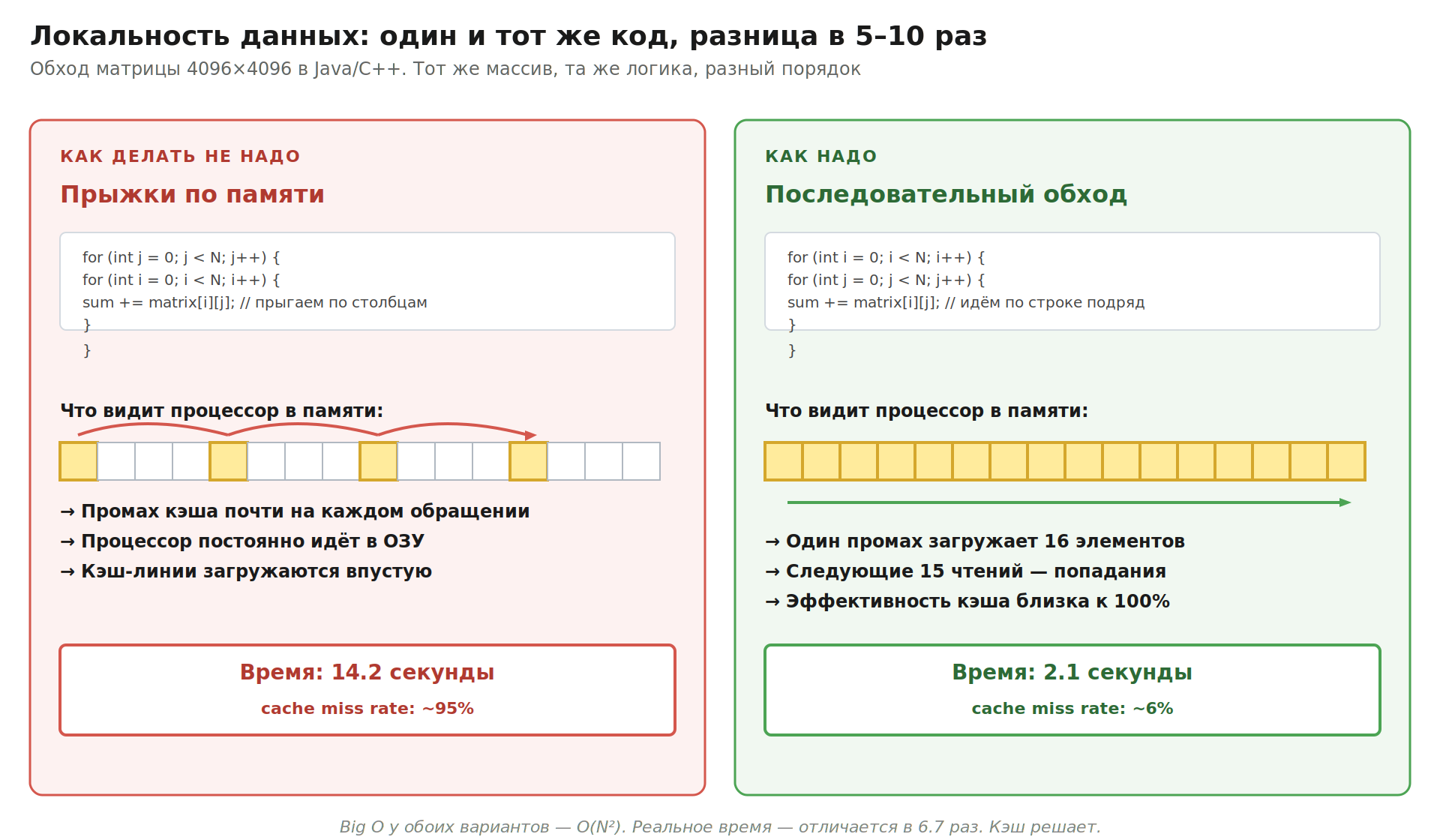
Покажу классический пример, который попадается на собеседованиях в продуктовых компаниях.
Медленный обход двумерного массива:
// Java/C/C++ — column-major порядок
for (int j = 0; j < N; j++) {
for (int i = 0; i < N; i++) {
sum += matrix[i][j];
}
}
Здесь мы прыгаем по памяти большими шагами: matrix[0][0], потом matrix[1][0] (через N элементов), потом matrix[2][0] и так далее. Каждый прыжок при больших N — это новая кэш-линия, новый промах. Кэш не успевает помочь.
Быстрый обход того же массива:
// Тот же массив, row-major порядок
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
sum += matrix[i][j];
}
}
Мы читаем элементы подряд: matrix[0][0], matrix[0][1], matrix[0][2]... Первый промах загружает в кэш 64 байта (16 элементов int), и следующие 15 чтений — это попадания. Эффективность кэша близка к 100%.
На матрице 4096×4096 разница между этими двумя вариантами в Java или C++ — обычно от 5 до 10 раз по времени. Та же логика, тот же объём данных, тот же процессор. Просто один код «дружит» с кэшем, а другой — нет.
В Python (NumPy) ситуация аналогичная, но эффект слабее, потому что NumPy внутри пользуется оптимизированными библиотеками. На чистых питоновских списках разница может быть драматичнее, потому что там вообще нет гарантии последовательного хранения.
Что значит «локальность данных» в реальном коде

Локальность бывает двух типов, и оба важны.
Временная локальность. Если программа обратилась к адресу X, то с большой вероятностью обратится к нему снова в ближайшее время. Простой пример — переменная цикла или счётчик. Кэш хорошо обрабатывает временную локальность, держа недавно использованные данные в L1.
Пространственная локальность. Если программа обратилась к адресу X, то с большой вероятностью обратится к X+1, X+2 и так далее. Простой пример — обход массива по порядку. Кэш ловит это тем, что подгружает соседние 64 байта одной кэш-линией.
Какие структуры данных и приёмы дружат с кэшем:
Дружит с кэшем | Не дружит с кэшем |
|---|---|
Массивы и плотно упакованные структуры | Связные списки с разбросанными по памяти узлами |
Структуры «массив структур» при последовательном обходе | Случайные обращения к большим хеш-таблицам |
Структуры с маленьким размером (укладываются в одну кэш-линию) | Объекты с указателями на другие объекты в разных местах памяти |
Алгоритмы с последовательным доступом (sequential scan) | Алгоритмы с указательной арифметикой по дереву (особенно несбалансированному) |
Чтение по строкам матрицы (для row-major языков) | Чтение по столбцам матрицы в row-major раскладке |
Это не значит, что хеш-таблицы и связные списки нужно выбросить — они решают свои задачи. Это значит, что когда производительность критична, выбор структуры данных зависит и от Big O, и от того, как она будет ложиться в кэш.
False sharing: коварная проблема многопоточности
В многоядерных системах есть отдельный класс проблем, связанных с кэшем — false sharing. Происходит так. У вас есть два потока на двух разных ядрах. Каждый поток обновляет свою переменную. Если эти две переменные физически лежат в одной кэш-линии (64 байта), процессор вынужден постоянно синхронизировать состояние этой линии между ядрами — даже если потоки логически работают с разными данными.
Результат: код, который должен ускориться от распараллеливания, наоборот замедляется, иногда в разы.
Пример false sharing на Java:
class Counter {
long a; // обновляет поток 1
long b; // обновляет поток 2
}
// a и b лежат рядом в памяти — они попадут в одну кэш-линию
// Потоки будут "драться" за эту линию
Решение через padding:
class Counter {
long a;
long pad1, pad2, pad3, pad4, pad5, pad6, pad7; // 56 байт прокладки
long b;
// Теперь a и b в разных кэш-линиях
}
В Java 8+ это делается через аннотацию @Contended. В .NET есть похожие механизмы. На уровне языка C/C++ — через alignas(64).
Если вы пишете высоконагруженный многопоточный код и не знаете про false sharing — это потенциальный замедлитель, который очень сложно поймать профилировщиком на первый взгляд.
Что происходит, когда не хватает ОЗУ
Если данных в ОЗУ слишком много и они не помещаются, операционная система начинает выгружать неиспользуемые страницы на диск — в файл подкачки (swap на Linux, pagefile на Windows). Это виртуальная память, и для программы это прозрачно: с её точки зрения память просто продолжает быть, только обращение к выгруженным страницам становится в тысячи раз медленнее.
Что происходит на практике:
Лёгкая нехватка памяти. Система иногда подкачивает страницы с диска, иногда замедления почти не видно. Обычно проявляется в виде «тормозит после переключения окон».
Средняя нехватка памяти. Заметные паузы на десятки миллисекунд при работе с активными программами. Курсор подтормаживает, окна открываются с задержкой.
Сильная нехватка памяти. Система впадает в trashing — большую часть времени тратит на перекачку страниц между ОЗУ и диском вместо полезной работы. Внешне выглядит как полное зависание, хотя процессор загружен на 100%.
Кэш при этом не помогает вообще никак — он работает только с тем, что уже в ОЗУ. Если данные ушли в swap, спасает только увеличение объёма физической памяти или оптимизация её потребления.
Подробнее про разные виды памяти ПК и их роли — в материале «Память компьютера: виды и классификация».
Сколько ОЗУ реально нужно в 2026 году
Цифры — для понимания, не для строгого следования. Реальные потребности зависят от стека и проектов.
Сценарий | Минимум | Комфортно |
|---|---|---|
Веб-сёрфинг, офис, простой код | 8 ГБ | 16 ГБ |
Фронтенд: VS Code, браузер, dev-server | 16 ГБ | 32 ГБ |
Бэкенд: IDE, Docker с 3–5 контейнерами, БД локально | 16 ГБ | 32 ГБ |
Data Science: Jupyter, pandas, средние датасеты | 32 ГБ | 64 ГБ |
ML: обучение моделей локально, большие датасеты | 32 ГБ + GPU память | 64–128 ГБ + GPU |
Геймдев, 3D, видеомонтаж | 32 ГБ | 64 ГБ |
В 2026 году 8 ГБ для разработки — это уже мучения. Современные IDE с подсветкой типов, локальные ИИ-помощники в редакторе, контейнеры с зависимостями съедают память легко. Если разработка — это работа, а не хобби раз в неделю, 32 ГБ — разумный минимум.
Практические выводы для программиста
Что из всего этого реально использовать в работе:
Ситуация | Что делать |
|---|---|
Пишете обычный продуктовый код | Не думайте о кэше. Читаемость и корректность важнее. Микро-оптимизации без замеров обычно бесполезны |
Профилировщик показал узкое место в горячем цикле | Проверьте порядок обхода данных, замените связные списки на массивы там, где это возможно, посмотрите на структуры данных |
Пишете высокопроизводительный код (рендеринг, симуляции, движки) | Думайте о кэше с самого начала. Data-oriented design — это про укладку данных в память для оптимального доступа |
Параллелите задачи между потоками | Следите за false sharing. Один тест: если масштабирование на N потоков даёт меньше N-кратного ускорения — проверьте, не конкурируют ли потоки за кэш-линии |
Проектируете кэширование в приложении | Идея кэша работает не только в железе. Redis перед БД, in-memory кэш перед Redis — та же иерархия, тот же принцип |
Выбираете железо для разработки | На длинной дистанции дополнительная ОЗУ важнее лишних мегагерц процессора, особенно если работаете с Docker и виртуалками |
Главное, что нужно запомнить: иерархия «кэш → ОЗУ → диск» работает не только в железе. Эта же логика — «маленький быстрый буфер перед большим медленным хранилищем» — повторяется на уровне приложений: in-memory кэш перед БД, CDN перед серверами, локальный кэш браузера перед сетью. Понимая принцип на уровне процессора, легче проектировать кэши на любом уровне.
Подробнее про устройство процессоров, тактовые частоты и архитектуру — в материале «Процессор: устройство и принципы работы».
FAQ
Чем кэш процессора отличается от ОЗУ?
Объёмом, скоростью и расположением. Кэш — это маленький (десятки килобайт – десятки мегабайт), очень быстрый (1–15 наносекунд) буфер внутри самого процессора. ОЗУ — большая (гигабайты), сравнительно медленная (~80 нс) память на отдельных модулях. В кэше лежат копии данных из ОЗУ, к которым процессор недавно обращался или собирается обратиться.
Почему нельзя сделать всю память такой же быстрой, как L1?
Два ограничения: физика и экономика. Физика — чем быстрее память, тем ближе к ядру процессора она должна быть; разместить гигабайты прямо на кристалле невозможно. Экономика — память типа L1 в десятки раз дороже за бит, чем DRAM в обычных модулях ОЗУ. Гигабайт такой памяти стоил бы как небольшой автомобиль.
Что такое кэш-линия и почему важно про неё знать?
Кэш-линия — это минимальная единица обмена между уровнями памяти, обычно 64 байта. Когда процессор запрашивает один байт из ОЗУ, в кэш загружается вся линия из 64 байт. Это важно по двум причинам. Первая: если ваши данные лежат компактно и подряд, после одного промаха идут попадания — кэш работает эффективно. Вторая: если два потока работают с переменными в одной кэш-линии, возникает false sharing и потоки начинают конкурировать за линию даже без логической связи.
Как понять, страдает ли мой код от промахов кэша?
Профилировщики уровня perf на Linux, VTune от Intel, AMD uProf на AMD-процессорах показывают точные счётчики промахов кэша по уровням. На уровне приложения косвенный признак — это когда замена структуры данных без изменения логики даёт значительное ускорение, или когда последовательный обход массива работает в разы быстрее случайного при тех же O(N) операций.
Что важнее для производительности — больше ОЗУ или быстрее процессор?
Зависит от задачи. Если вы упираетесь в нехватку памяти и система начинает свопиться — больше ОЗУ даст драматичный эффект, а быстрее процессор не поможет вообще. Если данные помещаются в ОЗУ — быстрее процессор полезнее, особенно с большим кэшем третьего уровня. Для разработчика на длинной дистанции ОЗУ важнее, потому что одновременно открытые IDE, контейнеры, браузер и локальные ИИ-помощники съедают её гигабайтами.
Можно ли вручную управлять, что лежит в кэше?
Прямого API «положи это в L1» в обычных языках программирования нет — управление кэшем полностью отдано процессору и его алгоритмам предсказания. Но косвенно повлиять можно: подсказками (prefetch-инструкциями), компоновкой данных в памяти, выравниванием структур по границам кэш-линий. В C/C++ для этого есть встроенные функции и атрибуты. В высокоуровневых языках (Python, JavaScript) такого контроля нет — там это управляется на уровне рантайма.
В моём ноутбуке 16 ГБ ОЗУ — этого хватит для разработки?
В 2026 году — впритык. Хватит для фронтенда без Docker, базовой бэкенд-работы без больших контейнерных стеков, обычного кодирования. Не хватит, если вы регулярно держите запущенные виртуалки, тяжёлые БД локально, контейнерные оркестраторы или работаете с большими данными. Если возможность апгрейда есть — 32 ГБ снимет почти все ограничения на ближайшие пару лет.