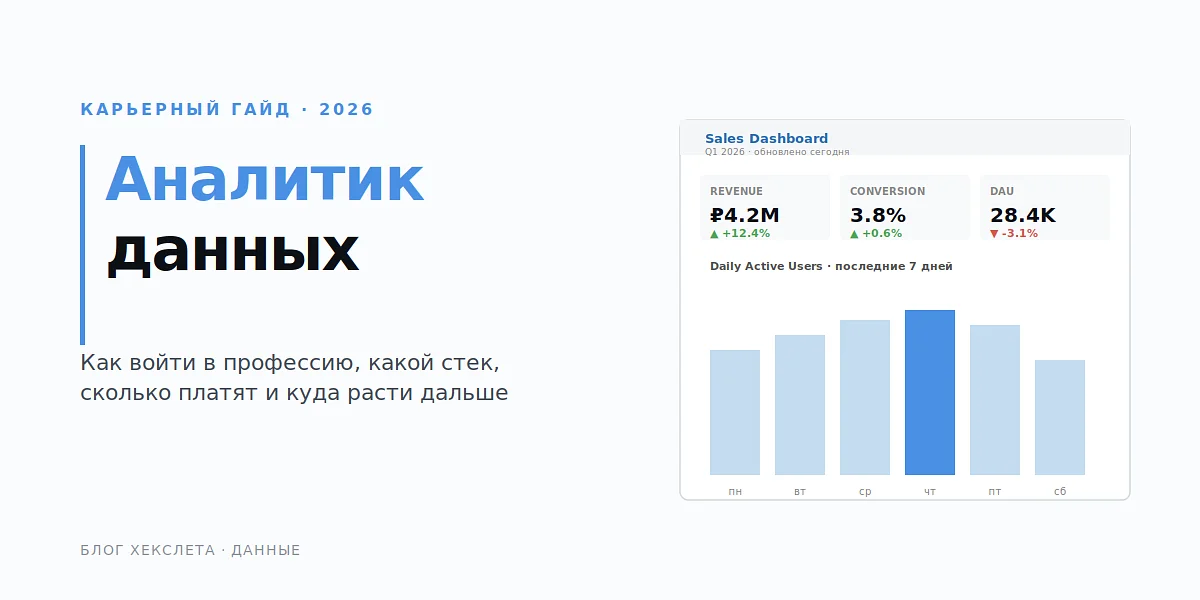
Аналитик данных в 2026: как войти в профессию
«Хочу в данные» — фраза с подвохом. Когда человек её произносит, в голове у него может быть три совершенно разные профессии: аналитик данных, инженер данных или Data Scientist. Все три работают с цифрами, но день у них устроен по-разному, требования другие, зарплаты тоже разные. Если выбрать не ту дверь — потеряете полгода учёбы.
Эта статья — про аналитика данных. Самую массовую и доступную для входа из трёх. Разберём, чем работа реально отличается от Data Science и инженерии данных, какой стек просят у джуниора в 2026 году, сколько платят, и в каком порядке учить, чтобы не утонуть.
Сразу одна важная оговорка. Вакансии по аналитике данных описаны очень неоднородно: в одной компании это работа с дашбордами и Excel, в другой — модели и эксперименты. Поэтому смотрите не на заголовок «Junior Data Analyst», а на блок «обязанности». Реальная работа прячется там.
Цельный маршрут от нуля до первой работы — программа «Аналитик данных» на Хекслете: SQL, BI-инструменты, Python для анализа, A/B-тесты и продуктовые метрики.
Три профессии «про данные»: где проходит граница
Сначала разберёмся, кого с кем не путать. Это три отдельные карьерные траектории — не три ступеньки.
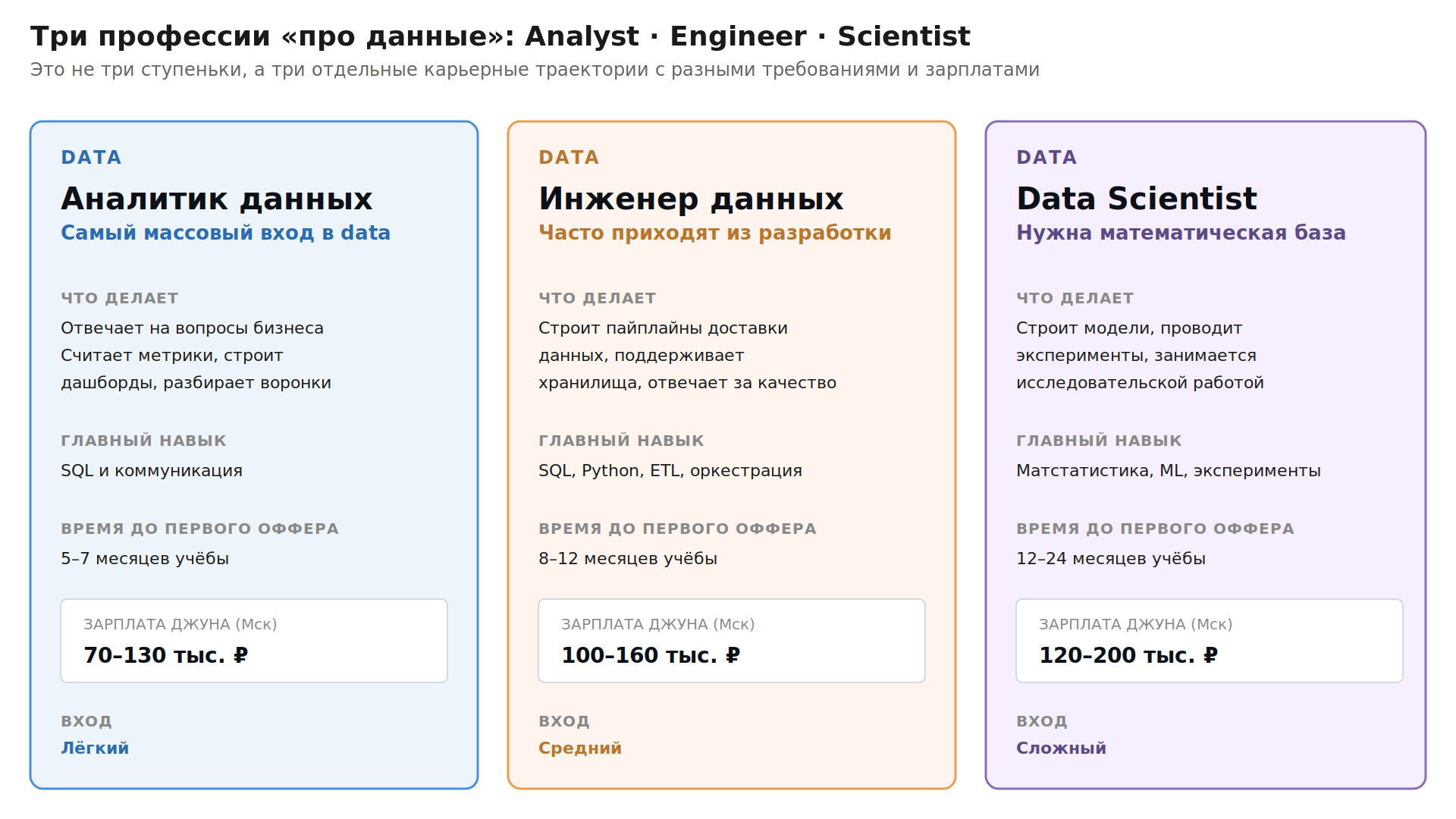
Профессия | Чем занят день | Главный навык | Точка входа для джуна |
|---|---|---|---|
Data Analyst | Отвечает на вопросы бизнеса. Считает метрики, строит дашборды, разбирается, почему упала конверсия | SQL и коммуникация | Лёгкая. Самый массовый и доступный вход в data |
Data Engineer | Строит и поддерживает пайплайны доставки данных, отвечает за хранилища и качество сырья | SQL, Python, ETL/ELT, оркестрация | Средняя. Часто переходят из разработки |
Data Scientist | Строит модели, ставит эксперименты, занимается исследовательской работой с данными | Матстатистика, ML, эксперименты | Сложная. Обычно нужна математическая база и опыт |
Самый частый сценарий ошибки — человек хочет «крутого Data Science», начинает учить машинное обучение и через три месяца понимает, что без SQL и понимания бизнеса его модели никому не нужны. Поэтому почти все эксперты советуют один путь: сначала аналитик, потом — если затянет именно исследовательская сторона — переход в DS через год-два работы.
Дальше в статье — только про путь аналитика.
Как реально выглядит день аналитика данных
В представлении новичка аналитик сидит весь день с SQL и красивыми графиками. В реальности SQL занимает примерно треть рабочего времени, а остальное — общение с людьми, объяснения и борьба с неточными формулировками.
Время | Что происходит |
|---|---|
10:00–10:30 | Дейли. Что нужно команде в этот спринт, какие отчёты горят, кто чего ждёт от вас сегодня |
10:30–11:30 | Слак или почта. Маркетинг просит «срочно посмотреть, почему упала конверсия». Уточняете, какую конверсию, на каком шаге, за какой период |
11:30–13:00 | Пишете SQL под задачу. Иногда выясняется, что «активный пользователь» в маркетинге и в базе — это разные сущности. Идёте уточнять, а не пишете «на удачу» |
13:00–14:00 | Обед или встреча с продактом. Обсуждаете, как сформулировать гипотезу для следующего A/B-теста |
14:00–15:30 | Собираете дашборд. Уточняете подписи, оси, единицы измерения. Половину времени тратите не на код, а на «как это понять с одного взгляда» |
15:30–17:00 | Презентация результата. Не «вот цифра», а «вот вывод, вот ограничение, вот что я предлагаю делать дальше» |
17:00–18:00 | Документация. Какие определения метрик использовали, какие допущения сделали — чтобы через месяц никто не задавал тех же вопросов снова |
Главное, что бросается в глаза в реальной работе: аналитик постоянно общается. С продактами, маркетологами, менеджерами, разработчиками. «Тихая работа с цифрами в углу» — это миф. Если вы шли в data ради того, чтобы поменьше говорить с людьми — возможно, инженер данных вам подойдёт лучше: там общения заметно меньше.
Аналитик данных vs Python-разработчик: где граница
Оба пишут на Python. Оба знают SQL. Оба работают с данными. Но цели разные, и переходы туда-обратно — это полноценная смена профессии.
Критерий | Аналитик данных | Python-разработчик (бэкенд) |
|---|---|---|
Главный результат | Вывод, метрика, дашборд, слайд | Работающий сервис, API, миграции |
SQL | Каждый день, глубоко: оконные функции, CTE, оптимизация | Нужен, но обычно «уровень JOIN и индексов» |
Python | pandas, скрипты, автоматизация отчётов | Фреймворки, тесты, деплой, продакшен-код |
Что выкатывает в прод | Редко выкатывает код напрямую — обычно дашборды и отчёты | Большая часть работы — про продакшен |
Кто читает результат | Бизнес — продакт, маркетинг, руководство | Другие разработчики, иногда сам автор через полгода |
Что важнее всего | Понять вопрос бизнеса и дать честный ответ | Написать поддерживаемый код и не уронить прод |
Для аналитика Python — это инструмент. Для разработчика — профессия. Переход «из аналитики в разработку» возможен, но это не «доучу Django и готово». Нужно догонять архитектуру, паттерны, тестирование, инфраструктуру — то есть примерно год полноценной работы.
В каких индустриях чаще берут джуниора
Разные сферы по-разному охотятся за аналитиками. Где-то конкуренция за джунов жесточайшая, где-то их буквально не хватает.
Сфера | Чем занят аналитик | Что специфично |
|---|---|---|
E-commerce и маркетплейсы | Воронки, конверсии, сегменты, эффект акций и распродаж | Высокий спрос, но риск смешать «органический» рост с эффектом распродаж |
Финтех и банки | Аккуратность, регуляторные требования, воспроизводимость отчётов | Доступ к данным через заявки и согласования, медленнее процессы |
Продуктовые IT-компании | Событийные данные в приложениях, retention, продуктовые эксперименты | Часто «грязные» логи и проблемы с трекингом — приходится их чинить параллельно |
Реклама и AdTech | Атрибуция, оптимизация рекламных кампаний, прогнозы спроса | Много нюансов с разными источниками трафика и моделями оплаты |
Геймдев | Поведение игроков, монетизация, баланс игры | Узкая специфика; знание индустрии добавляет 30% к вилке |
B2B и корпоративный сектор | Отчёты для руководства, план-факт, операционные метрики | Excel-наследие, ручные корректировки в данных, медленный темп |
Медиа и контент | Метрики вовлечённости, ретеншн читателей, A/B-тесты заголовков | Часто меньше платят, но более интересные продуктовые задачи |
Джуну необязательно «любить банк» или «гореть геймдевом» — на старте все эти индустрии используют примерно одни и те же SQL-паттерны и метрики. Отрасль выбирайте по тому, насколько вам интересно её содержание: с грустью смотреть на финансовые отчёты годами — так себе план.
Сколько платят: зарплаты аналитика в 2026
Цифры — собрал из открытых обзоров и опросов сообществ в первом квартале 2026 года. На руки, до налогов. Внутри одного грейда вилка может быть в 1.5–2 раза в зависимости от компании и отрасли.
Уровень | Опыт | Москва / Питер | Регионы | Зарубежные компании (удалёнка) |
|---|---|---|---|---|
Junior | 0–1 год | 70–130 тыс. ₽ | 50–90 тыс. ₽ | от $1500 |
Middle | 1–3 года | 130–230 тыс. ₽ | 90–160 тыс. ₽ | $2500–4500 |
Senior | 3–5 лет | 230–380 тыс. ₽ | 170–280 тыс. ₽ | $4500–7500 |
Lead / Head of Analytics | 5+ лет | 320–500+ тыс. ₽ | 250–380 тыс. ₽ | $6000–10000 |
Несколько важных наблюдений по рынку 2026 года:
Финтех и крупные продуктовые компании платят на 30–50% больше, чем медиа и B2B-сектор
Знание продуктовой аналитики (метрики типа DAU/MAU, retention, когорты) даёт прибавку — джуны с этим навыком уходят ближе к верхней границе вилки
Чистые «отчётники» в Excel и Power BI без SQL — самая низкоплачиваемая ветка, но и самая доступная для входа
Удалёнка на западных нанимателей реально работает, но требует английского на уровне свободного письменного и хотя бы среднего разговорного
Стек джуниора-аналитика в 2026
Разбил на три уровня по обязательности. Что критично знать сразу, что желательно подтянуть к собесу, что выделит среди других кандидатов.
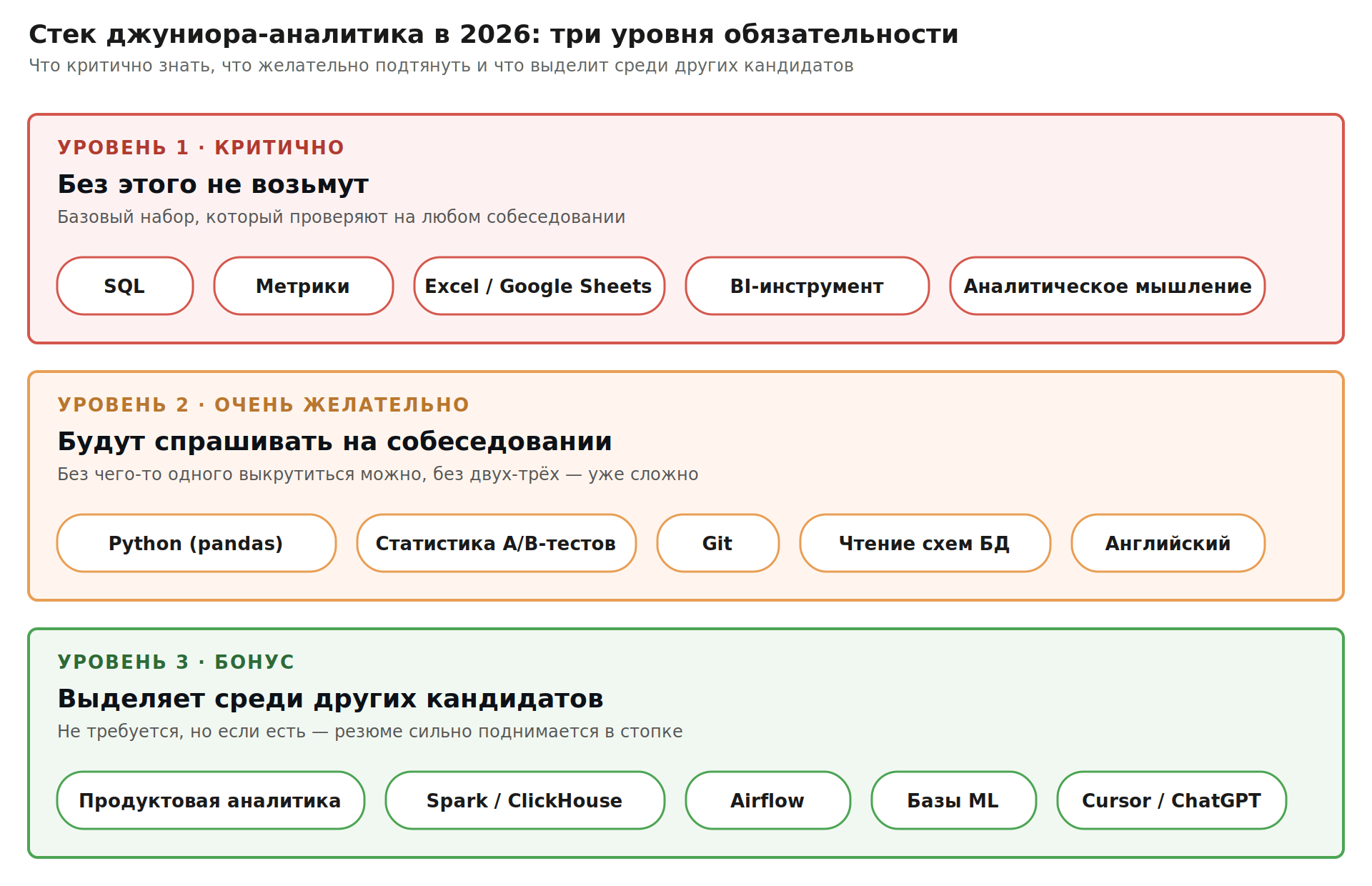
Критично — без этого не возьмут
Область | Что нужно |
|---|---|
SQL | SELECT, JOIN всех видов, GROUP BY, HAVING, подзапросы, базовые оконные функции |
Метрики | Понимание конверсии, ARPU, воронок, когорт — не названия, а смысл |
Excel или Google Sheets | Сводные таблицы, VLOOKUP, базовые формулы, диаграммы |
BI-инструмент | Один инструмент до уверенного уровня: Tableau, Superset, Power BI, Looker — что угодно из этого |
Аналитическое мышление | Умение разложить размытый вопрос «почему упали продажи» на проверяемые гипотезы |
Желательно — будут спрашивать на собеседовании
Область | Зачем |
|---|---|
Python (pandas, numpy) | Когда задача не помещается в SQL — выгрузить, обработать, посчитать |
Статистика A/B-тестов | Ошибки I и II рода, доверительные интервалы — на уровне «понимаю, зачем» |
Git | Положить SQL и ноутбуки в репозиторий с осмысленной историей коммитов |
Чтение схемы БД | Разобраться, где факты, где справочники, где связующие таблицы |
Английский | Чтение документации обязательно. Письменный для удалёнки на запад |
Бонус — выделяет среди других кандидатов
Область | Где пригодится |
|---|---|
Продуктовая аналитика | Когорты, retention, метрики жизненного цикла. Сильно ценится в продуктовых командах |
Опыт работы с большими данными | Spark, ClickHouse — для финтеха, рекламы, крупных продуктов |
Airflow или подобный оркестратор | Когда отчёты автоматизируются, а не делаются руками |
Базовая ML-грамотность | Регрессии, кластеризация — помогает на собесе в продуктовых компаниях |
Cursor, Copilot, ChatGPT для SQL | В 2026-м это уже часть базовой грамотности — но только если понимаете, что вам сгенерировали |
SQL до уверенного джуниора: чек-лист тем
Работодатель никогда не спрашивает «знаете ли вы SQL» — он смотрит, как вы думаете запросом. Вот список тем, который должен быть пройден до собесов.
Тема | Зачем на работе |
|---|---|
JOIN всех видов и риск дубликатов | Иначе метрики «раздуваются» незаметно: один заказ дублируется в отчёт пять раз |
WHERE vs HAVING | Типичная ошибка в агрегатах. На собесах часто дают задачу, где это критично |
Подзапросы и CTE (WITH ...) | Читаемость сложных запросов. CTE — практически обязательны на миддле |
Оконные функции | ROW_NUMBER, RANK, SUM OVER, LAG/LEAD — когорты, скользящие окна, ретеншн |
NULL и COALESCE | Тихие баги в отчётах. JOIN с NULL — самый частый источник «куда делись строки» |
Дубликаты и пропуски | «Цифра сошлась» ≠ «цифра честная». Уметь проверять качество данных |
Дата/время и часовые пояса | «За вчера» в Москве и в Лондоне — два разных множества заказов |
Простой тест уровня: если вы можете словами объяснить, почему количество строк в результате изменилось после JOIN — вы уже за порогом «новичка». Если нет — продолжайте практиковаться.
Метрики: где ломается здравый смысл
В реальной работе самые большие ошибки случаются не в SQL, а в интерпретации цифр. Вот пять ловушек, в которые регулярно попадают даже опытные.
Смешение числителя и знаменателя. «Конверсия выросла на 5%» — конверсия чего во что, в какой период, для какой аудитории. Без фиксации воронки это бессмысленная фраза.
Среднее без медианы и квантилей. Один пользователь, который купил товар за миллион рублей, поднимет средний чек по магазину так, что разрушит всю отчётность. Медиана и распределение спасают.
Двойной учёт. Один пользователь — два устройства, два заказа в одной корзине, две сессии за день. Что считать «уникальным» нужно решать до запроса, а не после.
Survivorship bias. Смотрите только на тех, кто прошёл всю воронку до конца, и делаете выводы про всех вошедших. Те, кто отвалился — статистически невидимы, и это меняет картину.
Корреляция vs причинность. «После изменения X выросло Y» не доказывает, что именно X было причиной. Может быть сезонность, может быть параллельная акция конкурента, может быть случайность.
Хороший отчёт всегда содержит оговорку: какие допущения сделали и что сломается, если они окажутся неверны.
A/B-тесты без самообмана
От джуниора-аналитика не ждут построения тестов с нуля — этим обычно занимается DS или сеньор. Но участвовать в обсуждении и не позориться нужно уже с первой работы.
Тема | Что должны понимать |
|---|---|
Первичная и охранные метрики | Что оптимизируем и что нельзя «убить» в процессе. Без охранных метрик легко улучшить конверсию, обвалив revenue |
Размер выборки и длительность | «Закончили через два дня, потому что уже видно» — почти всегда самообман. Сезонность и недельный цикл продукта никто не отменял |
Проверка раскладки | Действительно ли пользователи равномерно попали в варианты или система сегментации сбоит |
Статзначимость vs практическая значимость | «Статистически значимо» ещё не «бизнесу выгодно». Учитывайте стоимость внедрения и риски |
Подглядывание (peeking) | Смотреть на p-value каждый день и останавливать тест, когда стало значимо — путь к ложноположительным результатам |
Если вы не любите эту часть — она всё равно догонит. Без понимания A/B-тестов вас будут постоянно просить «доказать очевидное», а вы не сможете это сделать корректно.
План учёбы: с чего начать, чтобы не утонуть
Самая частая ошибка новичка — пытаться учить SQL, Python, BI и Tableau одновременно. В итоге плохо знает всё. Правильный порядок — последовательный.
Этап | Что осваиваете | Сколько времени |
|---|---|---|
1. SQL до уровня уверенного джуна | JOIN, GROUP BY, подзапросы, CTE, базовые оконные функции. На реальных задачах, не учебных | 2–3 месяца |
2. Один сквозной проект «от вопроса до ответа» | Возьмите открытый датасет (Kaggle, Google Trends), сформулируйте бизнес-вопрос, ответьте на него запросом, оформите вывод | 2–3 недели |
3. Один BI-инструмент | Tableau или Superset — освоить так, чтобы делать дашборды с фильтрами и понятными подписями | 3–4 недели |
4. Метрики и продуктовая аналитика | Когорты, retention, воронки, RFM-сегментация — на уровне «понимаю, считаю, могу объяснить» | 3–4 недели |
5. Python для анализа | pandas на базовом уровне, чтение CSV, простая обработка, воспроизводимый ноутбук | 3–4 недели |
6. Статистика и A/B-тесты | Основы: ошибки I/II рода, доверительные интервалы, статзначимость. Базовый минимум без углубления в матстат | 2–3 недели |
7. Портфолио и подготовка к собеседованиям | 3–4 публичных проекта на GitHub, прорешать типовые задачи, mock-собесы | 4–6 недель |
Реалистичный срок до первого оффера — 5–7 месяцев, если заниматься 15–20 часов в неделю. Большинство людей идёт с работой параллельно, поэтому реальный срок ближе к семи месяцам, чем к пяти.
Эта последовательность близка к траектории «Аналитик данных» на Хекслете: от основ SQL к продвинутой аналитике, BI-инструментам, продуктовым задачам и Python для анализа.
Антипаттерны новичка в аналитике
За несколько лет наблюдений за людьми, заходящими в data, накопилась короткая инвентаризация типичных провалов.
Начать с красивого BI до уверенного SQL. Получите картинку без доверия к цифрам — и не сможете её защитить, когда спросят «откуда эти данные».
Учить пять диалектов SQL параллельно. PostgreSQL, MySQL, ClickHouse, Snowflake, BigQuery — синтаксис разный, логика одинаковая. Освойте один до глубины, остальные подберёте на работе за неделю.
Игнорировать домен. Аналитик в маркетплейсе и в B2B SaaS говорит разными словами про одни и те же метрики. Не понимая, что вы анализируете, вы будете писать «красивый SQL к несуществующей сущности».
Сразу метить в Data Science. Хотите ML — сначала станьте крепким аналитиком на год-два, потом переходите. Иначе будете строить модели, которые никто не использует.
Не вести журнал гипотез и решений. Через месяц вы не вспомните, почему приняли именно такое решение по сегментации. Это бьёт по карьере внутри компании — кажется, что вы непостоянны в выводах.
Доверять ИИ-инструментам слепо. ChatGPT уверенно напишет SQL-запрос, который выглядит правильно и возвращает результат. Только результат может быть неправильным из-за тонкости JOIN или фильтра, которую ИИ не заметил. Проверяйте.
Что положить в портфолио
Главный принцип: ревьюер открывает GitHub раньше, чем дочитывает резюме. Поэтому портфолио важнее списка курсов.
Что включить | Почему |
|---|---|
README на человеческом языке | Какой был вопрос, какие данные, какие ограничения, что решили не делать и почему |
SQL с комментариями | В неочевидных местах — короткая фраза «почему именно так». Не комментировать SELECT, но прояснять JOIN-логику |
Один дашборд | Скрин плюс описание метрик и фильтров. Если можно — публичная ссылка |
A/B-разбор | Даже на учебных данных. Гипотеза → метрика → проверка → вывод с оговорками |
Журнал определений | Что вы считаете «пользователем», «заказом», «сессией». Показывает зрелость работы с данными |
Воспроизводимый ноутбук | С requirements.txt, без жёстко зашитых путей вроде C:\Users\... |
Чего быть НЕ должно: скриншотов сертификатов вместо проектов, ноутбуков с захардкоженными путями к локальным файлам, проектов «провёл исследование» без воспроизводимости, выгрузок с персональными данными в публичном репо.
Собеседование аналитика: что спрашивают
Типичный собес для джуна — три блока, в зависимости от компании могут быть в разные дни или одной встречей.
Блок 1: SQL на практике
«Дано две таблицы: orders и users. Напишите запрос, который вернёт топ-10 пользователей по сумме заказов за последние 30 дней»
«Объясните разницу между INNER JOIN и LEFT JOIN на пальцах»
«Почему количество строк в результате изменилось после JOIN?» — даётся конкретный пример
«Напишите запрос, который посчитает retention пользователей по неделям»
Блок 2: мышление аналитика
«Конверсия упала на 15% за неделю. Что проверите первым делом?»
«Как объясните результат A/B-теста маркетологу, который не понимает p-value?»
«Два источника данных показывают разные цифры по одной метрике. Что делаете?»
«Как поймёте, что метрика посчитана честно?»
Блок 3: метрики и продукт
«Что такое retention и чем отличается от churn?»
«Чем отличаются N1-retention и N7-retention?»
«В чём проблема со средним чеком как главной метрикой?»
«Какую метрику вы бы выбрали для оценки качества рекомендательной системы?»
Красные флаги с вашей стороны, после которых обычно не зовут на следующий этап: «я хочу сразу в DS, аналитика мне как ступенька», «не люблю SQL — но Python знаю», «всё посчитаю в ChatGPT», «у меня нет проектов, я только курсы заканчивал».
Куда расти из аналитика данных
Аналитик — это не тупик. Через 2–3 года работы открывается несколько траекторий.
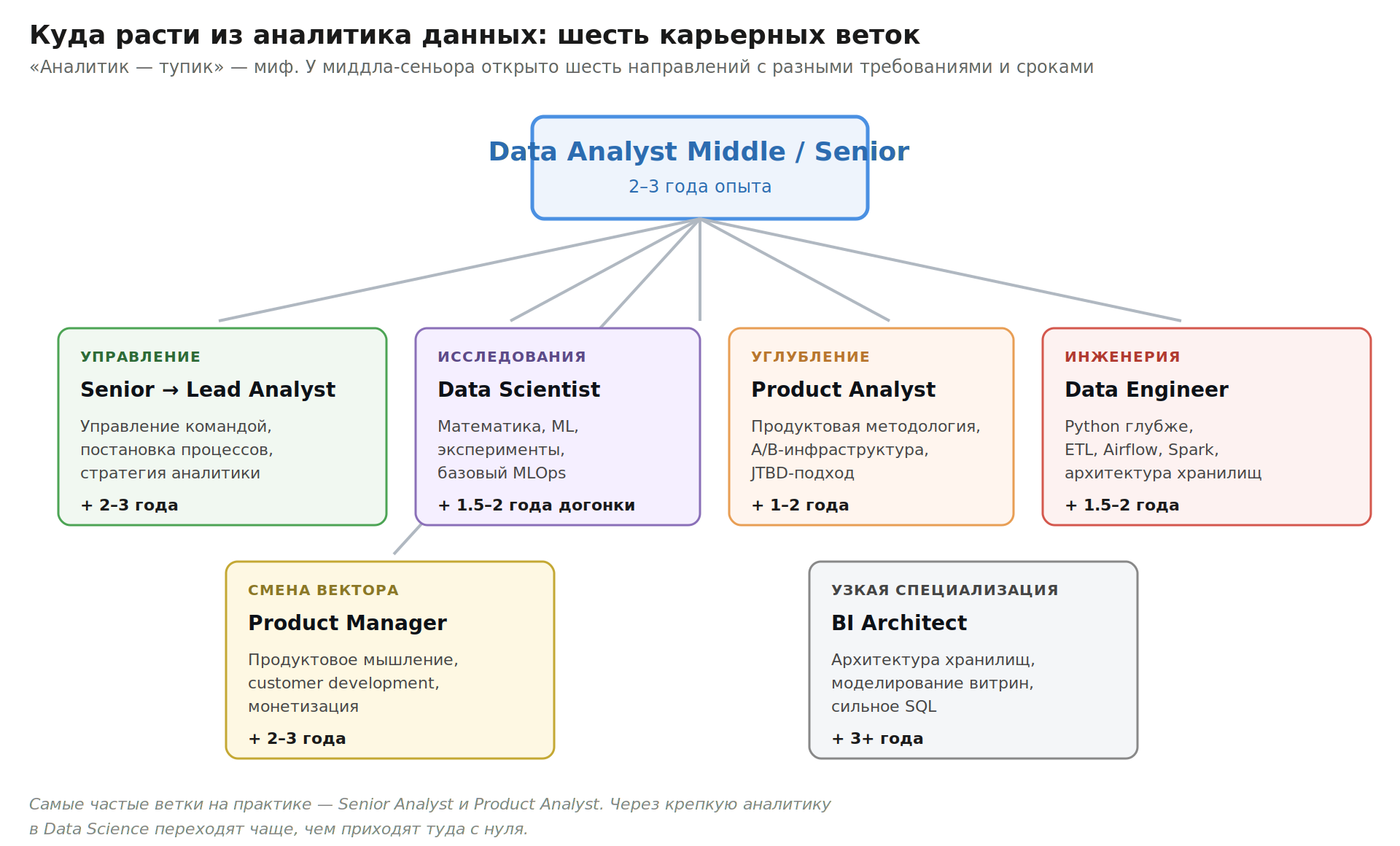
Куда | Что подтянуть | Сколько занимает |
|---|---|---|
Senior Analyst → Lead | Управление командой, постановка процессов, стратегия аналитики | 2–3 года из миддла |
Data Scientist | Математика, ML, эксперименты, MLOps базово | 1.5–2 года догонки |
Product Analyst (углубление) | Продуктовая методология, A/B-инфраструктура, JTBD | 1–2 года |
Data Engineer | Python глубже, ETL, Airflow, Spark | 1.5–2 года |
Product Manager | Продуктовое мышление, customer development, монетизация | 2–3 года, нужен опыт в продуктовых задачах |
BI Architect | Архитектура хранилищ данных, моделирование витрин | 3+ года, нужно сильное SQL и понимание архитектуры |
Самые частые ветки на практике — рост в Senior Analyst и переход в Product Analyst. Реже, но стабильно — в Data Science (через крепкую аналитику легче, чем сразу из учёбы) и в Data Engineering. Переход в продакт-менеджмент — отдельная история, но и она вполне реальна, если в работе много общения с продуктовой командой.
FAQ
Нужна ли математика как в университете?
Для джуниора-аналитика — нет. Нужна логика, SQL и честная интерпретация цифр. Базовая статистика на уровне «понимаю, что такое статзначимость и зачем она» — да. Доказательства теорем и матан в работе не используются. Глубокая математика пригодится, если будете двигаться в Data Science.
Tableau, Power BI или Superset — что учить?
Учите тот, который используют в вакансиях вашего рынка. В России чаще встречаются Superset, Yandex DataLens и Power BI. В международных — Tableau и Looker. Концепции у всех общие, переход между ними занимает 1–2 недели. Главное — освоить один глубоко, а не пять поверхностно.
Можно ли войти в профессию без английского?
Можно, но это срежет половину доступных вакансий и большинство хорошей документации. Минимум — уметь читать английский pre-intermediate. Устный для первой работы в РФ обычно не нужен. Для удалёнки на западные компании — обязательно письменный и хотя бы средний устный.
Сколько времени до первого оффера?
Реалистично — 5–7 месяцев, если заниматься 15–20 часов в неделю. Меньше 10 часов — растянется до года. Главный фактор скорости — не сколько часов учёбы, а сколько реальных публичных проектов вы успели сделать. Один сильный проект перевешивает три «прошёл курс».
Нужен ли Excel в 2026 году?
Да. Половина команд в России живёт в Excel или Google Sheets для оперативной работы, и даже сильные аналитики используют их для быстрых прикидок. Сводные таблицы, VLOOKUP, базовые формулы — must have. На крупных задачах их заменяют SQL и BI, но как ежедневный инструмент Excel никуда не делся.
Стоит ли сразу учить Spark и Airflow?
Нет. Это инструменты дата-инженеров, и аналитику они почти не нужны на старте. Имеет смысл подтянуть после того, как уверенно работаете с SQL и понимаете, зачем вам оркестрация. Иначе это имитация знания инженерии данных без основы.
ИИ-инструменты сделают профессию ненужной?
Нет, но они меняют требования. В 2026-м умение работать с Cursor, ChatGPT или Claude для написания SQL — часть базовой грамотности. Но они усиливают, а не заменяют аналитика. ИИ может написать запрос за минуту, но не может объяснить продакту, почему конверсия упала именно сейчас и что с этим делать. Аналитик с ИИ и без понимания доменa — это просто оператор, который сам себе верит. Подробнее — в обзоре лучших ИИ для кодинга.
А если я хочу сразу в Data Science?
Можно, но честнее перейти туда из аналитики через 1–2 года работы. Прямой вход в DS с нуля требует серьёзной математической базы (вышмат, статистика, ML-курсы уровня магистратуры) и обычно занимает 1.5–2 года учёбы. Через аналитику — те же 1.5–2 года, но с зарплатой и реальным опытом, а не на голом обучении.





