Как устроена операционная система: ядро, процессы, память и системные вызовы
Знакомая сцена. У вас в проде падает сервис с ошибкой «Out of memory: Killed process 1234». Вы смотрите в логи, видите процесс, который ел всё больше памяти, и тут возникает вопрос: кто его убил и за что. Ответ — операционная система. Она наблюдала за процессом, поняла, что памяти не хватает на всех, и выбрала жертву по своему алгоритму. Это не баг и не сбой. Это работа OOM-killer'а, одной из подсистем ядра Linux.
Таких моментов в работе разработчика много. Сервис тормозит — а почему: процессор загружен, или процесс ждёт диск, или его постоянно переключают между ядрами. Контейнер не стартует — что не так с правами, неймспейсами или томами. Открытый файл сожрал дескриптор — а почему дескриптор кончился. На все эти вопросы нельзя ответить, не зная, как устроена операционная система под капотом.
Дальше — карта основных подсистем ОС. Что такое ядро и user space. Как процессы и потоки делят процессор. Как устроена виртуальная память. Как файлы превращаются в байты на диске. И что происходит между приложением и железом каждый раз, когда вы вызываете open() или read().
Тем, кто разворачивает приложения и работает с серверами, пригодятся DevOps-практики и работа с Shell и командной строкой.
Операционная система — что это вообще
Операционная система — это слой между железом компьютера и приложениями, которые на нём работают. У неё четыре главные роли:
Роль | Что значит на практике |
|---|---|
Распределяет ресурсы | Решает, какому процессу когда дать процессор, сколько ОЗУ, какой доступ к диску |
Абстрагирует железо | Приложение пишет в файл, не зная, на SSD это или HDD, ext4 или NTFS. ОС скрывает детали |
Изолирует процессы | Один процесс не может читать память другого. Один сломавшийся сервис не валит остальные |
Даёт единый интерфейс | Любая программа использует одни и те же системные вызовы. open(), read(), fork() — везде |
Главная архитектурная идея — разделение на два режима работы процессора. Приложения работают в user space (пользовательский режим): они могут делать только то, что разрешено. Ядро ОС работает в kernel space (привилегированный режим): оно может всё. Когда приложению нужно сделать что-то, требующее привилегий — записать в файл, выделить память, открыть сетевое соединение — оно просит об этом ядро через системный вызов.
Эта граница — фундамент безопасности. Без неё любая программа могла бы прочитать пароли другой, испортить файловую систему или отключить мышь у соседа.
Зачем разработчику знать, как устроена ОС
Если вы пишете обычный продуктовый код на высокоуровневом языке — Python, JavaScript, Java — большую часть времени можно не думать про ОС вообще. Язык и его рантайм прячут детали. Но в трёх ситуациях знание начинает окупаться многократно.
Отладка проблем в проде. Сервис вешается, и в нём не воспроизводится локально. Понимание того, что такое процесс, дескриптор, page fault, помогает читать логи и метрики системного уровня — а не только логи приложения.
Производительность. Где время уходит у вашего кода: в CPU, в ожидании диска, в сетевом стеке, в свопе? Без понимания ОС эти вопросы не задашь, не то что ответить.
Работа с инфраструктурой. Docker, Kubernetes, systemd — это всё надстройки над механизмами ОС. Когда контейнер не стартует или работает странно, копать обычно нужно в неймспейсы, cgroups и права. Без основ это магия.
Плюс на собеседованиях вопросы про устройство ОС — стабильная классика для среднего и сеньорного уровня. «Что происходит, когда вы вызываете fork()» — почти ритуальный вопрос.
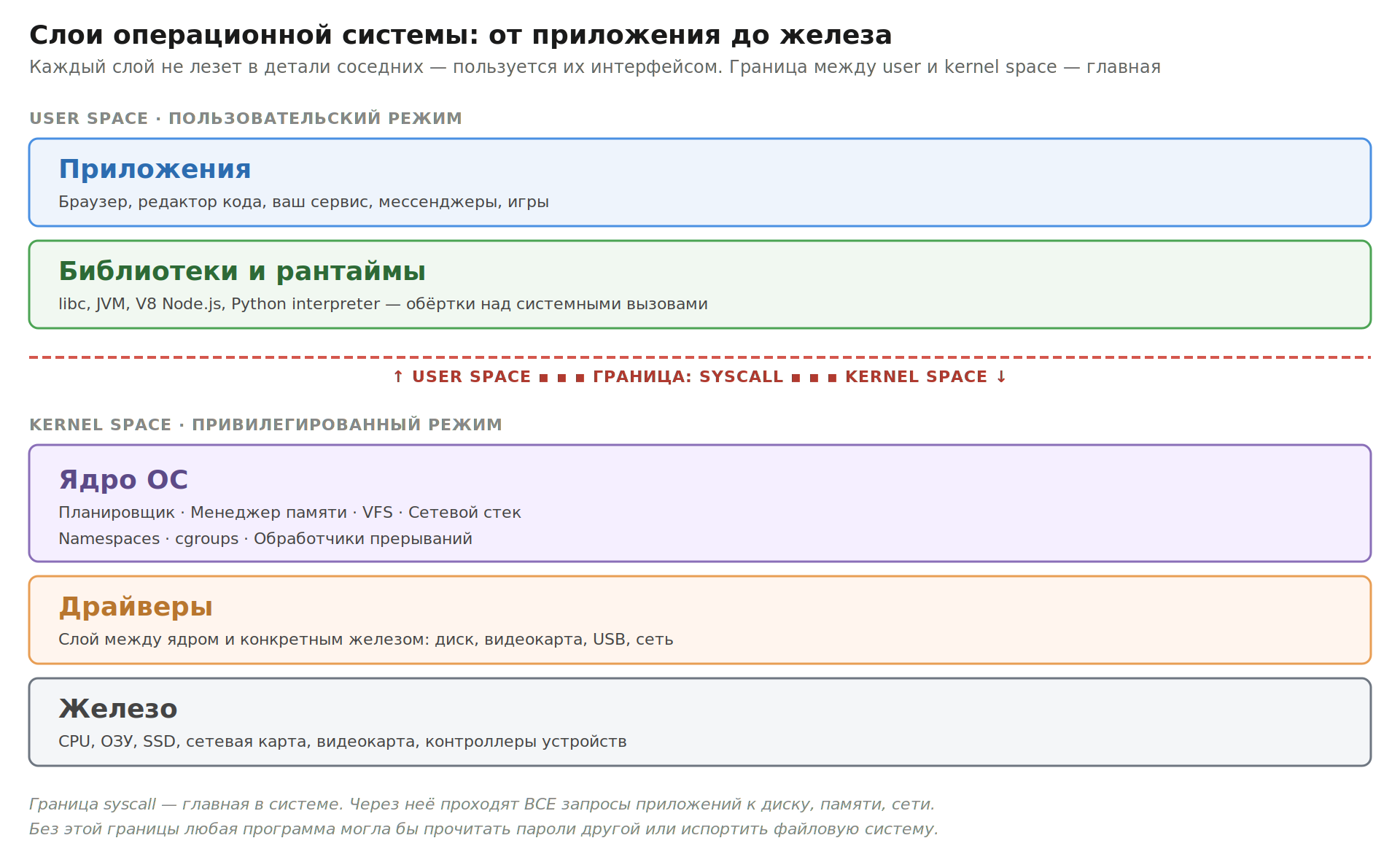
Слои: от приложения до железа
Удобно представлять систему как стопку слоёв. Каждый верхний слой не лезет в детали нижнего — пользуется его интерфейсом.
Слой | Кто здесь | Примеры |
|---|---|---|
Приложения | Программы, которые вы запускаете | Браузер, редактор кода, ваш сервис |
Библиотеки и рантаймы | Обёртки над системными вызовами, готовые функции | libc (printf, malloc), JVM, V8, Python interpreter |
Системные вызовы | Граница между user space и ядром | open, read, write, fork, mmap, socket |
Ядро ОС | Код в привилегированном режиме | Планировщик, менеджер памяти, сетевой стек |
Драйверы | Слой между ядром и конкретным железом | Драйвер диска, видеокарты, USB |
Железо | Физические устройства | CPU, ОЗУ, SSD, сетевая карта |
Приложение никогда не лезет «напрямую» к диску. Когда вы вызываете open("file.txt") в Python, происходит длинная цепочка: Python вызывает функцию из libc, libc делает системный вызов, ядро принимает запрос, проверяет права доступа, находит файл через файловую систему, обращается к драйверу диска, диск читает блоки, данные идут обратно по цепочке. Каждый шаг — слой. Каждый слой не знает деталей соседних, только их интерфейс.
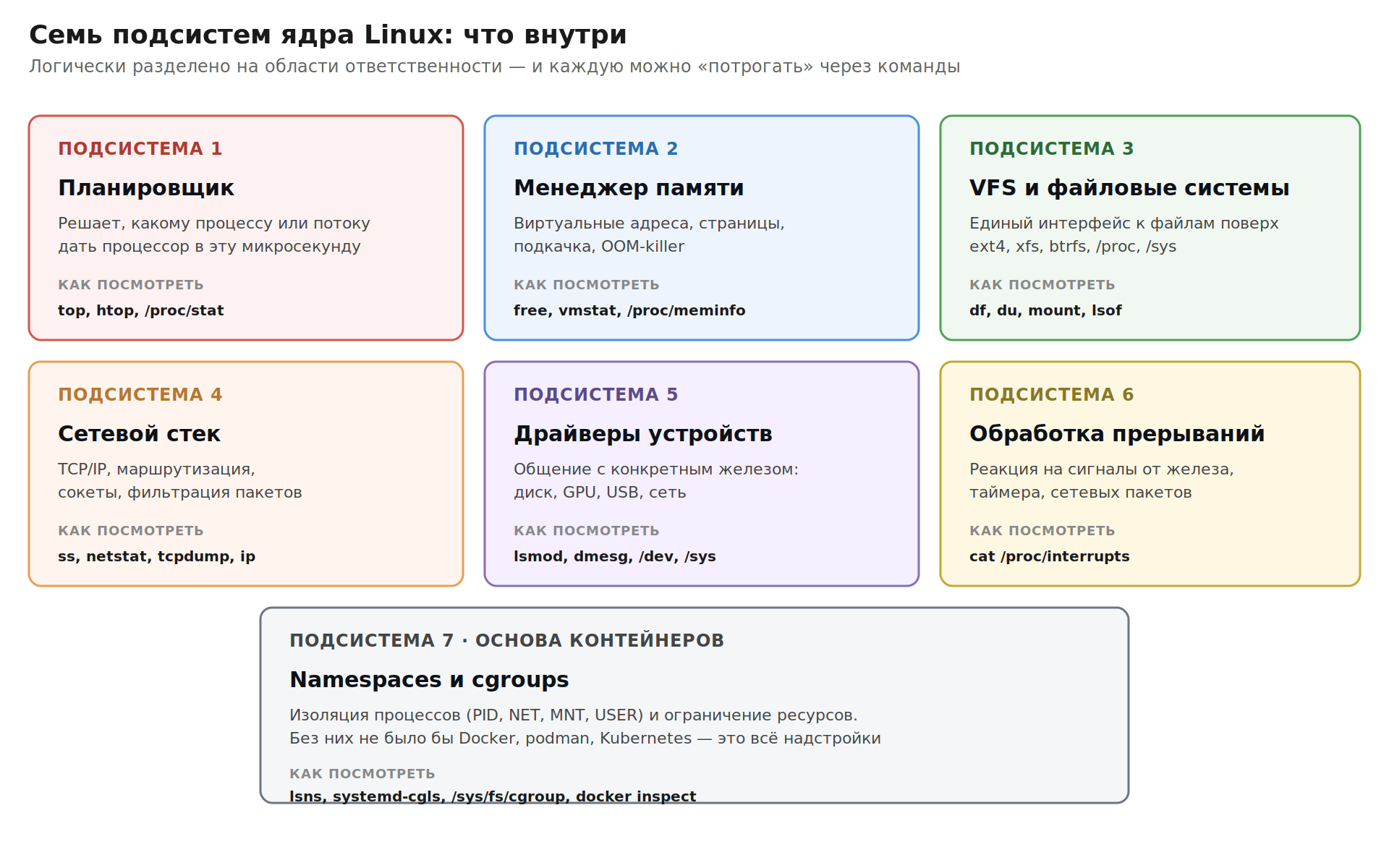
Ядро: что внутри
Ядро — это центр операционной системы. В Linux код ядра — около 30 миллионов строк на 2026 год. Это очень много. Но логически всё разделено на несколько подсистем, и каждая отвечает за свою область.
Подсистема | Чем занимается | Что видит разработчик |
|---|---|---|
Планировщик | Решает, какому процессу или потоку дать процессор | top, htop, нагрузка CPU, переключение контекста |
Менеджер памяти | Распределяет ОЗУ, ведёт виртуальные адреса, делает подкачку | free, vmstat, swap, OOM-killer |
VFS и файловые системы | Даёт единый интерфейс к файлам поверх разных ФС | open(), read(), df, du, /proc |
Сетевой стек | Реализует TCP/IP, маршрутизацию, сокеты | netstat, ss, tcpdump, iptables |
Драйверы | Общение с конкретным железом | lsmod, dmesg, /dev |
Обработка прерываний | Реакция на сигналы от железа и таймера | cat /proc/interrupts |
Namespaces и cgroups | Изоляция и ограничение ресурсов (основа контейнеров) | Docker, podman, kubelet |
Все эти подсистемы живут в одном адресном пространстве ядра и могут вызывать друг друга напрямую. В Linux это называется монолитное ядро. Альтернативные подходы — микроядро (большая часть в user space) и гибриды — разберём ниже.
Процессы и потоки: как ОС делит процессор
Процесс — это запущенная программа со своим адресным пространством, открытыми файлами, переменными окружения, правами доступа. Это контейнер для исполнения. Поток — это поток исполнения внутри процесса. У потоков одного процесса общая память и общие файлы, но свои регистры процессора, свой стек и своя позиция в коде.
В одну секунду процессор может выполнять только то, что физически помещается в его ядра. Если у вас 8 ядер, одновременно реально работают 8 потоков. Но процессов в системе обычно сотни, потоков — тысячи. Создаётся иллюзия одновременной работы за счёт того, что ОС постоянно переключает процессор между потоками — несколько сотен раз в секунду.
Это переключение называется context switch. Стоит оно недёшево.
Операция | Сколько занимает (порядок) |
|---|---|
Вызов функции в том же процессе | 1–2 наносекунды |
Системный вызов (без переключения) | 50–100 наносекунд |
Переключение между потоками одного процесса | ~1 микросекунда |
Переключение между процессами | 1–10 микросекунд |
Переключение с инвалидацией кэша | до 100 микросекунд |
Поэтому если ваш сервис создаёт сотни тысяч потоков «на всякий случай», большую часть процессорного времени система будет тратить на переключения, а не на полезную работу. Это одна из причин, почему async-модель (один поток обрабатывает много задач кооперативно) часто эффективнее, чем «один поток на одно соединение».
Жизненный цикл процесса в упрощённом виде такой: создан → ожидает процессор → выполняется → блокируется на I/O → ждёт окончания I/O → снова ожидает процессор → завершён. ОС постоянно следит за этими переходами и принимает решения, кого пускать на ядро следующим.
Виртуальная память: зачем и как
Самая красивая абстракция в современных ОС. Каждый процесс думает, что он один на машине и у него своё непрерывное адресное пространство — от нуля до огромного числа (на 64-битной системе виртуально доступно 256 ТБ). Никакого другого процесса с его точки зрения не существует.
На самом деле физической ОЗУ — гигабайты, и она делится между сотнями процессов. Магию делает MMU — Memory Management Unit, аппаратный модуль внутри процессора, и таблицы страниц, которые ведёт ядро.
Память разбита на страницы по 4 КБ (это типовой размер, бывают и больше). Каждая виртуальная страница процесса либо:
Привязана к физическому кадру в ОЗУ — это самый частый случай для активной памяти
Помечена «не загружена» — данные на диске в swap. При обращении сработает page fault, и ядро загрузит страницу в ОЗУ
Помечена «не выделена» — обращение приведёт к segmentation fault и краху процесса
Разделена с другим процессом — например, общая библиотека libc загружается один раз и виртуально мапится в адреса всех процессов, которые её используют
Что это даёт разработчику. Во-первых, изоляцию: процесс не может прочитать память другого случайно или специально — у него их адресов просто нет в его таблице страниц. Во-вторых, экономию: общие библиотеки в физической ОЗУ хранятся один раз. В-третьих, возможность использовать больше памяти, чем установлено физически — за счёт swap.
Минус один, но большой: когда swap начинает работать активно, всё тормозит в тысячи раз. Подробнее про иерархию памяти и почему swap такой медленный — в отдельной статье про ОЗУ и кэш.
Файловая система: как файлы лежат на диске
На уровне железа диск — это последовательность блоков по 512 байт или 4 КБ. Никаких файлов и папок на этом уровне нет. Файлы и каталоги — это абстракция, которую создаёт файловая система.
В Unix-подобных системах главная сущность — inode. Это структура с метаданными файла:
Тип файла (обычный файл, директория, символьная ссылка, устройство)
Размер
Права доступа (rwx для владельца, группы, остальных)
Владелец и группа
Времена создания, изменения, последнего доступа
Указатели на блоки данных на диске
Имени файла в inode нет. Имя — это связь, которая хранится в директории. Сама директория — это тоже файл, который содержит список пар «имя → номер inode». Когда вы делаете ls /home/user, ОС читает inode директории user, видит список имён с привязкой к inode и отображает их.
Из этого следуют интересные практические следствия:
Что происходит | Почему |
|---|---|
Можно создать жёсткую ссылку — один inode, два имени | В разных директориях разные записи могут указывать на один inode |
| Меняется запись в директории, физические блоки не двигаются |
| На другой ФС другие inode, нужно физически переписать |
Удаление открытого файла не освобождает место сразу | Пока есть открытый дескриптор, ядро не трогает inode и блоки |
«Файл закончился, диск полный» бывает при наличии места | Закончились свободные inode — отдельный ресурс |
Над конкретными файловыми системами (ext4, xfs, btrfs, NTFS, APFS) ядро держит обобщающий слой — VFS, Virtual File System. Это интерфейс «как файл», который выглядит одинаково для приложений, независимо от того, какая ФС лежит под капотом. Поэтому ваш Python-код работает одинаково на Linux с ext4 и на macOS с APFS.
Системные вызовы: как приложение разговаривает с ядром
Это самая интересная граница в ОС. Приложение работает в user space и физически не может само переключить процессор в режим ядра. Для этого есть специальная инструкция процессора — на x86_64 это syscall.
Что происходит шаг за шагом, когда Python делает open("file.txt"):
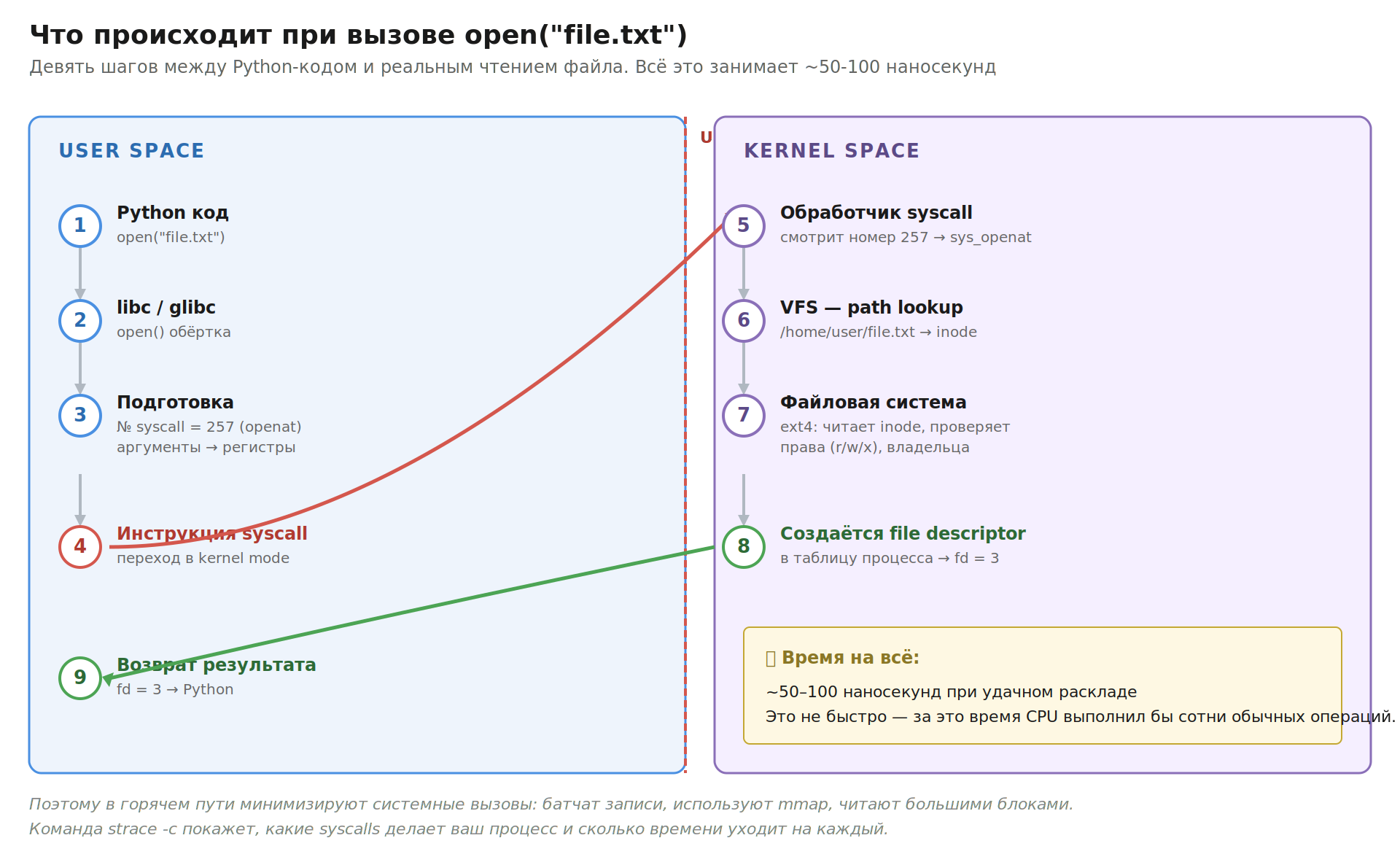
Python вызывает функцию из
libclibc кладёт номер системного вызова (для
openatв Linux это 257) и аргументы в регистры процессораlibc выполняет инструкцию
syscallПроцессор переключается в kernel mode и прыгает на специально подготовленный обработчик
Обработчик смотрит номер вызова, находит нужную функцию ядра и вызывает её
Функция ядра делает свою работу: проверяет права, ищет файл через VFS, создаёт дескриптор
Результат записывается в регистр
Процессор возвращается в user mode
libc забирает результат из регистра и возвращает его Python
На современных процессорах вся эта церемония занимает около 50–100 наносекунд при удачном раскладе. Это не быстро — за это время процессор успел бы выполнить несколько сотен обычных операций. Поэтому в высокопроизводительных приложениях стараются минимизировать число системных вызовов: батчат записи, используют memory-mapped файлы, читают сразу большими блоками.
Посмотреть, какие системные вызовы делает ваш процесс, можно командой strace на Linux:
strace -c python my_script.py
# покажет таблицу: какие syscalls, сколько раз, сколько времени
Часто это первое, что делают при диагностике зависшего процесса — становится видно, на каком системном вызове он залип.
Что происходит, когда вы запускаете программу
Разберём по шагам, что происходит между нажатием Enter в терминале и моментом, когда программа начинает выполняться.
Shell получает команду. Например, вы написали
./myapp arg1 arg2Shell вызывает fork(). Создаётся точная копия текущего процесса shell — со всем содержимым памяти, открытыми файлами и переменными окружения
В дочернем процессе вызывается exec(). Это волшебный системный вызов: он не создаёт новый процесс, а заменяет содержимое текущего на содержимое указанного исполняемого файла
Ядро читает заголовок исполняемого файла. На Linux это формат ELF. В заголовке — точка входа, сегменты кода и данных, какие динамические библиотеки нужны
Ядро создаёт виртуальное адресное пространство. Раскладывает по нему сегменты программы: код, данные, кучу, стек
Загружаются динамические библиотеки. libc, libssl, всё что нужно — через mmap. Чаще всего это уже загруженные в ОЗУ страницы, которые мапятся виртуально
Управление передаётся в точку входа. Обычно это
_startв crt0, который потом вызывает вашmain()Программа начинает выполняться. Планировщик ставит её в очередь готовых процессов, она получает квант времени, потом следующий и так далее
Самое контринтуитивное в этой схеме — fork + exec. На первый взгляд расточительно: сначала копируем процесс, потом сразу заменяем его содержимое. Почему не сделать одну атомарную операцию «создать новый процесс из этого файла»?
Историческая причина — гибкость. Между fork и exec в дочернем процессе можно сделать что-то: перенаправить stdin/stdout, изменить переменные окружения, сменить рабочую директорию, изменить права. Именно поэтому shell умеет делать ./myapp > output.txt или ./myapp & — между fork и exec он перенастраивает дескрипторы и группу процессов. А чтобы fork не был дорогим, ОС использует copy-on-write: память не копируется физически, пока кто-то не начал писать в неё.
Контейнеры: namespaces и cgroups
Раз уж говорим про современную ОС в 2026 году — нельзя пройти мимо контейнеров. Когда вы запускаете Docker-контейнер, никакой «маленькой виртуальной машины» не появляется. Появляется обычный процесс Linux с парой надстроек.
Первая надстройка — namespaces (пространства имён). Это механизм ядра, который даёт процессу видеть свою «версию» системных ресурсов. Существуют разные виды namespaces:
Namespace | Что изолирует |
|---|---|
PID | Список процессов. Внутри контейнера вы видите только свои процессы, и они начинаются с PID 1 |
NET | Сетевые интерфейсы. Контейнер имеет свой стек, IP-адреса, маршруты |
MNT | Точки монтирования. Контейнер видит только свою файловую систему |
UTS | Имя хоста и домена |
IPC | Межпроцессное взаимодействие (очереди сообщений, семафоры) |
USER | UID и GID. Можно быть root внутри контейнера и обычным пользователем снаружи |
Вторая надстройка — cgroups (control groups). Это механизм ограничения ресурсов. Вы можете сказать ядру: «этой группе процессов давай не больше 50% CPU и не больше 2 ГБ памяти». Ядро будет следить и убивать процессы, если они превысят лимиты.
Когда вы запускаете docker run -m 2G --cpus=1 nginx, Docker под капотом создаёт неймспейсы, создаёт cgroup с лимитами и запускает процесс nginx внутри этой комбинации. Никакой виртуализации нет. Это просто процесс Linux с другим взглядом на мир.
Понимание этих основ — ключ к нормальной работе с любым оркестратором: Docker, podman, Kubernetes, systemd. Подробнее про экосистему вокруг — в материале про DevOps простыми словами.
Виды ядер: монолит, микроядро, гибриды
Три подхода к архитектуре ядра. Каждый со своими компромиссами.
Тип | Что в ядре | Плюсы | Минусы | Примеры |
|---|---|---|---|---|
Монолитное | Почти всё: планировщик, ФС, драйверы, сеть | Быстро — вызовы между подсистемами по указателю функции | Сбой в драйвере роняет всё ядро. Код большой и сложный | Linux, BSD |
Микроядро | Только базовое: планирование, IPC, базовая память | Изоляция — сбой драйвера не валит систему | Медленнее — много IPC между сервисами | QNX, Minix, L4 |
Гибридное | Базовое плюс самое нагруженное (драйверы, графика) | Компромисс между скоростью и надёжностью | Сложнее проектировать и поддерживать | Windows NT, macOS XNU |
На практике почти все массовые ОС сегодня — это либо монолит с модулями (Linux), либо гибрид (Windows, macOS). Чистые микроядра живут в очень специфических нишах: системы реального времени, медицинская техника, автомобильные системы, где надёжность важнее скорости.
FAQ
Чем процесс отличается от потока?
Процесс — это контейнер с собственным адресным пространством, открытыми файлами и правами. Поток — единица исполнения внутри процесса. У потоков одного процесса общая память, общие файлы, но свои регистры процессора, свой стек и своя позиция в коде. Создать поток дешевле, чем процесс, переключение между потоками — быстрее. Но потоки одного процесса не изолированы друг от друга: ошибка в одном может уронить весь процесс.
Что такое системный вызов и почему их нельзя избежать?
Системный вызов — это единственный способ для приложения попросить ядро сделать что-то привилегированное: открыть файл, выделить память, отправить пакет в сеть. Избежать их полностью невозможно: даже простой print("hello") в Python в итоге дойдёт до системного вызова write. Но можно минимизировать их количество в горячем пути: батчить операции, использовать memory-mapped файлы, делать асинхронный I/O.
Почему «Out of memory» убивает мой процесс, если в системе ещё есть свободная память?
Несколько возможных причин. Первая: cgroup-лимит, если вы в контейнере с ограничением памяти. Вторая: лимиты на конкретный процесс (ulimit). Третья: фрагментация — свободной памяти много, но нет непрерывного блока нужного размера. Четвёртая: OOM-killer срабатывает и когда память кончилась, и когда система стала свопить слишком активно. Команда dmesg | grep -i oom покажет, что именно произошло.
Почему Docker-контейнер легче виртуальной машины?
Потому что это не виртуальная машина. Виртуалка эмулирует железо и запускает на нём отдельную операционную систему — со своим ядром, со своей памятью. Контейнер — это просто процесс Linux на том же ядре, что и хост, с изоляцией через namespaces и ограничениями через cgroups. Не нужно загружать ядро гостевой ОС, не нужны накладные расходы на эмуляцию железа. Отсюда мгновенный старт и низкое потребление ресурсов.
Что значит, что Linux — это монолитное ядро с модулями?
Что почти весь код ОС работает в одном адресном пространстве ядра, но отдельные его части (драйверы, файловые системы, сетевые протоколы) можно подключать и отключать без перезагрузки. Команда lsmod покажет список загруженных модулей. Это даёт гибкость монолита — поддерживается огромная номенклатура железа без перекомпиляции ядра.
Можно ли написать свою операционную систему?
Можно, и многие пишут как учебный проект. Минимальная ОС, которая загружается и печатает «Hello World» — это пара тысяч строк ассемблера и C. Полноценная ОС уровня хотя бы базовой Unix-системы — это годы работы. Современная ОС с поддержкой сетей, графики и реального железа — это десятки человеко-лет. Linux пишет сообщество с 1991 года, и работа идёт до сих пор.
Какую ОС учить разработчику в 2026 году?
Linux — обязательно, потому что почти все серверы и контейнеры в продакшене работают на нём. macOS — полезно знать, если работаете на Mac (там Unix-подобное ядро, но детали отличаются). Windows — если работаете с .NET, играми, корпоративным ПО. Для понимания основ — Linux лучше всех: документация открытая, исходники доступны, в любой непонятной ситуации можно посмотреть, как оно устроено внутри.